Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning
作者: Jie Cheng, Gang Xiong, Ruixi Qiao, Lijun Li, Chao Guo, Junle Wang, Yisheng Lv, Fei-Yue Wang
分类: cs.AI, cs.LG
发布日期: 2025-04-21 (更新: 2025-10-23)
备注: Accepted by NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出PURE,通过最小形式奖励分配解决过程奖励模型中的奖励利用问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 过程奖励模型 强化学习 奖励利用 最小形式奖励分配 大型语言模型微调 推理任务 价值函数
📋 核心要点
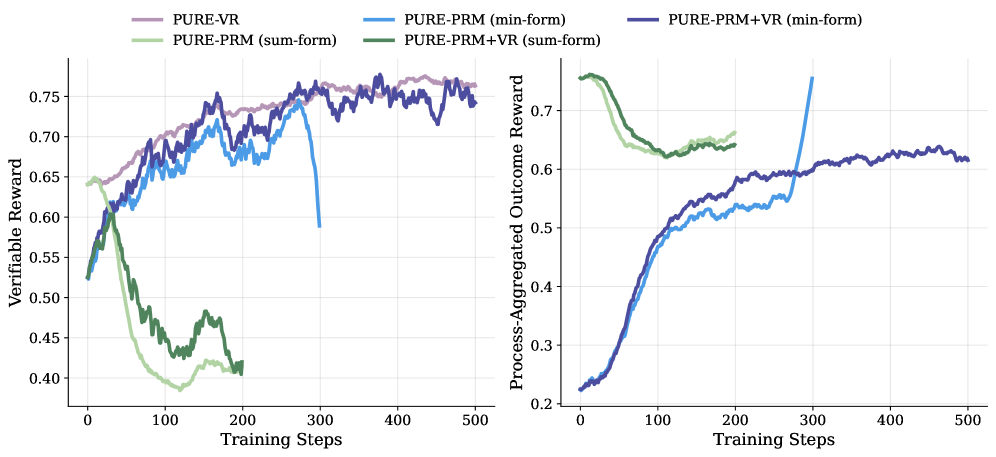
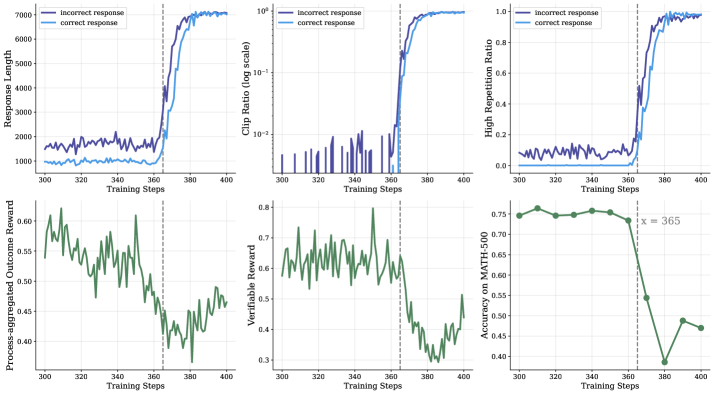
- 现有过程奖励模型在强化微调中存在奖励利用问题,导致训练崩溃。
- PURE采用最小形式的奖励分配,将价值函数定义为未来奖励的最小值,限制价值范围。
- 实验表明,PURE在推理性能上可与可验证奖励方法媲美,且能有效缓解奖励利用。
📝 摘要(中文)
过程奖励模型(PRM)已被证明在大型语言模型(LLM)的测试时扩展方面有效,尤其是在具有挑战性的推理任务中。然而,PRM的奖励利用问题限制了其在强化微调中的成功应用。本文指出PRM诱导奖励利用的主要原因是强化学习(RL)中规范的求和形式奖励分配,它将价值定义为累积的伽马衰减未来奖励,容易诱导LLM利用具有高奖励的步骤。为了解决这个问题,我们提出了PURE:过程监督强化学习。PURE的关键创新是一种最小形式的奖励分配,它将价值函数定义为未来奖励的最小值。这种方法通过限制价值函数范围和更合理地分配优势,显著缓解了奖励利用。通过对3个基础模型的广泛实验,我们表明,基于PRM的方法能够实现最小形式的奖励分配,在仅30%的步骤内实现了与基于可验证奖励的方法相当的推理性能。相比之下,规范的求和形式奖励分配甚至在开始时就崩溃了训练!此外,当我们用仅10%的可验证奖励补充基于PRM的微调时,我们进一步缓解了奖励利用,并产生了基于Qwen2.5-Math-7B的最佳微调模型,在我们的实验中,在AMC23上实现了82.5%的准确率,在5个基准测试中实现了53.3%的平均准确率。此外,我们总结了观察到的奖励利用案例,并分析了训练崩溃的原因。我们在https://github.com/CJReinforce/PURE发布了我们的代码和模型权重。
🔬 方法详解
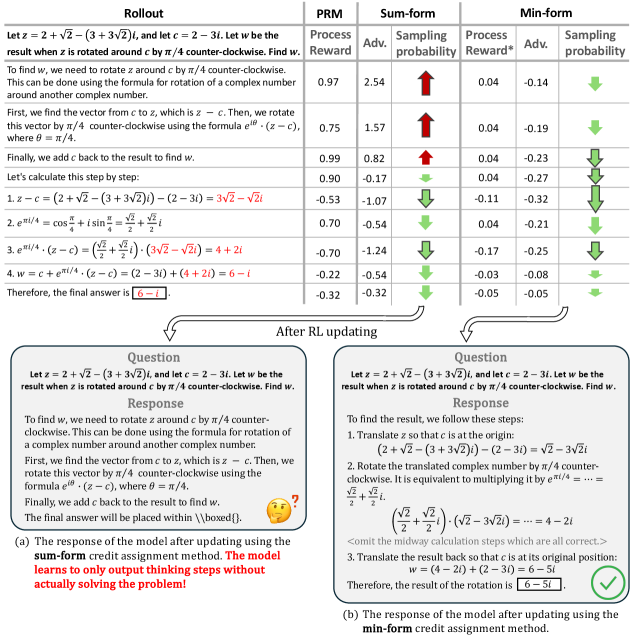
问题定义:论文旨在解决过程奖励模型(PRM)在强化学习微调大型语言模型时出现的奖励利用(reward hacking)问题。现有的PRM方法采用求和形式的奖励分配,导致模型倾向于利用高奖励的步骤,而非真正学习到解决问题的能力,最终导致训练崩溃。
核心思路:论文的核心思路是将传统的求和形式奖励分配替换为最小形式的奖励分配。具体来说,价值函数不再是未来奖励的累积和,而是未来奖励的最小值。这样设计的目的是限制价值函数的范围,使得模型更难通过操纵个别步骤的奖励来获得高价值,从而缓解奖励利用问题。
技术框架:PURE(Process sUpervised Reinforcement lEarning)的整体框架仍然是基于强化学习的微调流程,但关键在于奖励信号的计算方式。它使用过程奖励模型(PRM)来生成每一步的奖励,然后使用最小形式的奖励分配来计算价值函数,并以此指导模型的训练。此外,论文还探索了结合少量可验证奖励来进一步提升模型性能的方法。
关键创新:最重要的技术创新点是最小形式的奖励分配。与传统的求和形式相比,最小形式能够更有效地限制价值函数的范围,从而减少模型利用奖励漏洞的机会。这种方法改变了模型学习的激励机制,使其更关注于整个过程的质量,而非个别步骤的奖励。
关键设计:PURE的关键设计在于价值函数的计算方式:V(s) = min(r_t, r_{t+1}, ..., r_T),其中V(s)是状态s的价值,r_t是时间步t的奖励,T是episode的结束时间。此外,论文还研究了如何结合少量可验证奖励来进一步提升模型性能,例如使用10%的可验证奖励来辅助PRM的训练。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PURE在仅使用30%步骤的情况下,达到了与可验证奖励方法相当的推理性能。在AMC23数据集上,使用PURE微调的Qwen2.5-Math-7B模型达到了82.5%的准确率,在5个基准测试中平均准确率达到53.3%。这些结果表明,PURE能够有效缓解奖励利用问题,并提升模型的推理能力。
🎯 应用场景
该研究成果可应用于各种需要通过强化学习微调大型语言模型的场景,尤其是在奖励信号难以精确定义或容易被模型利用的任务中,例如数学推理、代码生成、对话系统等。通过缓解奖励利用问题,可以提升模型的泛化能力和鲁棒性,使其更好地解决实际问题。
📄 摘要(原文)
Process reward models (PRMs) have proven effective for test-time scaling of Large Language Models (LLMs) on challenging reasoning tasks. However, reward hacking issues with PRMs limit their successful application in reinforcement fine-tuning. In this paper, we identify the main cause of PRM-induced reward hacking: the canonical summation-form credit assignment in reinforcement learning (RL), which defines the value as cumulative gamma-decayed future rewards, easily induces LLMs to hack steps with high rewards. To address this, we propose PURE: Process sUpervised Reinforcement lEarning. The key innovation of PURE is a min-form credit assignment that formulates the value function as the minimum of future rewards. This method significantly alleviates reward hacking by limiting the value function range and distributing advantages more reasonably. Through extensive experiments on 3 base models, we show that PRM-based approaches enabling min-form credit assignment achieve comparable reasoning performance to verifiable reward-based methods within only 30% steps. In contrast, the canonical sum-form credit assignment collapses training even at the beginning! Additionally, when we supplement PRM-based fine-tuning with just 10% verifiable rewards, we further alleviate reward hacking and produce the best fine-tuned model based on Qwen2.5-Math-7B in our experiments, achieving 82.5% accuracy on AMC23 and 53.3% average accuracy across 5 benchmarks. Moreover, we summarize the observed reward hacking cases and analyze the causes of training collapse. We release our code and model weights at https://github.com/CJReinforce/PURE.