Exploring Context-aware and LLM-driven Locomotion for Immersive Virtual Reality
作者: Süleyman Özdel, Kadir Burak Buldu, Enkelejda Kasneci, Efe Bozkir
分类: cs.HC, cs.AI
发布日期: 2025-04-24 (更新: 2026-01-11)
💡 一句话要点
提出基于上下文感知和LLM驱动的VR自然语言免手部移动方案
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 虚拟现实 自然语言处理 大型语言模型 免手部交互 眼动追踪 用户体验 可解释机器学习
📋 核心要点
- 传统语音控制VR移动依赖固定命令集,缺乏自然性和灵活性,限制了用户体验。
- 利用大型语言模型(LLM)的上下文理解能力,使用自然语言实现VR环境中的免手部移动。
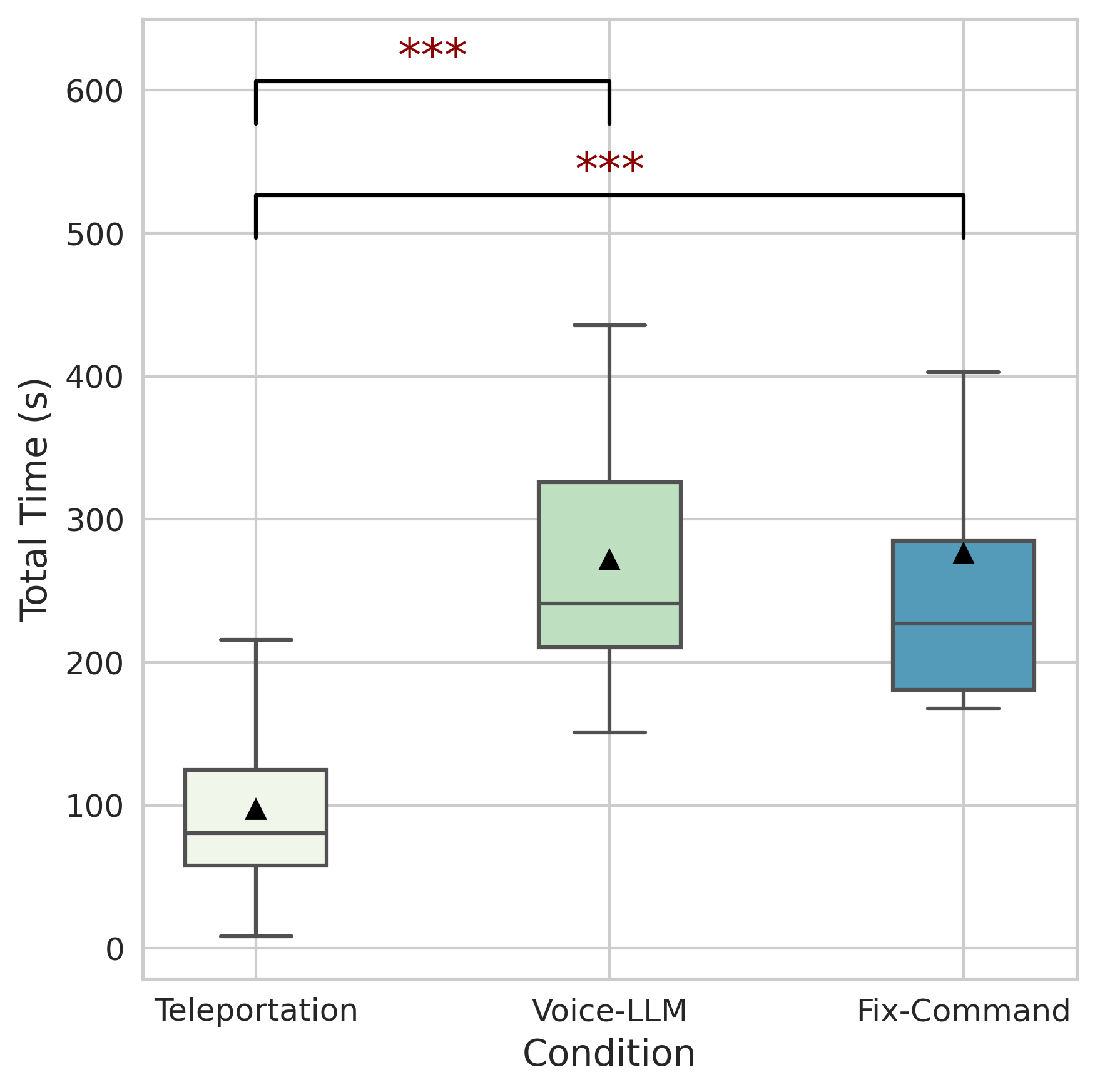
- 实验表明,该方法在可用性、临场感和晕动症方面与传统方法相当,并可能提高用户注意力和参与度。
📝 摘要(中文)
本文提出了一种由大型语言模型(LLM)驱动的新型虚拟现实(VR)移动技术,允许用户使用具有上下文感知能力的自然语言导航虚拟环境。该方法旨在提供一种免手部的替代方案,提高VR交互的自然性和灵活性。研究评估了三种移动方法:基于控制器的瞬移、基于语音的转向以及本文提出的基于LLM的方法。评估结合了眼动追踪数据分析(包括使用SHAP的可解释机器学习分析)和标准化问卷(SUS、IPQ、CSQ-VR、NASA-TLX),从可用性、临场感、晕动症和认知负荷等方面考察用户体验。结果表明,基于LLM的移动与瞬移等传统方法在可用性、临场感或晕动症方面没有显著差异,表明其作为一种可行的、基于自然语言的免手部替代方案的潜力。眼动追踪分析揭示了用户在使用LLM驱动的移动时,注意力和参与度可能更高的模式。SHAP分析表明,不同技术在注视、扫视和瞳孔相关特征方面存在差异,反映了不同的视觉注意和认知处理模式。该方法有助于在虚拟空间中实现免手部移动,尤其是在支持可访问性方面。
🔬 方法详解
问题定义:现有VR环境中的移动方式,特别是语音控制,通常依赖于预定义的命令集,这限制了交互的自然性和灵活性。用户需要记住特定的指令才能完成移动,这增加了认知负担,降低了沉浸感。因此,需要一种更自然、更灵活的免手部移动方案。
核心思路:本文的核心思路是利用大型语言模型(LLM)的自然语言理解和生成能力,使用户能够通过自然语言指令在VR环境中移动。LLM能够理解用户指令的意图和上下文,从而实现更灵活、更自然的交互。这种方法旨在消除对预定义命令的依赖,提高用户体验。
技术框架:该方法主要包含以下几个模块:1) 语音输入模块:负责接收用户的语音指令。2) 自然语言处理模块:使用LLM对语音指令进行解析,理解用户的意图,例如移动方向、距离等。3) 环境感知模块:获取VR环境的信息,例如障碍物的位置、地形等。4) 移动控制模块:根据LLM的解析结果和环境信息,控制用户在VR环境中的移动。整体流程是:用户通过语音输入指令,LLM解析指令并结合环境信息生成移动指令,最后控制用户在VR环境中移动。
关键创新:该方法最重要的创新点在于将大型语言模型(LLM)应用于VR环境中的移动控制。与传统的基于固定命令的语音控制方法相比,该方法能够理解更复杂的自然语言指令,并根据上下文进行调整,从而实现更自然、更灵活的交互。此外,该方法还结合了环境感知模块,可以避免用户移动到障碍物或地形不适宜的区域。
关键设计:论文中没有详细说明LLM的具体选择和训练细节。但是,可以推断,LLM需要具备强大的自然语言理解和生成能力,以及一定的上下文感知能力。此外,环境感知模块需要能够准确地获取VR环境的信息,并将其传递给移动控制模块。移动控制模块需要能够根据LLM的指令和环境信息,平滑地控制用户在VR环境中的移动,避免出现卡顿或不自然的现象。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于LLM的移动方法在可用性、临场感和晕动症方面与传统的瞬移方法没有显著差异。眼动追踪分析显示,用户在使用LLM驱动的移动时,注意力和参与度可能更高。SHAP分析揭示了不同移动方法在视觉注意和认知处理方面的差异。这些结果表明,基于LLM的移动方法是一种可行的、基于自然语言的免手部VR移动替代方案。
🎯 应用场景
该研究成果可广泛应用于各种VR应用场景,例如VR游戏、VR教育、VR协作等。特别是在需要免手部操作的场景下,例如医疗康复、残疾人辅助等,该方法具有重要的应用价值。未来,该技术可以进一步与手势识别、眼动追踪等技术结合,实现更自然、更智能的VR交互。
📄 摘要(原文)
Locomotion plays a crucial role in shaping the user experience within virtual reality environments. In particular, hands-free locomotion offers a valuable alternative by supporting accessibility and freeing users from reliance on handheld controllers. To this end, traditional speech-based methods often depend on rigid command sets, limiting the naturalness and flexibility of interaction. In this study, we propose a novel locomotion technique powered by large language models (LLMs), which allows users to navigate virtual environments using natural language with contextual awareness. We evaluate three locomotion methods: controller-based teleportation, voice-based steering, and our language model-driven approach. Our evaluation combines eye-tracking data analysis, including exploratory explainable machine learning analysis with SHAP, and standardized questionnaires (SUS, IPQ, CSQ-VR, NASA-TLX) to examine user experience through both objective gaze-based measures and subjective self-reports of usability, presence, cybersickness, and cognitive load. Our findings show no statistically significant differences in usability, presence, or cybersickness between LLM-driven locomotion and established methods such as teleportation, suggesting its potential as a viable, natural language-based, hands-free alternative. In addition, eye-tracking analysis revealed patterns suggesting tendency toward increased user attention and engagement in the LLM-driven condition. Complementary to these findings, exploratory SHAP analysis revealed that fixation, saccade, and pupil-related features vary across techniques, indicating distinct patterns of visual attention and cognitive processing. Overall, we state that our method can facilitate hands-free locomotion in virtual spaces, especially in supporting accessibility.