Hierarchical Reinforcement Learning in Multi-Goal Spatial Navigation with Autonomous Mobile Robots
作者: Brendon Johnson, Alfredo Weitzenfeld
分类: cs.AI, cs.RO
发布日期: 2025-04-26 (更新: 2025-08-18)
💡 一句话要点
提出基于分层强化学习的自主移动机器人多目标空间导航方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 多目标导航 自主移动机器人 近端策略优化 子目标创建
📋 核心要点
- 传统强化学习在复杂机器人导航任务中面临挑战,难以有效利用任务的内在层次结构。
- 论文提出使用分层强化学习,通过创建子目标和终止函数来分解任务,从而提升学习效率。
- 实验对比了HRL与PPO在导航任务中的性能,并分析了子目标创建方式和终止频率对HRL效果的影响。
📝 摘要(中文)
本研究评估了分层强化学习(HRL)在复杂机器人导航任务中的性能,并将其与传统强化学习(RL)进行了对比。HRL被认为能够利用学习任务中固有的层次结构,而传统RL通常难以胜任。我们评估了HRL的独特特性,包括其创建子目标和终止函数的能力。我们构建了一系列实验来测试:1) RL近端策略优化(PPO)和HRL之间的差异,2) HRL中创建子目标的不同方法,3) HRL中手动与自动子目标创建的对比,以及4)终止频率对HRL性能的影响。这些实验突出了HRL相对于RL的优势以及它如何实现这些优势。
🔬 方法详解
问题定义:论文旨在解决自主移动机器人在复杂空间环境中进行多目标导航的问题。传统强化学习方法在处理此类任务时,由于状态空间庞大、奖励稀疏等原因,往往难以收敛或效率低下。现有的强化学习方法难以有效利用任务中固有的层次结构,导致学习过程缓慢且不稳定。
核心思路:论文的核心思路是利用分层强化学习(HRL)将复杂的导航任务分解为多个子任务,每个子任务对应一个子目标。通过学习子目标策略,机器人可以逐步完成整个导航任务。HRL能够更好地利用任务的层次结构,从而提高学习效率和泛化能力。
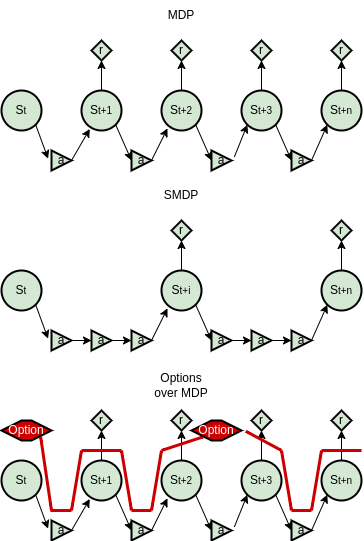
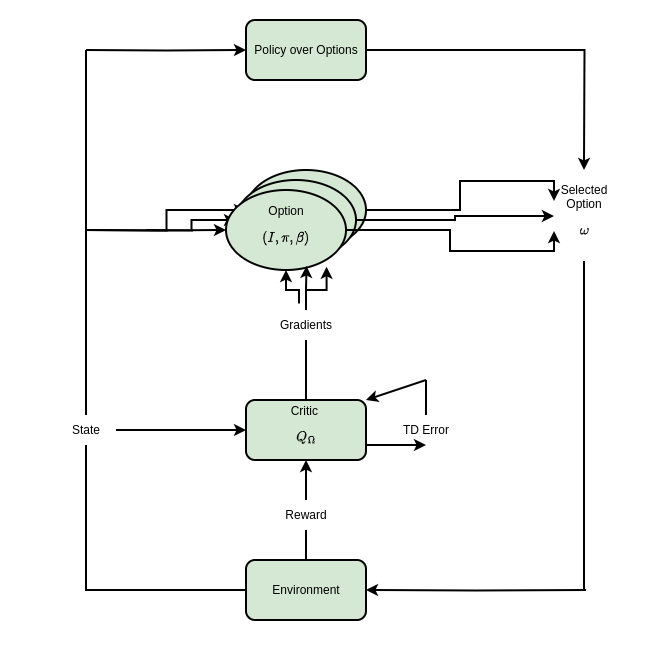
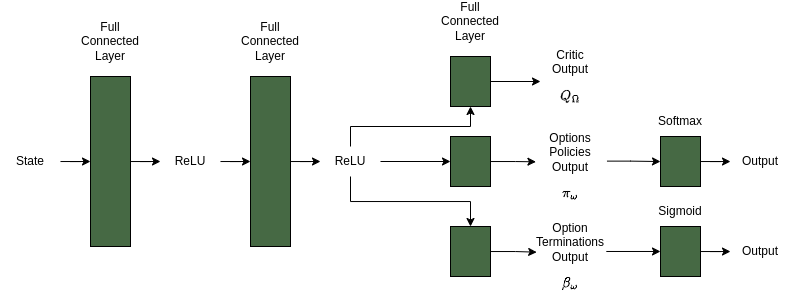
技术框架:整体框架包含两个层级:高层策略(Manager)和低层策略(Worker)。Manager负责选择子目标,Worker负责执行到达子目标的动作。当Worker到达子目标或满足终止条件时,Manager会选择下一个子目标。整个学习过程通过强化学习算法(如PPO)进行训练,Manager和Worker可以同时或交替进行学习。
关键创新:论文的关键创新在于探索了不同的子目标创建方法(手动 vs 自动)以及终止频率对HRL性能的影响。通过实验分析,论文揭示了HRL在复杂导航任务中的优势,并为HRL的参数选择和策略设计提供了指导。此外,论文还对比了HRL与传统RL方法(PPO)的性能差异,验证了HRL的有效性。
关键设计:论文中,子目标的创建方式包括手动指定和自动生成两种。手动指定需要人工设计子目标,而自动生成则可以通过聚类等算法自动发现有意义的子目标。终止频率是指Worker执行多少步后,Manager重新选择子目标。论文研究了不同终止频率对HRL性能的影响,并发现合适的终止频率可以提高学习效率和稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HRL在多目标导航任务中优于传统RL方法(PPO)。HRL能够更快地收敛,并达到更高的导航成功率。此外,实验还发现,合适的子目标创建方法和终止频率对HRL的性能至关重要。自动生成的子目标在某些情况下可以取得与手动指定子目标相当甚至更好的效果。
🎯 应用场景
该研究成果可应用于仓储物流、家庭服务、自动驾驶等领域,提升机器人在复杂环境中的自主导航能力。通过分层强化学习,机器人可以更好地理解和执行复杂的任务,从而提高工作效率和服务质量。未来,该技术有望应用于更广泛的机器人应用场景,例如灾难救援、环境监测等。
📄 摘要(原文)
Hierarchical reinforcement learning (HRL) is hypothesized to be able to leverage the inherent hierarchy in learning tasks where traditional reinforcement learning (RL) often fails. In this research, HRL is evaluated and contrasted with traditional RL in complex robotic navigation tasks. We evaluate unique characteristics of HRL, including its ability to create sub-goals and the termination functions. We constructed a number of experiments to test: 1) the differences between RL proximal policy optimization (PPO) and HRL, 2) different ways of creating sub-goals in HRL, 3) manual vs automatic sub-goal creation in HRL, and 4) the effects of the frequency of termination on performance in HRL. These experiments highlight the advantages of HRL over RL and how it achieves these advantages.