Cracking the Code of Action: a Generative Approach to Affordances for Reinforcement Learning
作者: Lynn Cherif, Flemming Kondrup, David Venuto, Ankit Anand, Doina Precup, Khimya Khetarpal
分类: cs.AI
发布日期: 2025-04-24
💡 一句话要点
提出CoGA,利用预训练视觉-语言模型生成可负担行动代码,提升GUI界面强化学习效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 强化学习 可负担性 视觉-语言模型 程序生成 GUI自动化
📋 核心要点
- Web GUI强化学习面临动作空间巨大和奖励稀疏的挑战,导致样本效率低下,需要大量专家数据。
- CoGA利用预训练VLM生成代码来推断可负担的动作,从而约束动作空间,提高学习效率。
- 实验表明,CoGA在MiniWob++上显著提升了样本效率,且具有良好的泛化能力,性能媲美行为克隆。
📝 摘要(中文)
在图形用户界面(GUI)上自主导航的智能体,若使用统一的动作空间(如鼠标和键盘操作),通常需要大量的领域专家演示才能达到良好的性能。在稀疏奖励和大型动作空间环境中,如Web GUI,低样本效率问题尤为突出,因为在任何给定情况下只有少数动作是相关的。本文考虑了低数据场景,即在有限或无法访问专家行为的情况下,通过基于意图的可负担性来约束动作空间,从而提高样本效率。我们提出了“代码即生成式可负担性”(CoGA),该方法利用预训练的视觉-语言模型(VLMs)生成代码,通过隐式意图补全函数确定可负担的动作,并使用全自动的程序生成和验证流程。这些程序在强化学习智能体的循环中使用,以返回给定像素观察的可负担性集合。通过大大减少智能体必须考虑的动作数量,我们在MiniWob++基准测试中的大量任务上证明:1) CoGA的样本效率比其RL智能体高几个数量级,2) CoGA的程序可以在一个任务族内泛化,3) 当少量专家演示可用时,CoGA的性能优于或等同于行为克隆。
🔬 方法详解
问题定义:在Web GUI等复杂环境中,强化学习智能体面临巨大的动作空间,导致探索效率低下。同时,奖励通常是稀疏的,使得智能体难以学习有效的策略。现有方法依赖大量专家数据,但在许多实际场景中,获取足够数量的专家数据是困难的。
核心思路:CoGA的核心思想是利用预训练的视觉-语言模型(VLM)来生成代码,这些代码能够根据当前环境状态推断出可负担的动作(affordances)。通过限制智能体在每个状态下考虑的动作数量,可以显著提高样本效率。这种方法将动作空间约束问题转化为程序生成问题,利用VLM的强大泛化能力。
技术框架:CoGA包含以下主要模块:1) VLM程序生成器:使用预训练的VLM,根据环境状态生成代码片段,这些代码片段定义了可负担的动作。2) 程序验证器:自动验证生成的代码是否符合预期的行为规范,确保代码的正确性和安全性。3) 可负担性提取器:执行验证后的代码,提取当前状态下可负担的动作集合。4) 强化学习智能体:使用提取的可负担动作集合作为动作空间,进行策略学习。
关键创新:CoGA的关键创新在于将可负担性学习问题转化为程序生成问题,并利用预训练的VLM来解决程序生成问题。与传统的基于规则或手工设计的可负担性方法相比,CoGA能够自动学习复杂环境中的可负担性,并且具有更好的泛化能力。此外,CoGA的程序验证器能够确保生成代码的正确性,避免了潜在的风险。
关键设计:CoGA使用预训练的视觉-语言模型(例如,CLIP或类似模型)作为程序生成器的基础。VLM的输入是环境的像素观察,输出是代码片段,这些代码片段定义了可负担的动作。程序验证器使用符号执行或类似技术来验证生成的代码是否满足预定义的规范。强化学习智能体可以使用任何标准的RL算法,例如,Q-learning或Policy Gradient。
🖼️ 关键图片

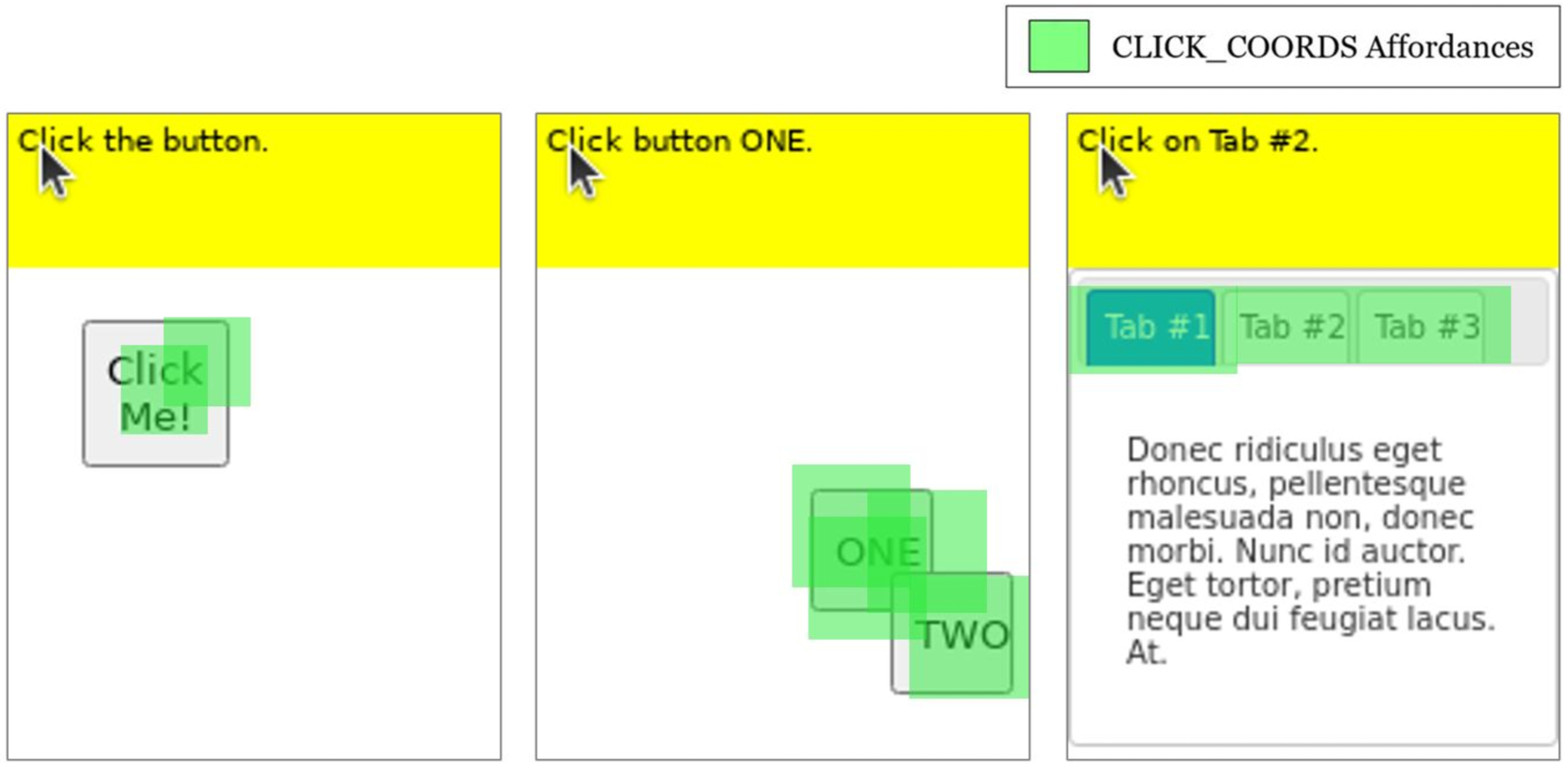

📊 实验亮点
CoGA在MiniWob++基准测试中表现出色,样本效率比传统强化学习智能体高几个数量级。实验表明,CoGA生成的程序具有良好的泛化能力,能够在同一任务族的不同实例中有效工作。此外,在少量专家数据可用的情况下,CoGA的性能与行为克隆方法相当,甚至更好。
🎯 应用场景
CoGA可应用于各种需要智能体与图形用户界面交互的场景,例如自动化测试、网页浏览助手、智能客服等。该方法能够显著降低对专家数据的依赖,提高智能体的学习效率,使其能够在复杂环境中自主完成任务。未来,CoGA有望扩展到更广泛的机器人控制和人机交互领域。
📄 摘要(原文)
Agents that can autonomously navigate the web through a graphical user interface (GUI) using a unified action space (e.g., mouse and keyboard actions) can require very large amounts of domain-specific expert demonstrations to achieve good performance. Low sample efficiency is often exacerbated in sparse-reward and large-action-space environments, such as a web GUI, where only a few actions are relevant in any given situation. In this work, we consider the low-data regime, with limited or no access to expert behavior. To enable sample-efficient learning, we explore the effect of constraining the action space through $\textit{intent-based affordances}$ -- i.e., considering in any situation only the subset of actions that achieve a desired outcome. We propose $\textbf{Code as Generative Affordances}$ $(\textbf{$\texttt{CoGA}$})$, a method that leverages pre-trained vision-language models (VLMs) to generate code that determines affordable actions through implicit intent-completion functions and using a fully-automated program generation and verification pipeline. These programs are then used in-the-loop of a reinforcement learning agent to return a set of affordances given a pixel observation. By greatly reducing the number of actions that an agent must consider, we demonstrate on a wide range of tasks in the MiniWob++ benchmark that: $\textbf{1)}$ $\texttt{CoGA}$ is orders of magnitude more sample efficient than its RL agent, $\textbf{2)}$ $\texttt{CoGA}$'s programs can generalize within a family of tasks, and $\textbf{3)}$ $\texttt{CoGA}$ performs better or on par compared with behavior cloning when a small number of expert demonstrations is available.