DONOD: Efficient and Generalizable Instruction Fine-Tuning for LLMs via Model-Intrinsic Dataset Pruning
作者: Jucheng Hu, Surong Yang, Lijun Wu, Dongzhan Zhou
分类: cs.AI, cs.LG
发布日期: 2025-04-21 (更新: 2025-08-08)
💡 一句话要点
DONOD:通过模型内禀数据剪枝实现高效且泛化的LLM指令微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 数据剪枝 大语言模型 模型泛化 噪声鲁棒性
📋 核心要点
- 领域特定指令微调(SFT)在LLM中被广泛应用,但其泛化能力较弱,且容易受到噪声数据的影响。
- DONOD通过DON和NOD两种模型参数指标评估数据质量,并使用TOPSIS算法过滤有害样本,无需额外模型。
- 实验表明,DONOD在数学任务上能有效提升目标域和跨域准确率,并具有良好的跨架构泛化能力。
📝 摘要(中文)
本文提出DONOD,一种轻量级的模型内禀数据剪枝方法,旨在解决LLM指令微调中领域泛化性弱和对噪声数据敏感的问题。该方法利用模型参数,通过Delta of Norm (DON)衡量数据对模型权重的影响,Norm of Delta (NOD)量化权重不稳定性,并结合TOPSIS算法,在SFT过程中有效过滤噪声、难以学习和损害泛化的样本,无需辅助模型。在数学任务上的实验表明,DONOD选择的数据能够实现更高的微调效率和对噪声数据的鲁棒性。通过过滤70%的数据,目标域准确率提升14.90%,跨域准确率提升5.67%。此外,该方法具有良好的跨架构泛化性,小模型剪枝的数据可以有效泛化到大模型。与现有方法相比,DONOD在保持或超越性能的同时,具有数据集无关性,适用性更广。代码即将开源。
🔬 方法详解
问题定义:现有的大语言模型(LLM)指令微调方法,特别是领域特定的监督微调(SFT),虽然在特定领域表现良好且效率较高,但往往会削弱模型在其他领域的泛化能力。此外,这些方法对训练数据中的噪声非常敏感,容易受到噪声数据的影响,导致模型性能下降。因此,如何提高LLM在指令微调过程中的泛化能力,并使其对噪声数据具有更强的鲁棒性,是一个重要的研究问题。
核心思路:DONOD的核心思路是利用模型自身的参数来评估训练数据的质量,并进行数据剪枝,从而提高微调效率和泛化能力。具体来说,DONOD通过计算数据对模型权重的影响(Delta of Norm, DON)和权重的不稳定性(Norm of Delta, NOD)来判断数据的重要性和质量。然后,利用TOPSIS算法,综合考虑DON和NOD两个指标,对数据进行排序和筛选,去除那些对模型训练有害的噪声数据和难以学习的数据。
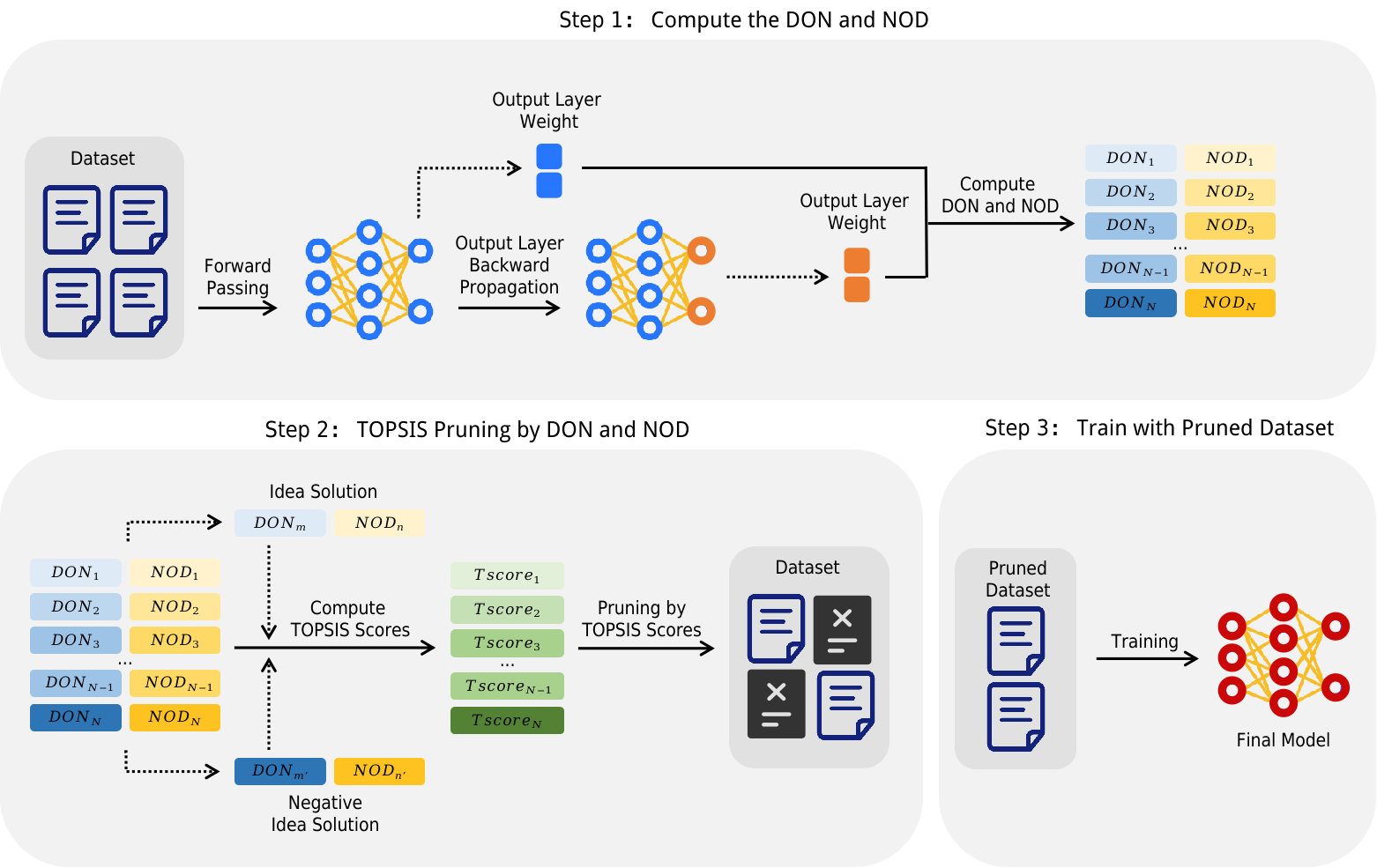
技术框架:DONOD方法主要包含以下几个步骤:1) 计算DON和NOD:对于每个训练样本,计算其对模型权重的影响(DON)和权重的不稳定性(NOD)。DON衡量了样本对模型参数范数的影响程度,NOD衡量了样本训练后模型参数变化的剧烈程度。2) TOPSIS排序:利用TOPSIS算法,根据DON和NOD两个指标对所有训练样本进行排序。TOPSIS算法是一种多属性决策方法,可以综合考虑多个指标,选出最接近理想解的方案。3) 数据剪枝:根据TOPSIS的排序结果,选择排名靠前的样本作为微调数据,去除排名靠后的样本。
关键创新:DONOD的关键创新在于提出了一种基于模型内禀参数的数据剪枝方法,无需依赖额外的辅助模型或数据集。与传统的基于数据特征或模型预测结果的数据选择方法不同,DONOD直接利用模型自身的参数来评估数据质量,更加高效和准确。此外,DONOD方法具有数据集无关性,可以应用于各种不同的数据集和任务。
关键设计:DONOD的关键设计包括:1) DON和NOD的计算方法:DON定义为训练前后模型权重范数的变化量,NOD定义为训练前后模型权重变化的范数。2) TOPSIS算法的参数设置:需要设置DON和NOD两个指标的权重,以及理想解和负理想解的定义。3) 数据剪枝的比例:需要确定剪枝的数据比例,这会影响微调的效率和性能。论文中通过实验确定了最佳的剪枝比例。
🖼️ 关键图片
📊 实验亮点
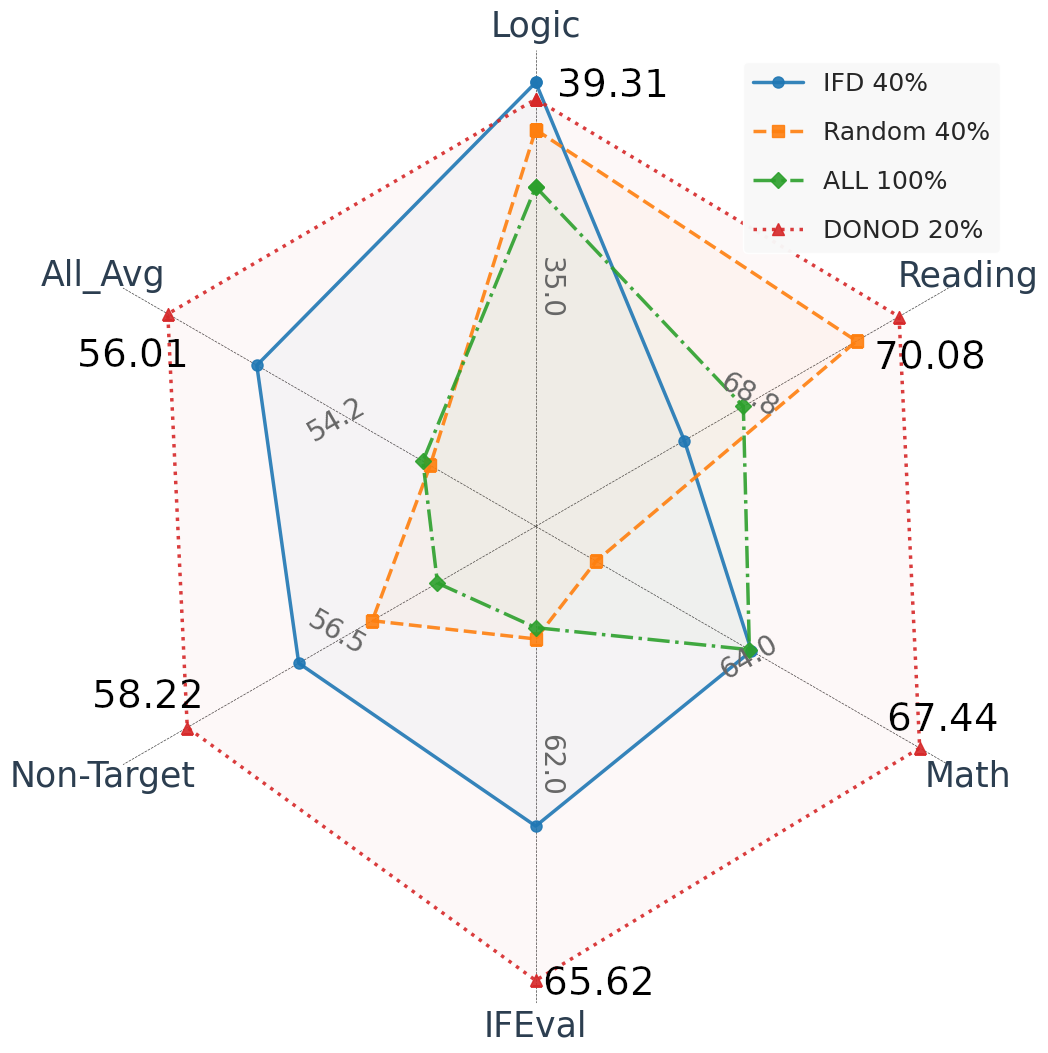
实验结果表明,DONOD方法在数学任务上取得了显著的性能提升。通过过滤70%的数据,目标域准确率提升了14.90%,跨域准确率提升了5.67%。此外,DONOD方法还具有良好的跨架构泛化能力,小模型剪枝的数据可以有效泛化到大模型。与现有方法相比,DONOD在保持或超越性能的同时,具有数据集无关性,适用性更广。
🎯 应用场景
DONOD方法可以广泛应用于各种需要指令微调的大语言模型应用场景,例如特定领域的知识问答、文本生成、对话系统等。该方法能够提高模型在特定领域的性能,并增强其对噪声数据的鲁棒性,从而提升用户体验。此外,DONOD方法还可以用于降低微调的计算成本,提高微调效率,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Ad-hoc instruction fine-tuning of large language models (LLMs) is widely adopted for domain-specific adaptation. While domain-specific supervised fine-tuning (SFT) is effective and efficient, it often weakens cross-domain generalization and struggles with noisy training data. To address these challenges, we propose DONOD, a lightweight model-intrinsic data pruning method. Our approach evaluates data using two model-parameter-based metrics: Delta of Norm (DON), which captures the cumulative influence on model weights, and Norm of Delta (NOD), which quantifies weight instability. Moreover, by employing the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) algorithm, we effectively filter noisy, unlearnable, and generalization-harming samples without relying on auxiliary models during the SFT process. Experiments on mathematical tasks demonstrate that data selected by DONOD achieves superior fine-tuning efficiency and improved robustness against noisy data. By filtering out 70% of the whole dataset, we improve target-domain accuracy by 14.90% and cross-domain accuracy by 5.67%. Meanwhile, our selected data present superior cross-architecture generalization. Data pruned by smaller models (e.g., Llama 3.1-8B) generalize effectively on larger models (e.g., Llama 2-13B). Compared to existing related methodologies, DONOD demonstrates comparable or superior performance while remaining dataset-agnostic, enabling broader applicability. Code will be made publicly available.