AGI Is Coming... Right After AI Learns to Play Wordle
作者: Sarath Shekkizhar, Romain Cosentino
分类: cs.AI, cs.CV
发布日期: 2025-04-21
💡 一句话要点
评估多模态Agent在Wordle游戏中的表现,揭示其在颜色识别方面的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态Agent Wordle游戏 颜色识别 计算机用户代理 AI评估
📋 核心要点
- 现有AI Agent在处理看似简单的任务时仍面临挑战,尤其是在需要精确感知和推理的环境中。
- 本文通过评估OpenAI的CUA在Wordle游戏中的表现,分析其在颜色识别等方面的能力。
- 实验结果表明,该Agent在Wordle游戏中的成功率较低,揭示了其在多模态理解和推理方面的局限性。
📝 摘要(中文)
本文研究了多模态Agent,特别是OpenAI的计算机用户代理(CUA),该代理经过训练,可以通过标准计算机界面控制和完成任务,类似于人类。我们评估了该Agent在纽约时报Wordle游戏中的表现,以引出模型行为并识别缺点。我们的发现揭示了模型在正确识别颜色方面的能力存在显著差异,具体取决于上下文。该模型在一周内的数百次Wordle运行中,成功率为5.36%。尽管围绕AI Agent及其开启通用人工智能(AGI)的潜力存在巨大的热情,但我们的发现强化了这样一个事实,即即使是简单的任务也给当今的前沿AI模型带来了巨大的挑战。最后,我们讨论了潜在的根本原因、对未来发展的影响以及改进这些AI系统的研究方向。
🔬 方法详解
问题定义:论文旨在评估当前先进的多模态Agent在执行简单任务时的能力,并识别其潜在的弱点。现有的AI Agent,即使是像OpenAI的CUA这样的大型模型,在处理需要视觉感知和逻辑推理相结合的任务时,仍然存在不足。Wordle游戏被选作测试平台,因为它需要Agent理解颜色编码的反馈,并根据这些反馈迭代地改进猜测,这对于人类来说是相对简单的任务,但对于AI来说可能具有挑战性。
核心思路:论文的核心思路是通过观察Agent在Wordle游戏中的行为,来诊断其在多模态理解和推理方面的缺陷。Wordle游戏提供了一个受控的环境,可以方便地追踪Agent的每一步操作,并分析其错误的原因。通过分析Agent在颜色识别方面的表现,可以深入了解其视觉感知能力的局限性。
技术框架:该研究主要依赖于现有的OpenAI CUA模型,并将其应用于Wordle游戏环境。研究人员没有修改模型本身,而是专注于评估其在特定任务上的表现。整个流程包括:1) Agent与Wordle游戏界面交互;2) Agent根据游戏反馈(颜色编码)进行推理;3) Agent做出新的猜测;4) 重复步骤1-3,直到游戏结束或达到最大猜测次数。研究人员记录了Agent的每一次猜测和游戏反馈,以便进行后续分析。
关键创新:该论文的主要创新在于其评估方法,即利用Wordle游戏作为测试平台,来诊断多模态Agent的弱点。虽然Wordle游戏本身很简单,但它能够有效地揭示Agent在颜色识别、逻辑推理和迭代改进方面的局限性。这种评估方法可以推广到其他类似的任务,为未来的AI Agent开发提供有价值的反馈。
关键设计:研究中没有涉及特定的参数设置或网络结构设计,因为重点在于评估现有模型的性能。关键的设计在于实验的设置,即如何将Wordle游戏与CUA模型连接起来,并记录Agent的每一次操作。研究人员需要确保Agent能够正确地理解游戏界面,并能够根据游戏反馈做出合理的猜测。此外,研究人员还设计了一套评估指标,用于衡量Agent在Wordle游戏中的表现,例如成功率和平均猜测次数。
🖼️ 关键图片

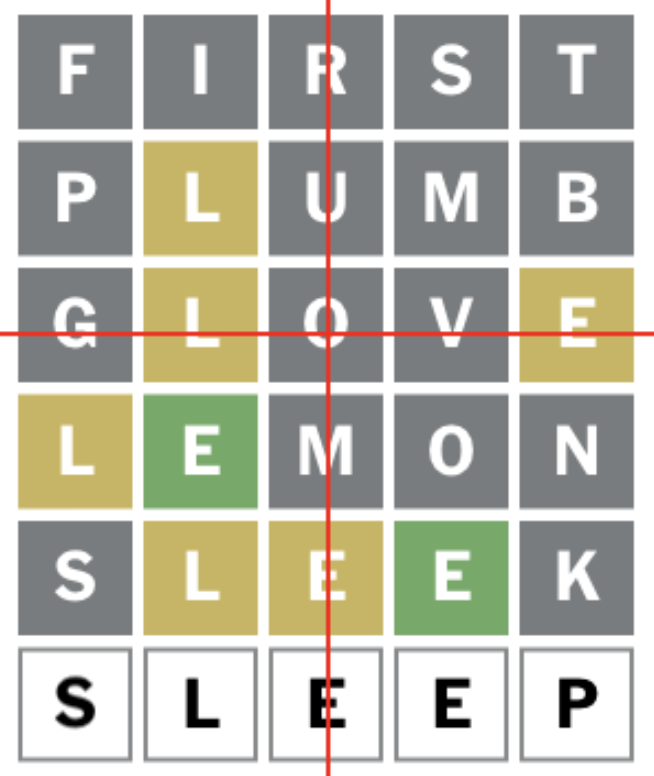
📊 实验亮点
实验结果显示,OpenAI的CUA模型在Wordle游戏中的成功率仅为5.36%。这一结果表明,即使是对于人类来说相对简单的任务,对于当前最先进的AI Agent来说仍然具有挑战性。研究还发现,该模型在颜色识别方面存在显著的上下文依赖性,这可能是导致其性能不佳的原因之一。这些发现为未来的AI Agent开发提供了重要的启示。
🎯 应用场景
该研究的成果可以应用于评估和改进各种多模态Agent,尤其是在需要视觉感知和逻辑推理相结合的场景中,例如机器人导航、自动驾驶、智能助手等。通过识别Agent的弱点,可以有针对性地改进其算法和模型,提高其在实际应用中的可靠性和效率。此外,该研究也为开发更强大的通用人工智能(AGI)系统提供了有价值的参考。
📄 摘要(原文)
This paper investigates multimodal agents, in particular, OpenAI's Computer-User Agent (CUA), trained to control and complete tasks through a standard computer interface, similar to humans. We evaluated the agent's performance on the New York Times Wordle game to elicit model behaviors and identify shortcomings. Our findings revealed a significant discrepancy in the model's ability to recognize colors correctly depending on the context. The model had a $5.36\%$ success rate over several hundred runs across a week of Wordle. Despite the immense enthusiasm surrounding AI agents and their potential to usher in Artificial General Intelligence (AGI), our findings reinforce the fact that even simple tasks present substantial challenges for today's frontier AI models. We conclude with a discussion of the potential underlying causes, implications for future development, and research directions to improve these AI systems.