LLM-Assisted Translation of Legacy FORTRAN Codes to C++: A Cross-Platform Study
作者: Nishath Rajiv Ranasinghe, Shawn M. Jones, Michal Kucer, Ayan Biswas, Daniel O'Malley, Alexander Buschmann Most, Selma Liliane Wanna, Ajay Sreekumar
分类: cs.SE, cs.AI
发布日期: 2025-04-21
备注: 12 pages, 7 figures, 2 tables
💡 一句话要点
利用大语言模型辅助将遗留FORTRAN代码翻译为C++,并进行跨平台研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 代码翻译 FORTRAN C++ 遗留代码 高性能计算 代码迁移 跨平台
📋 核心要点
- 遗留FORTRAN代码库的维护和迁移面临挑战,缺乏对LLM代码翻译质量的系统评估。
- 探索利用LLM自动将FORTRAN代码翻译为C++,旨在降低迁移成本并提升代码可维护性。
- 通过编译准确率、代码相似度和输出相似度等多项指标,量化评估LLM翻译的性能。
📝 摘要(中文)
本文研究了利用大语言模型(LLM)将FORTRAN代码翻译为C++的可行性,旨在构建一个基于开放权重LLM的智能工作流,并评估其在不同计算平台上的性能。FORTRAN作为高性能计算(HPC)领域中用于科学发现的重要编程语言,其遗留代码库的LLM翻译尚未得到充分评估。本文统计量化了翻译后的C++代码的编译准确率,测量了LLM翻译的代码与人工翻译的C++代码的相似度,并统计量化了FORTRAN到C++翻译的输出相似度。
🔬 方法详解
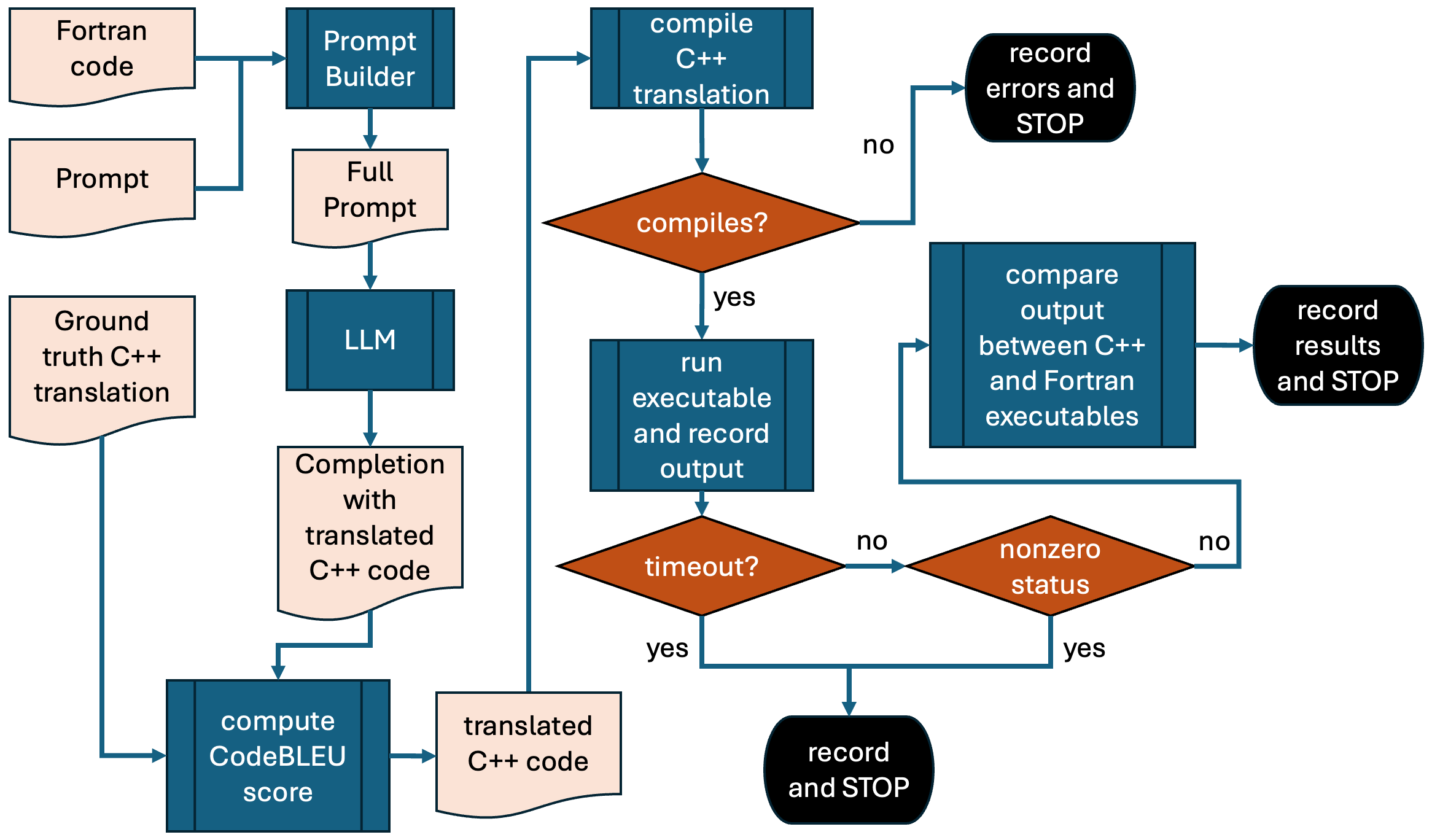
问题定义:论文旨在解决遗留FORTRAN代码向现代C++代码迁移的问题。现有方法,如手动翻译,成本高昂且容易出错。缺乏对LLM自动翻译FORTRAN代码的系统性评估,阻碍了其在实际项目中的应用。
核心思路:论文的核心思路是利用大语言模型(LLM)的强大代码生成和翻译能力,自动将FORTRAN代码转换为C++代码。通过统计分析编译准确率、代码相似度和输出相似度,全面评估LLM翻译的质量和可靠性。
技术框架:该研究的技术框架包括以下几个主要步骤:1) 选择合适的开源LLM;2) 构建FORTRAN代码数据集;3) 使用LLM将FORTRAN代码翻译为C++代码;4) 评估翻译后的C++代码的编译准确率;5) 测量LLM翻译的代码与人工翻译的C++代码的相似度;6) 统计量化FORTRAN到C++翻译的输出相似度。研究在不同的计算平台上进行,以评估跨平台性能。
关键创新:该研究的关键创新在于系统性地评估了LLM在FORTRAN到C++代码翻译中的应用。通过量化编译准确率、代码相似度和输出相似度,为LLM在遗留代码迁移中的应用提供了客观的评估指标。此外,该研究还探索了在不同计算平台上使用LLM进行代码翻译的可行性。
关键设计:论文的关键设计包括:选择合适的开源LLM(具体模型未知),构建具有代表性的FORTRAN代码数据集(数据集构建细节未知),以及设计合理的评估指标(编译准确率、代码相似度和输出相似度的具体计算方法未知)。研究可能使用了特定的提示工程(prompt engineering)技术来指导LLM进行代码翻译,但具体细节未知。
🖼️ 关键图片

📊 实验亮点
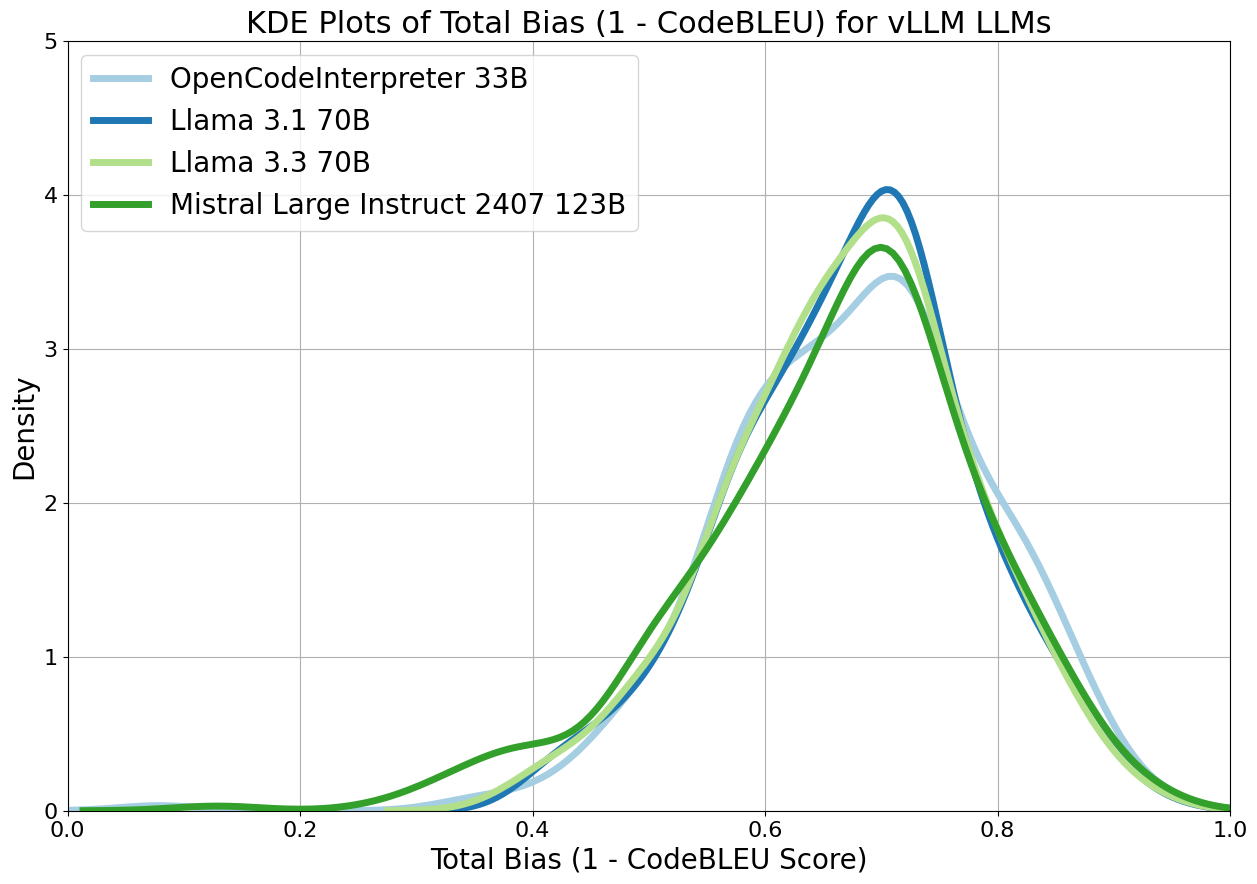
论文通过实验量化评估了LLM在FORTRAN到C++代码翻译中的性能,包括编译准确率、代码相似度和输出相似度。虽然具体的性能数据未在摘要中给出,但该研究为评估LLM在代码翻译任务中的实用性提供了重要参考,并为构建基于LLM的自动化代码迁移工具奠定了基础。
🎯 应用场景
该研究成果可应用于遗留科学计算代码的现代化改造,降低代码迁移成本,提高代码可维护性。通过自动化代码翻译,可以加速科学研究的迭代过程,并促进不同平台之间的代码共享和复用。未来,该方法有望扩展到其他编程语言的翻译,并应用于更广泛的软件工程领域。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly being leveraged for generating and translating scientific computer codes by both domain-experts and non-domain experts. Fortran has served as one of the go to programming languages in legacy high-performance computing (HPC) for scientific discoveries. Despite growing adoption, LLM-based code translation of legacy code-bases has not been thoroughly assessed or quantified for its usability. Here, we studied the applicability of LLM-based translation of Fortran to C++ as a step towards building an agentic-workflow using open-weight LLMs on two different computational platforms. We statistically quantified the compilation accuracy of the translated C++ codes, measured the similarity of the LLM translated code to the human translated C++ code, and statistically quantified the output similarity of the Fortran to C++ translation.