Trends in Frontier AI Model Count: A Forecast to 2028
作者: Iyngkarran Kumar, Sam Manning
分类: cs.CY, cs.AI
发布日期: 2025-04-21
💡 一句话要点
预测未来AI模型规模:基于训练算力阈值的模型数量预测至2028年
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI模型规模预测 训练算力阈值 AI监管政策 基础模型 算力增长趋势
📋 核心要点
- 现有AI监管框架依赖训练算力阈值,但缺乏对未来模型规模的准确预测,难以有效评估监管范围。
- 通过分析历史数据和趋势,预测未来几年内超过特定算力阈值的AI模型数量,为政策制定提供参考。
- 预测结果显示,基于绝对算力阈值的模型数量将超线性增长,而基于相对阈值的模型数量则相对稳定。
📝 摘要(中文)
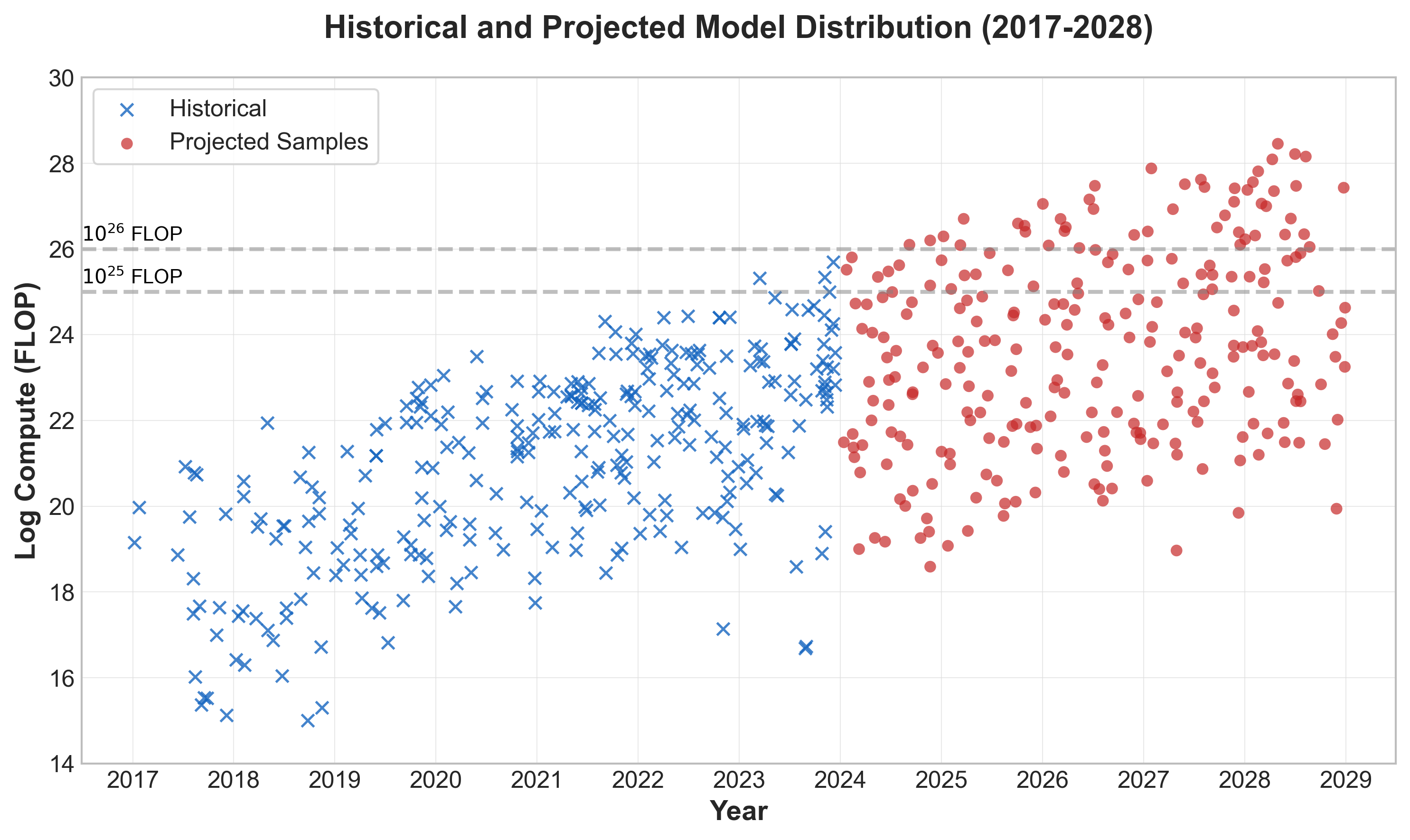
本文预测了未来几年内,超过特定训练算力阈值的AI模型数量。随着各国政府开始对AI模型施加基于训练算力的要求,例如欧盟AI法案和美国AI扩散框架分别设定了$10^{25}$ FLOP和$10^{26}$ FLOP的阈值。研究预测,到2028年底,将有103-306个基础模型超过欧盟AI法案的$10^{25}$ FLOP阈值(90%置信区间),以及45-148个模型超过美国AI扩散框架中定义的$10^{26}$ FLOP阈值(90%置信区间)。此外,超过这些绝对算力阈值的模型数量每年将超线性增长。相比之下,如果阈值是相对于当前最大训练规模定义的(例如,所有训练规模在一个数量级内的模型),则趋势更为稳定,预计2025-2028年每年将有14-16个模型符合此定义。
🔬 方法详解
问题定义:论文旨在预测未来几年内,超过特定训练算力阈值的AI模型数量。现有AI监管框架开始采用训练算力作为监管标准,但缺乏对未来模型规模的预测,难以评估监管范围和影响。因此,准确预测未来模型规模对于政策制定至关重要。
核心思路:论文的核心思路是基于历史数据和趋势,对未来AI模型的训练算力需求进行预测。通过分析过去几年中AI模型训练算力的增长速度,以及不同机构对未来算力发展的预测,建立数学模型,从而预测未来几年内超过特定算力阈值的模型数量。
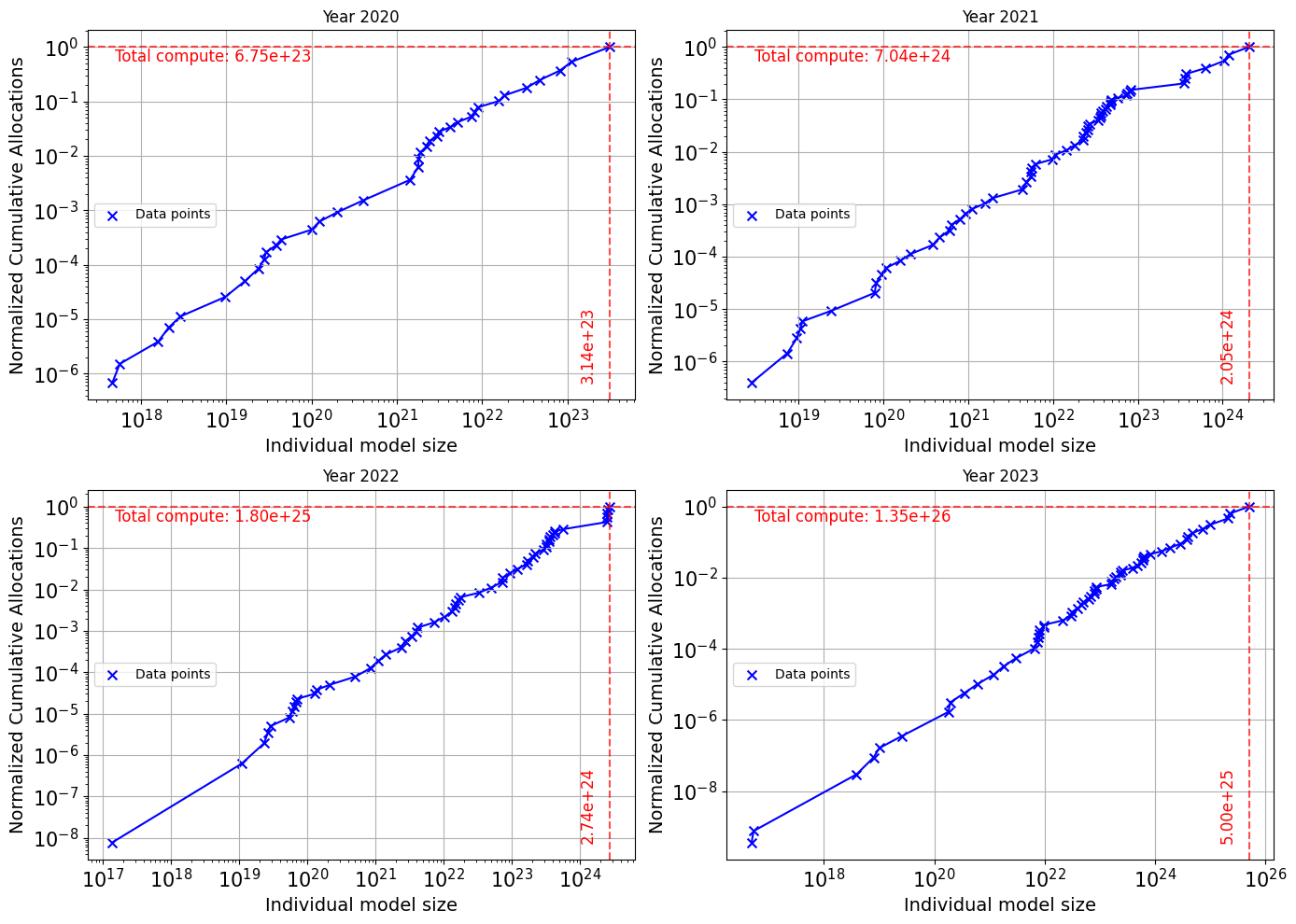
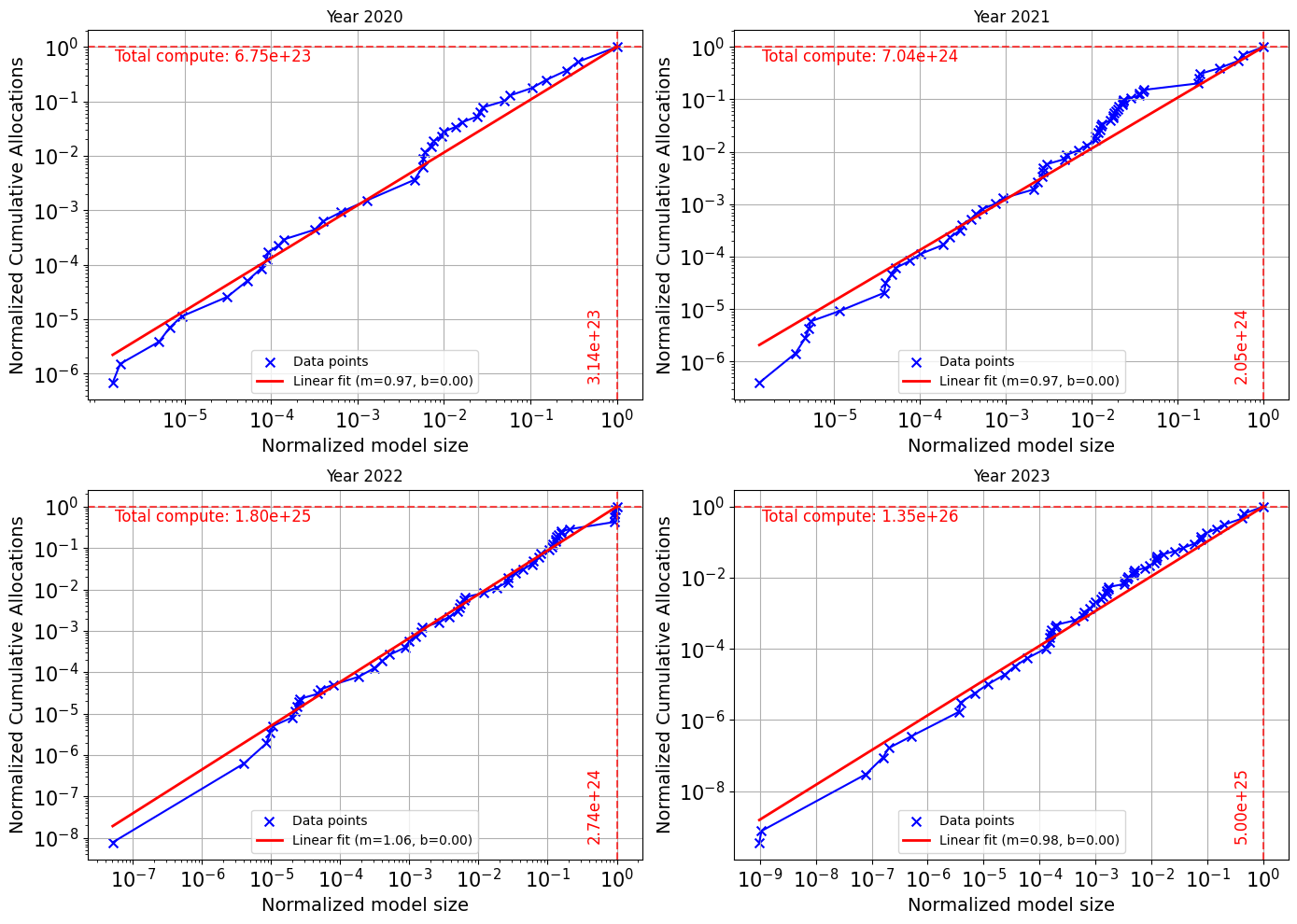
技术框架:论文的技术框架主要包括以下几个步骤:1)收集历史数据:收集过去几年中AI模型的训练算力数据,包括模型名称、训练算力、发布时间等。2)分析数据趋势:分析历史数据,确定训练算力的增长速度和趋势。3)建立预测模型:基于历史数据和趋势,建立数学模型,预测未来几年内AI模型的训练算力需求。4)设定算力阈值:根据不同的监管框架,设定不同的算力阈值。5)预测模型数量:利用预测模型,预测未来几年内超过特定算力阈值的模型数量。
关键创新:论文的关键创新在于对未来AI模型规模的预测,为AI监管政策的制定提供了量化依据。与以往的研究不同,本文不仅关注当前的模型规模,更着眼于未来的发展趋势,从而为政策制定者提供更具前瞻性的信息。
关键设计:论文的关键设计包括:1)选择合适的预测模型:论文可能采用了多种预测模型,例如线性回归、指数平滑等,以提高预测的准确性。2)考虑多种因素的影响:论文可能考虑了多种因素对模型规模的影响,例如硬件发展、算法创新、数据规模等。3)进行敏感性分析:论文可能进行了敏感性分析,以评估不同参数对预测结果的影响。
🖼️ 关键图片
📊 实验亮点
研究预测,到2028年底,将有103-306个基础模型超过欧盟AI法案的$10^{25}$ FLOP阈值(90%置信区间),以及45-148个模型超过美国AI扩散框架中定义的$10^{26}$ FLOP阈值(90%置信区间)。此外,超过这些绝对算力阈值的模型数量每年将超线性增长。
🎯 应用场景
该研究成果可应用于AI监管政策的制定,帮助政府和监管机构更好地评估AI模型的风险,并制定相应的监管措施。此外,该研究还可以帮助企业了解AI技术的发展趋势,从而更好地规划AI战略和投资。
📄 摘要(原文)
Governments are starting to impose requirements on AI models based on how much compute was used to train them. For example, the EU AI Act imposes requirements on providers of general-purpose AI with systemic risk, which includes systems trained using greater than $10^{25}$ floating point operations (FLOP). In the United States' AI Diffusion Framework, a training compute threshold of $10^{26}$ FLOP is used to identify "controlled models" which face a number of requirements. We explore how many models such training compute thresholds will capture over time. We estimate that by the end of 2028, there will be between 103-306 foundation models exceeding the $10^{25}$ FLOP threshold put forward in the EU AI Act (90% CI), and 45-148 models exceeding the $10^{26}$ FLOP threshold that defines controlled models in the AI Diffusion Framework (90% CI). We also find that the number of models exceeding these absolute compute thresholds each year will increase superlinearly -- that is, each successive year will see more new models captured within the threshold than the year before. Thresholds that are defined with respect to the largest training run to date (for example, such that all models within one order of magnitude of the largest training run to date are captured by the threshold) see a more stable trend, with a median forecast of 14-16 models being captured by this definition annually from 2025-2028.