Reshaping MOFs text mining with a dynamic multi-agents framework of large language model
作者: Zuhong Lin, Daoyuan Ren, Kai Ran, Jing Sun, Songlin Yu, Xuefeng Bai, Xiaotian Huang, Haiyang He, Pengxu Pan, Ying Fang, Zhanglin Li, Haipu Li, Jingjing Yao
分类: cs.AI, cond-mat.mtrl-sci
发布日期: 2025-04-26 (更新: 2025-08-08)
💡 一句话要点
MOFh6:利用大语言模型动态多智能体框架重塑MOFs文本挖掘
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金属有机框架 文本挖掘 大语言模型 信息提取 材料合成
📋 核心要点
- 现有MOFs合成条件识别方法面临文献信息分散、不一致和难以解释的挑战。
- MOFh6利用大语言模型,将原始文章或晶体代码转换为标准化的合成表格。
- MOFh6在提取准确率、缩写解决和处理速度上均表现出色,成本效益显著。
📝 摘要(中文)
准确识别金属有机框架(MOFs)的合成条件对于指导实验设计至关重要,但由于文献中的相关信息分散、不一致且难以解释,因此仍然具有挑战性。我们提出了MOFh6,这是一个由大型语言模型驱动的系统,可以读取原始文章或晶体代码,并将其转换为标准化的合成表格。它可以链接段落中的相关描述,将配体缩写与全名统一,并输出可直接使用的结构化参数。MOFh6实现了99%的提取准确率,解决了五个主要出版商中94.1%的缩写情况,并保持了0.93 +/- 0.01的精度。处理全文需要9.6秒,定位合成描述需要36秒,处理100篇论文的成本为4.24美元。通过用实时提取代替静态数据库查找,MOFh6重塑了MOF合成研究,加速了文献知识向实际合成方案的转化,并实现了可扩展的、数据驱动的材料发现。
🔬 方法详解
问题定义:论文旨在解决从科学文献中准确提取金属有机框架(MOFs)合成条件信息的难题。现有方法依赖于静态数据库查找,无法处理文献中信息分散、描述不一致以及配体缩写等问题,导致实验设计效率低下,阻碍了数据驱动的材料发现。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大自然语言处理能力,构建一个动态多智能体框架,实现对MOFs合成文献的实时提取和结构化。通过LLM的理解和推理能力,克服现有方法对静态数据库的依赖,从而更准确、更高效地提取合成信息。
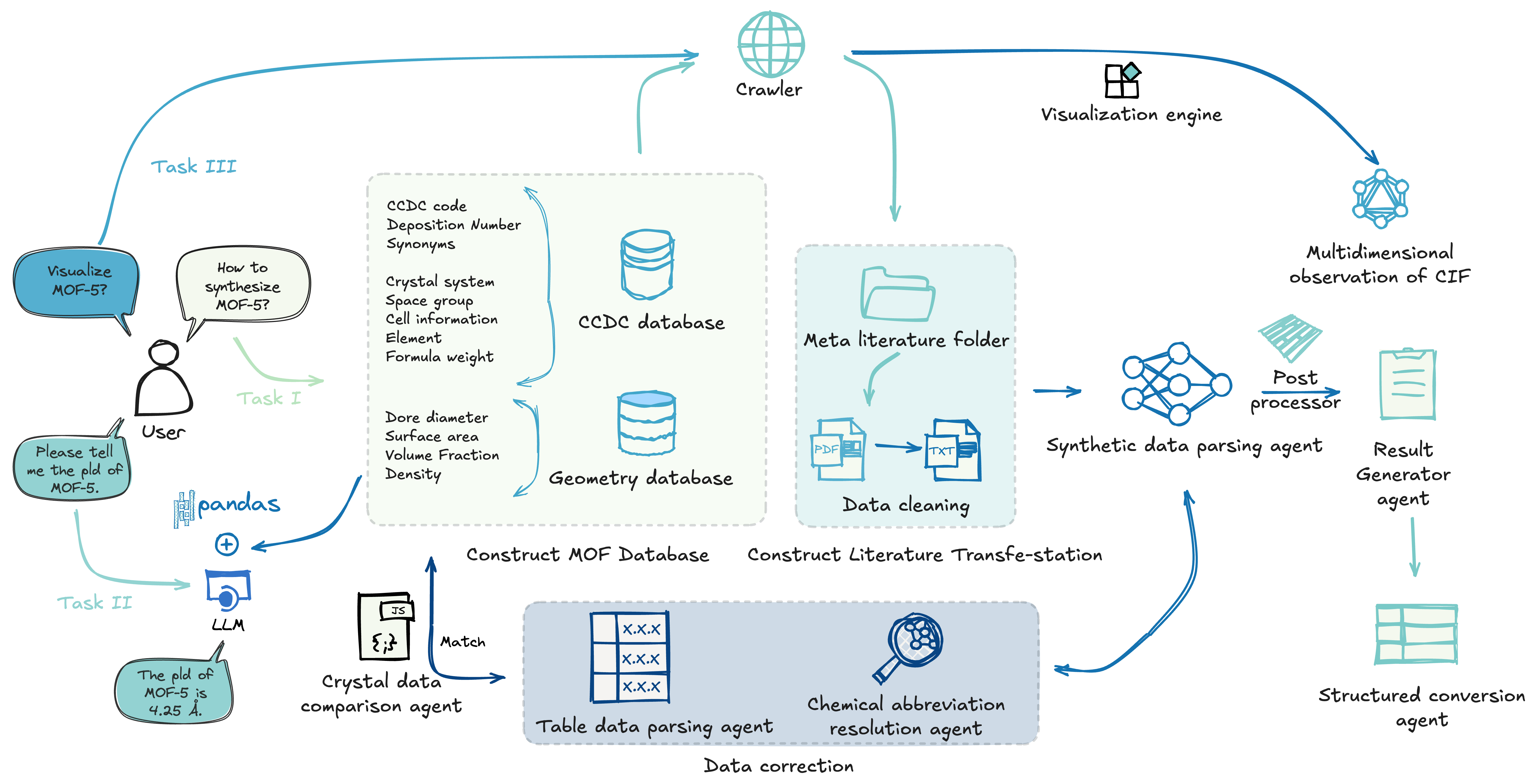
技术框架:MOFh6系统主要包含以下模块:1) 文献读取模块,负责读取原始文章或晶体代码;2) 描述链接模块,用于链接段落中的相关描述,整合分散的信息;3) 缩写统一模块,将配体缩写与全名统一,消除歧义;4) 参数结构化模块,将提取的信息转换为可直接使用的结构化参数;5) 输出模块,生成标准化的合成表格。整个流程由LLM驱动,实现对文献信息的智能处理。
关键创新:MOFh6的关键创新在于使用LLM进行实时信息提取,取代了传统的静态数据库查找方法。这种方法能够动态地理解和处理文献中的复杂信息,从而提高了提取的准确性和效率。此外,动态多智能体框架的设计也增强了系统的鲁棒性和可扩展性。
关键设计:论文中没有详细描述LLM的具体参数设置、损失函数或网络结构。但是,强调了LLM在理解上下文、解决缩写歧义和结构化信息方面的作用。系统采用多智能体协同工作的方式,每个智能体负责不同的任务,例如信息提取、缩写解析等。这种设计提高了系统的并行处理能力和整体性能。
🖼️ 关键图片

📊 实验亮点
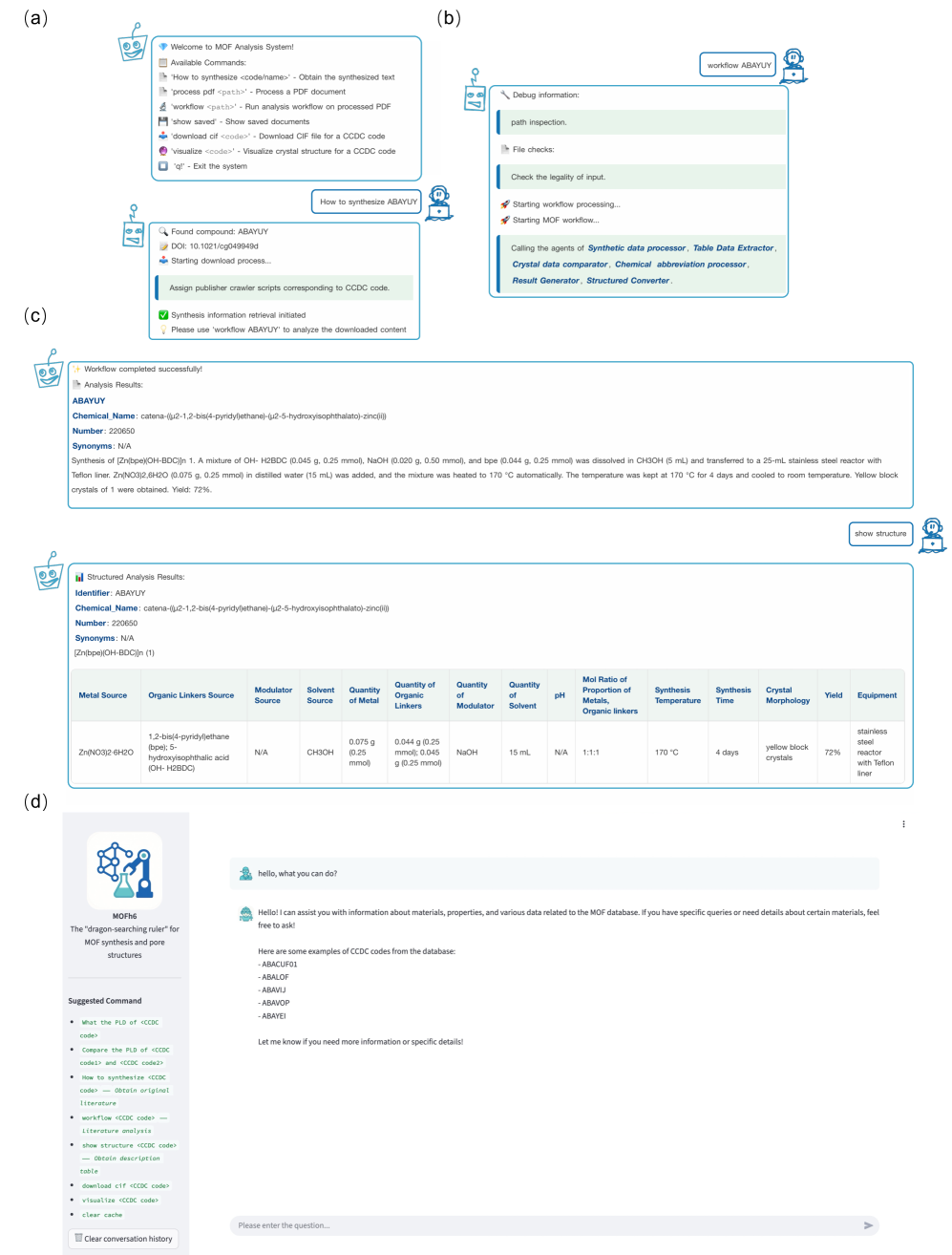
MOFh6在MOFs合成信息提取方面表现出色,实现了99%的提取准确率,解决了五个主要出版商中94.1%的缩写情况,并保持了0.93 +/- 0.01的精度。处理一篇全文仅需9.6秒,定位合成描述仅需36秒,处理100篇论文的成本仅为4.24美元,表明该系统具有高效性和经济性。
🎯 应用场景
MOFh6可应用于材料科学、化学工程等领域,加速金属有机框架材料的合成研究和数据驱动的材料发现。通过自动化提取文献中的合成信息,研究人员可以更高效地设计实验方案,优化合成条件,并构建大规模的MOFs合成数据库,为新材料的开发提供有力支持。
📄 摘要(原文)
Accurately identifying the synthesis conditions of metal-organic frameworks (MOFs) is essential for guiding experimental design, yet remains challenging because relevant information in the literature is often scattered, inconsistent, and difficult to interpret. We present MOFh6, a large language model driven system that reads raw articles or crystal codes and converts them into standardized synthesis tables. It links related descriptions across paragraphs, unifies ligand abbreviations with full names, and outputs structured parameters ready for use. MOFh6 achieved 99% extraction accuracy, resolved 94.1% of abbreviation cases across five major publishers, and maintained a precision of 0.93 +/- 0.01. Processing a full text takes 9.6 s, locating synthesis descriptions 36 s, with 100 papers processed for USD 4.24. By replacing static database lookups with real-time extraction, MOFh6 reshapes MOF synthesis research, accelerating the conversion of literature knowledge into practical synthesis protocols and enabling scalable, data-driven materials discovery.