Learning from Reasoning Failures via Synthetic Data Generation
作者: Gabriela Ben Melech Stan, Estelle Aflalo, Avinash Madasu, Vasudev Lal, Phillip Howard
分类: cs.AI
发布日期: 2025-04-20 (更新: 2026-01-12)
💡 一句话要点
提出基于推理失败分析的合成数据生成方法,提升大模型推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据生成 多模态学习 大型语言模型 推理能力提升 指令调优
📋 核心要点
- 大型多模态模型缺乏高质量的图像-文本配对数据,限制了其推理能力的提升。
- 该方法分析LMM的推理失败案例,自动生成针对性合成数据,以纠正推理缺陷。
- 实验表明,使用该合成数据训练的模型性能优于使用等量真实数据训练的模型。
📝 摘要(中文)
本文提出了一种新的合成数据生成方法,旨在提升大型多模态模型(LMMs)的推理能力。该方法受到人类学习方式的启发,通过分析现有LMM的推理失败案例,利用前沿模型自动生成并筛选新的训练样本,从而有针对性地纠正LMM的推理缺陷。作者使用该方法生成了一个包含超过55.3万个样本的大型多模态指令调优数据集,并通过大量实验验证了其有效性。实验结果表明,使用该合成数据训练的模型甚至可以超越使用等量真实数据训练的LMM的性能,突显了针对特定推理失败模式生成合成数据的重要价值。数据集和代码将公开。
🔬 方法详解
问题定义:大型多模态模型(LMMs)在推理能力上存在不足,而高质量的图像-文本配对数据相对稀缺,限制了LMMs的训练和性能提升。现有合成数据生成方法缺乏针对性,无法有效解决LMMs的特定推理缺陷。
核心思路:受到人类从错误中学习的启发,该论文的核心思路是分析LMMs的推理失败案例,并生成专门针对这些失败案例的合成数据。通过有针对性地训练,可以更有效地提升LMMs的推理能力。
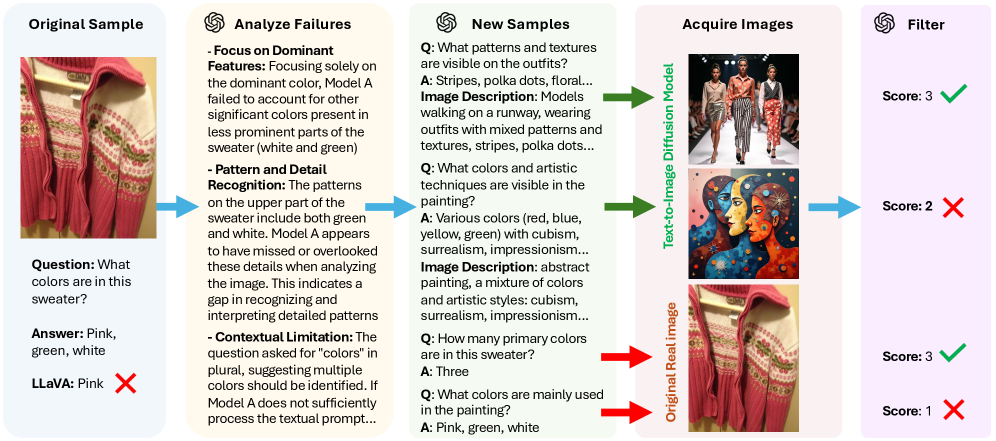
技术框架:该方法包含以下几个主要阶段:1) 使用一个较弱的LMM进行推理,并记录其推理失败的案例;2) 利用更强大的前沿模型(frontier models)分析这些失败案例,识别出导致失败的原因;3) 基于分析结果,前沿模型生成新的、能够纠正这些推理失败的合成数据;4) 对生成的合成数据进行过滤,以确保数据质量。
关键创新:该方法最重要的创新点在于其针对性。与以往的合成数据生成方法不同,该方法不是盲目地生成数据,而是基于对LMMs推理失败的深入分析,生成专门用于纠正这些失败的数据。这种针对性使得合成数据能够更有效地提升LMMs的推理能力。
关键设计:论文中使用了高质量的前沿模型来分析推理失败案例并生成新的数据。数据过滤步骤也至关重要,确保了合成数据的质量。具体的参数设置、损失函数和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
该研究生成了一个包含超过55.3万个样本的大型多模态指令调优数据集。实验结果表明,使用该合成数据训练的模型性能甚至超过了使用等量真实数据训练的LMM,证明了该方法在提升LMM推理能力方面的有效性。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于提升各种大型多模态模型的推理能力,尤其是在数据稀缺的场景下。通过针对性地生成合成数据,可以有效解决模型在特定任务上的弱点,提高其在图像理解、视觉问答、机器人控制等领域的性能。该方法具有广泛的应用前景,能够推动人工智能技术的发展。
📄 摘要(原文)
Training models on synthetic data has emerged as an increasingly important strategy for improving the performance of generative AI. This approach is particularly helpful for large multimodal models (LMMs) due to the relative scarcity of high-quality paired image-text data compared to language-only data. While a variety of methods have been proposed for generating large multimodal datasets, they do not tailor the synthetic data to address specific deficiencies in the reasoning abilities of LMMs which will be trained with the generated dataset. In contrast, humans often learn in a more efficient manner by seeking out examples related to the types of reasoning where they have failed previously. Inspired by this observation, we propose a new approach for synthetic data generation which is grounded in the analysis of an existing LMM's reasoning failures. Our methodology leverages frontier models to automatically analyze errors produced by a weaker LMM and propose new examples which can be used to correct the reasoning failure via additional training, which are then further filtered to ensure high quality. We generate a large multimodal instruction tuning dataset containing over 553k examples using our approach and conduct extensive experiments demonstrating its utility for improving the performance of LMMs on multiple downstream tasks. Our results show that models trained on our synthetic data can even exceed the performance of LMMs trained on an equivalent amount of additional real data, demonstrating the high value of generating synthetic data targeted to specific reasoning failure modes in LMMs. We will make our dataset and code publicly available.