DRAGON: Distributional Rewards Optimize Diffusion Generative Models
作者: Yatong Bai, Jonah Casebeer, Somayeh Sojoudi, Nicholas J. Bryan
分类: cs.SD, cs.AI, cs.LG, cs.MM
发布日期: 2025-04-21 (更新: 2025-11-14)
备注: Accepted to TMLR
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出DRAGON框架以优化生成模型的奖励函数
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 生成模型 奖励函数 多模态学习 音频生成 强化学习
📋 核心要点
- 现有的强化学习方法在优化生成模型时存在灵活性不足的问题,难以适应多样化的奖励函数需求。
- DRAGON框架通过构建示例分布,能够优化多种类型的奖励函数,提升生成模型的效果和灵活性。
- 实验结果表明,DRAGON在音频生成任务中表现优异,平均胜率达到81.45%,且在音乐质量评估中获得了60.95%的胜率。
📝 摘要(中文)
我们提出了分布式奖励优化生成模型的框架DRAGON,旨在针对特定结果微调媒体生成模型。与传统的基于人类反馈的强化学习方法相比,DRAGON具有更高的灵活性,能够优化评估单个示例或其分布的奖励函数。通过选择编码器和参考示例构建示例分布,DRAGON能够在不同模态之间进行优化。我们在音频领域的文本到音乐扩散模型上进行了20种奖励函数的微调,结果显示DRAGON在所有目标奖励上达到了81.45%的平均胜率,并且在没有人类偏好注释的情况下,获得了60.95%的音乐质量胜率。
🔬 方法详解
问题定义:本论文旨在解决现有生成模型在优化奖励函数时灵活性不足的问题。传统方法如基于人类反馈的强化学习(RLHF)和成对偏好优化(DPO)在处理多样化奖励时存在局限性。
核心思路:DRAGON框架通过引入分布式奖励的概念,能够同时优化评估单个示例和示例分布的奖励函数,从而提升生成模型的适应性和效果。
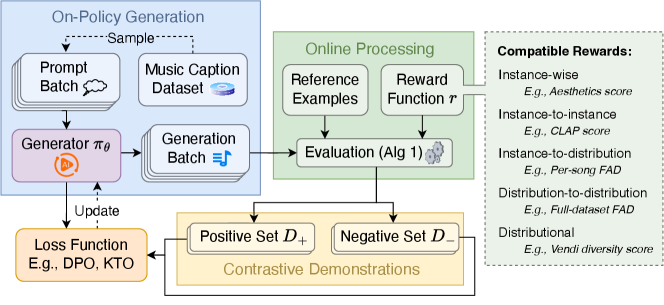
技术框架:DRAGON的整体流程包括选择编码器和参考示例构建示例分布,在线生成并评分,构建正负示例集,最后通过对比优化奖励。主要模块包括奖励函数构建、在线生成、评分和优化。
关键创新:DRAGON的核心创新在于其灵活的奖励函数设计,能够处理实例级、实例到分布以及分布到分布的奖励,显著提升了生成模型的优化能力。
关键设计:在实验中,DRAGON使用了20种不同的奖励函数,包括自定义的音乐美学模型、CLAP评分、Vendi多样性和Frechet音频距离(FAD),并通过不同的FAD编码器和参考集进行消融实验。
🖼️ 关键图片
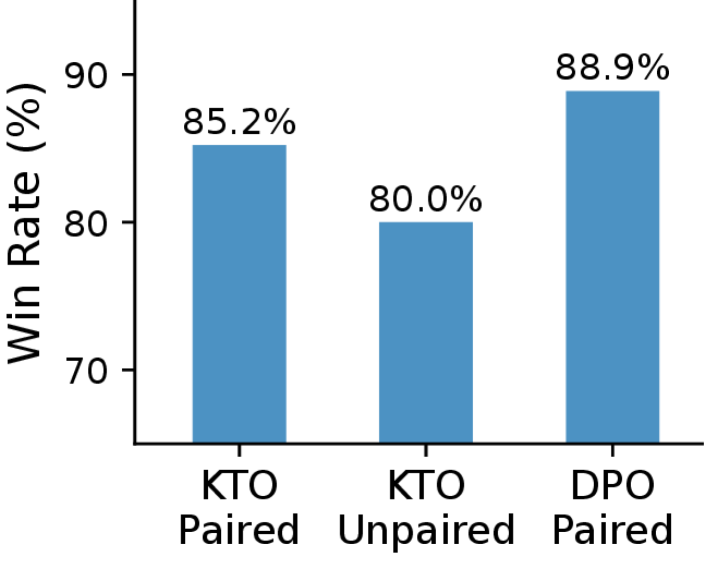

📊 实验亮点
在实验中,DRAGON在20种目标奖励上实现了81.45%的平均胜率,显示出其在优化生成模型方面的强大能力。此外,基于示例集的奖励函数在生成效果上与模型基于的奖励相当,且在没有人类偏好注释的情况下,获得了60.95%的音乐质量胜率,展示了其实际应用价值。
🎯 应用场景
DRAGON框架在多媒体生成领域具有广泛的应用潜力,尤其是在音频生成、图像合成和文本生成等任务中。其灵活的奖励函数设计能够适应不同的生成需求,提升生成内容的质量和多样性,未来可能在艺术创作、游戏开发和内容生成等领域发挥重要作用。
📄 摘要(原文)
We present Distributional RewArds for Generative OptimizatioN (DRAGON), a versatile framework for fine-tuning media generation models towards a desired outcome. Compared with traditional reinforcement learning with human feedback (RLHF) or pairwise preference approaches such as direct preference optimization (DPO), DRAGON is more flexible. It can optimize reward functions that evaluate either individual examples or distributions of them, making it compatible with a broad spectrum of instance-wise, instance-to-distribution, and distribution-to-distribution rewards. Leveraging this versatility, we construct novel reward functions by selecting an encoder and a set of reference examples to create an exemplar distribution. When cross-modal encoders such as CLAP are used, the reference may be of a different modality (text versus audio). Then, DRAGON gathers online and on-policy generations, scores them with the reward function to construct a positive demonstration set and a negative set, and leverages the contrast between the two finite sets to approximate distributional reward optimization. For evaluation, we fine-tune an audio-domain text-to-music diffusion model with 20 reward functions, including a custom music aesthetics model, CLAP score, Vendi diversity, and Frechet audio distance (FAD). We further compare instance-wise (per-song) and full-dataset FAD settings while ablating multiple FAD encoders and reference sets. Over all 20 target rewards, DRAGON achieves an 81.45% average win rate. Moreover, reward functions based on exemplar sets enhance generations and are comparable to model-based rewards. With an appropriate exemplar set, DRAGON achieves a 60.95% human-voted music quality win rate without training on human preference annotations. DRAGON is a new approach to designing and optimizing reward functions for improving human-perceived quality. Demos at https://ml-dragon.github.io/web