EducationQ: Evaluating LLMs' Teaching Capabilities Through Multi-Agent Dialogue Framework
作者: Yao Shi, Rongkeng Liang, Yong Xu
分类: cs.AI, cs.CE, cs.CL, cs.CY, cs.HC
发布日期: 2025-04-21 (更新: 2025-07-31)
备注: Paper URL: https://aclanthology.org/2025.acl-long.1576 ;Presentation Video: https://www.youtube.com/watch?v=j63ooKE50I0
期刊: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2025) 32799-32828
DOI: 10.18653/v1/2025.acl-long.1576
💡 一句话要点
EducationQ:通过多智能体对话框架评估LLM的教学能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 教学能力评估 多智能体系统 教育AI 对话框架
📋 核心要点
- 现有评估方法难以有效评估LLM的教学能力,因为师生互动复杂且资源密集。
- EducationQ通过构建多智能体对话框架,模拟动态教育场景,实现对LLM教学能力的有效评估。
- 实验表明,LLM的教学效果与模型规模并非线性相关,且EducationQ的评估结果与人类专家评估高度一致。
📝 摘要(中文)
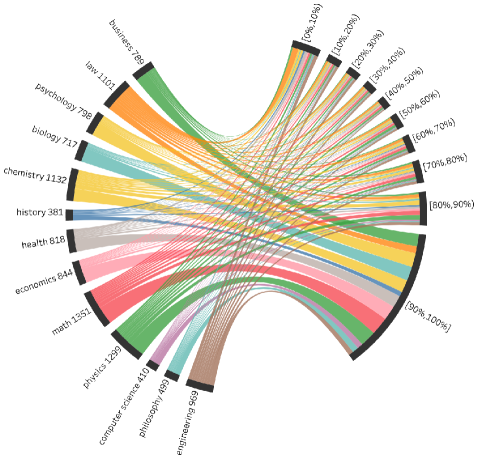
大型语言模型(LLM)越来越多地被用作教育工具,但由于师生互动在资源、情境依赖性和方法复杂性方面的限制,评估其教学能力仍然具有挑战性。我们引入了EducationQ,一个多智能体对话框架,通过模拟动态教育场景来有效评估教学能力,该框架包含教学、学习和评估的专用智能体。我们使用EducationQ测试了来自主要AI机构(OpenAI、Meta、Google、Anthropic等)的14个LLM,涵盖13个学科和10个难度等级的1498个问题,结果表明教学效果与模型规模或一般推理能力并不呈线性相关——一些较小的开源模型在教学环境中优于较大的商业模型。这一发现突显了当前评估中优先考虑知识回忆而非互动教学法的关键差距。我们结合定量指标、定性分析和专家案例研究的混合方法评估,确定了表现最佳模型所采用的独特教学优势(例如,复杂的提问策略、自适应反馈机制)。人类专家评估与我们对有效教学行为的自动定性分析有78%的一致性,验证了我们的方法。EducationQ表明,LLM作为教师需要专门的优化,而不仅仅是简单的扩展,这表明下一代教育AI应优先考虑有针对性地增强特定教学效果。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型(LLM)的教学能力的问题。现有方法主要依赖于知识回忆的评估,忽略了教学过程中重要的互动性和教学策略,无法全面反映LLM的教学水平。此外,传统的评估方法通常需要大量的人工标注和评估,成本高昂且效率低下。
核心思路:论文的核心思路是构建一个多智能体对话框架,模拟真实的师生互动场景。通过设计专门的智能体扮演教师、学生和评估者的角色,可以动态地评估LLM在教学过程中的表现。这种方法能够更全面地考察LLM的教学能力,包括提问技巧、反馈机制和知识传递等方面。
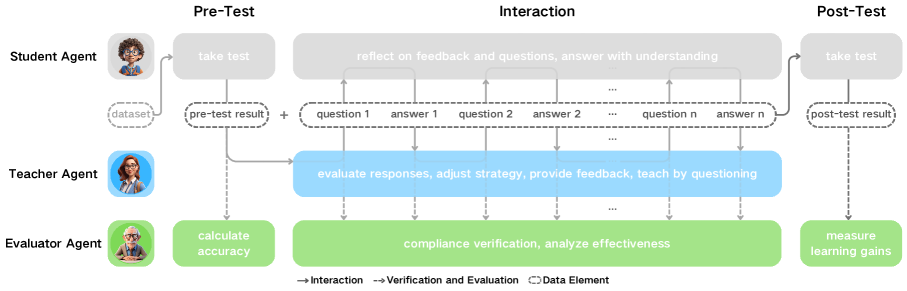
技术框架:EducationQ框架包含三个主要模块:教师智能体(Teacher Agent)、学生智能体(Student Agent)和评估智能体(Evaluation Agent)。教师智能体负责根据问题和学生的回答进行教学,学生智能体负责学习和回答问题,评估智能体负责评估教师智能体的教学效果。整个流程包括:教师智能体提出问题,学生智能体回答问题,教师智能体根据回答提供反馈,评估智能体根据互动过程和结果评估教学质量。
关键创新:该论文的关键创新在于提出了一个多智能体对话框架,用于评估LLM的教学能力。与传统的评估方法相比,EducationQ能够更全面地考察LLM在教学过程中的表现,包括提问技巧、反馈机制和知识传递等方面。此外,该框架可以自动化地进行评估,大大降低了评估成本和提高了评估效率。
关键设计:在EducationQ框架中,教师智能体使用LLM作为其核心引擎,通过Prompt Engineering来控制其教学行为。学生智能体也使用LLM,但其目标是学习和回答问题,而不是进行教学。评估智能体则使用一系列指标来评估教学效果,包括回答正确率、互动轮数和反馈质量等。具体的Prompt设计和评估指标的选择需要根据具体的教学场景和目标进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM的教学效果与模型规模并非线性相关,一些较小的开源模型在教学环境中表现优于较大的商业模型。此外,人类专家评估与EducationQ的自动定性分析有78%的一致性,验证了该方法的有效性。EducationQ在评估LLM教学能力方面提供了一种有效且可靠的解决方案。
🎯 应用场景
EducationQ框架可应用于各种教育场景,例如在线教育平台、智能辅导系统和个性化学习工具。它可以帮助开发者评估和优化LLM的教学能力,从而提高教育产品的质量和效果。此外,该框架还可以用于研究不同教学策略对学生学习效果的影响,为教育研究提供新的工具和方法。未来,EducationQ有望成为评估和改进教育AI的重要标准。
📄 摘要(原文)
Large language models (LLMs) increasingly serve as educational tools, yet evaluating their teaching capabilities remains challenging due to the resource-intensive, context-dependent, and methodologically complex nature of teacher-student interactions. We introduce EducationQ, a multi-agent dialogue framework that efficiently assesses teaching capabilities through simulated dynamic educational scenarios, featuring specialized agents for teaching, learning, and evaluation. Testing 14 LLMs across major AI Organizations (OpenAI, Meta, Google, Anthropic, and others) on 1,498 questions spanning 13 disciplines and 10 difficulty levels reveals that teaching effectiveness does not correlate linearly with model scale or general reasoning capabilities - with some smaller open-source models outperforming larger commercial counterparts in teaching contexts. This finding highlights a critical gap in current evaluations that prioritize knowledge recall over interactive pedagogy. Our mixed-methods evaluation, combining quantitative metrics with qualitative analysis and expert case studies, identifies distinct pedagogical strengths employed by top-performing models (e.g., sophisticated questioning strategies, adaptive feedback mechanisms). Human expert evaluations show 78% agreement with our automated qualitative analysis of effective teaching behaviors, validating our methodology. EducationQ demonstrates that LLMs-as-teachers require specialized optimization beyond simple scaling, suggesting next-generation educational AI prioritize targeted enhancement of specific pedagogical effectiveness.