Exploring a Large Language Model for Transforming Taxonomic Data into OWL: Lessons Learned and Implications for Ontology Development
作者: Filipi Miranda Soares, Antonio Mauro Saraiva, Luís Ferreira Pires, Luiz Olavo Bonino da Silva Santos, Dilvan de Abreu Moreira, Fernando Elias Corrêa, Kelly Rosa Braghetto, Debora Pignatari Drucker, Alexandre Cláudio Botazzo Delbem
分类: cs.AI
发布日期: 2025-04-25
备注: 31 pages, 6 Figures, accepted for publication in Data Intelligence
期刊: 2025
DOI: 10.3724/2096-7004.di.2025.0020
💡 一句话要点
利用大型语言模型ChatGPT-4将分类数据转换为OWL本体,提升本体构建效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 本体构建 ChatGPT-4 OWL 物种分类
📋 核心要点
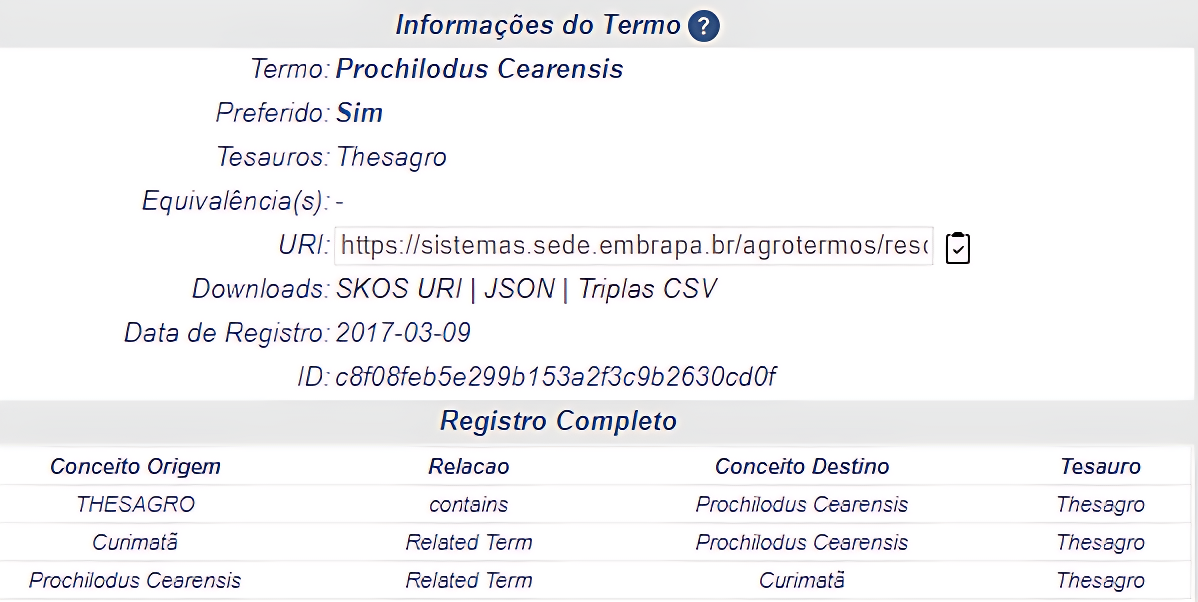
- 物种分类学不断发展,导致本体中科学名称的管理面临挑战,手动维护成本高昂。
- 利用ChatGPT-4从GBIF API提取数据并生成OWL文件,旨在自动化构建物种分类本体模块。
- 实验对比了基于插件和基于Python算法两种方法,验证了LLM在本体构建自动化方面的潜力。
📝 摘要(中文)
本文探讨了使用ChatGPT-4自动化构建农业产品类型本体(APTO)中用于物种分类的:Organism模块。由于物种分类的不断演变,在本体中管理科学名称极具挑战。研究采用ChatGPT-4从GBIF Backbone API提取数据并生成OWL文件,以集成到APTO中。探索了两种方法:(1)通过BrowserOP插件向ChatGPT-4发出提示以执行任务;(2)指示ChatGPT-4设计Python算法来执行类似任务。两种方法都依赖于提示方法,提供指令、上下文、输入数据和输出指示。第一种方法显示出可扩展性限制,而第二种方法使用Python算法克服了这些挑战,但在数据处理中存在印刷错误。研究强调了ChatGPT-4等大型语言模型在简化本体中物种名称管理方面的潜力,并在自动化分类相关任务和提高本体开发效率方面提供了有希望的进展。
🔬 方法详解
问题定义:论文旨在解决物种分类本体构建中,由于分类体系不断变化导致的手动维护工作量大、效率低下的问题。现有方法主要依赖人工维护,耗时耗力,难以应对大规模和快速变化的分类数据。
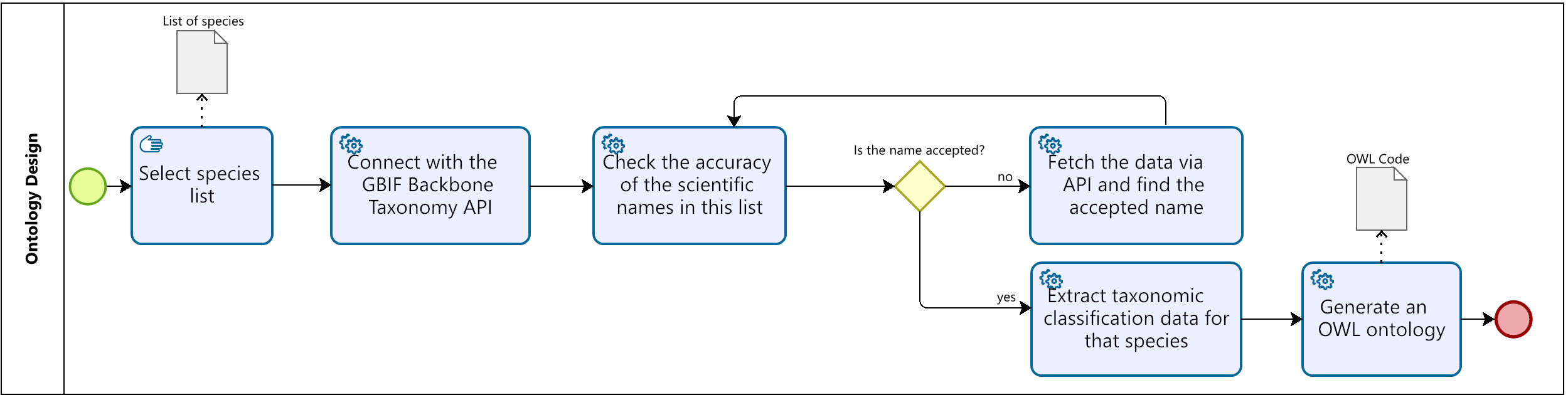
核心思路:论文的核心思路是利用大型语言模型(LLM)ChatGPT-4的自然语言处理和代码生成能力,自动化地从物种分类数据库(GBIF Backbone API)提取数据,并将其转换为OWL本体格式。通过提示工程,引导LLM理解任务需求并生成相应的代码或直接执行数据转换。
技术框架:整体流程包括:1) 数据源(GBIF Backbone API);2) LLM(ChatGPT-4);3) 两种实现方法:a) 基于BrowserOP插件的提示链;b) 基于Python算法生成的提示链;4) 输出:OWL本体文件。两种方法都采用提示工程,即通过提供指令、上下文、输入数据和输出指示来引导LLM完成任务。
关键创新:论文的关键创新在于探索了LLM在本体构建自动化方面的应用,并对比了两种不同的实现方式。与传统的手动构建或基于规则的自动化方法相比,LLM能够更好地理解自然语言描述的分类信息,并生成更灵活和可扩展的本体结构。
关键设计:两种方法的关键设计在于提示工程。对于BrowserOP插件方法,需要设计一系列的提示,引导ChatGPT-4逐步完成数据提取、转换和OWL文件生成。对于Python算法方法,需要设计提示,引导ChatGPT-4生成能够完成上述任务的Python代码。此外,还需要考虑如何处理数据中的错误和不一致性,以及如何优化生成的OWL文件的质量。
🖼️ 关键图片

📊 实验亮点
研究对比了两种基于ChatGPT-4的本体构建方法。基于BrowserOP插件的方法在处理大规模数据时存在可扩展性问题,而基于Python算法的方法虽然克服了可扩展性问题,但在数据处理中存在印刷错误。尽管存在局限性,但两种方法都验证了LLM在本体构建自动化方面的潜力。
🎯 应用场景
该研究成果可应用于生物多样性信息管理、农业知识图谱构建、生态环境监测等领域。通过自动化构建和维护物种分类本体,可以提高相关领域的数据质量和互操作性,促进跨领域知识共享和应用。未来,该方法可以扩展到其他领域的本体构建,例如医学、化学等。
📄 摘要(原文)
Managing scientific names in ontologies that represent species taxonomies is challenging due to the ever-evolving nature of these taxonomies. Manually maintaining these names becomes increasingly difficult when dealing with thousands of scientific names. To address this issue, this paper investigates the use of ChatGPT-4 to automate the development of the :Organism module in the Agricultural Product Types Ontology (APTO) for species classification. Our methodology involved leveraging ChatGPT-4 to extract data from the GBIF Backbone API and generate OWL files for further integration in APTO. Two alternative approaches were explored: (1) issuing a series of prompts for ChatGPT-4 to execute tasks via the BrowserOP plugin and (2) directing ChatGPT-4 to design a Python algorithm to perform analogous tasks. Both approaches rely on a prompting method where we provide instructions, context, input data, and an output indicator. The first approach showed scalability limitations, while the second approach used the Python algorithm to overcome these challenges, but it struggled with typographical errors in data handling. This study highlights the potential of Large language models like ChatGPT-4 to streamline the management of species names in ontologies. Despite certain limitations, these tools offer promising advancements in automating taxonomy-related tasks and improving the efficiency of ontology development.