Improving the Serving Performance of Multi-LoRA Large Language Models via Efficient LoRA and KV Cache Management
作者: Hang Zhang, Jiuchen Shi, Yixiao Wang, Quan Chen, Yizhou Shan, Minyi Guo
分类: cs.AR, cs.AI, cs.LG, cs.PF
发布日期: 2025-04-19
💡 一句话要点
FASTLIBRA:通过高效LoRA和KV缓存管理提升多LoRA大语言模型服务性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多LoRA 大语言模型 KV缓存 缓存管理 推理优化 服务性能 低秩适配器
📋 核心要点
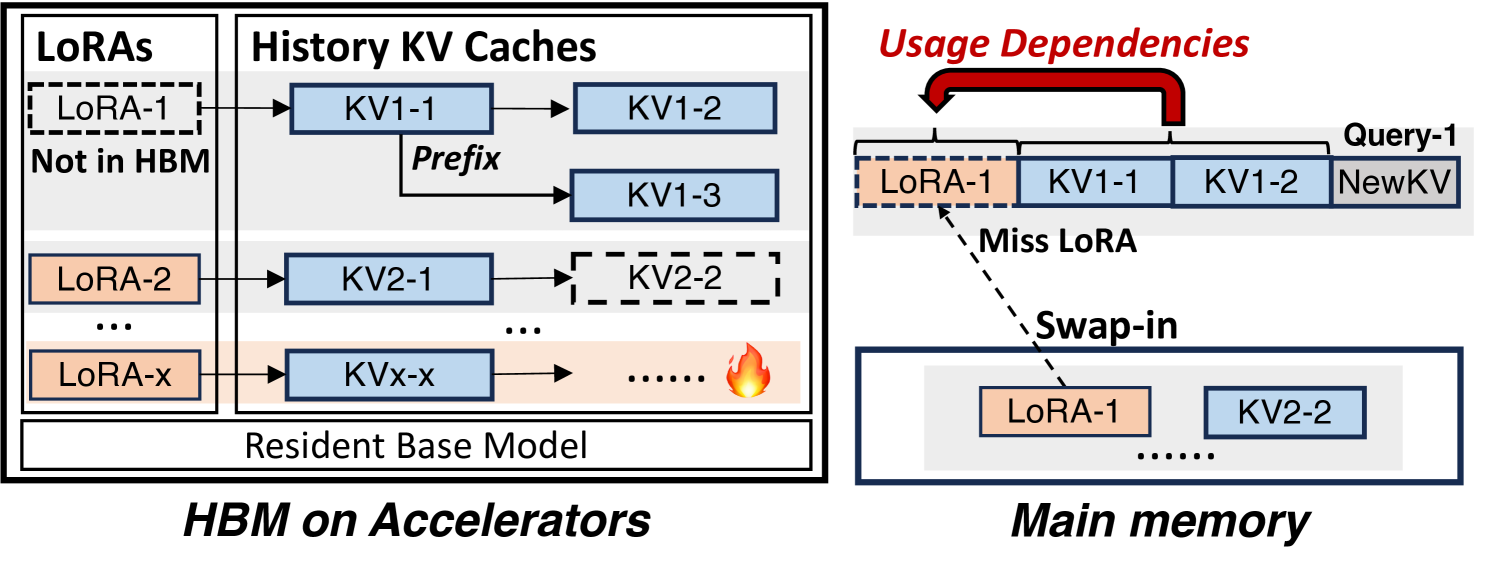
- 现有Multi-LoRA推理系统在缓存LoRA和KV时忽略了使用依赖性,导致服务性能(如TTFT)优化不足。
- FASTLIBRA通过依赖感知缓存管理器和性能驱动缓存交换器,统一管理LoRA和KV缓存,优化服务性能。
- 实验结果表明,FASTLIBRA相比现有技术,平均降低了63.4%的首个token生成时间(TTFT)。
📝 摘要(中文)
多低秩适配器(Multi-LoRA)在特定任务的大语言模型(LLM)应用中越来越受欢迎。对于multi-LoRA服务,将热KV缓存和LoRA适配器缓存在加速器的高带宽内存中可以提高推理性能。然而,现有的Multi-LoRA推理系统未能优化诸如首个token生成时间(TTFT)等服务性能,忽略了缓存LoRA和KV时的使用依赖性。因此,我们提出了FASTLIBRA,一个Multi-LoRA缓存系统,以优化服务性能。FASTLIBRA包含一个依赖感知缓存管理器和一个性能驱动缓存交换器。缓存管理器在推理过程中维护LoRA和KV缓存之间的使用依赖性,并使用统一的缓存池。当HBM空闲或繁忙时,缓存交换器分别基于统一的成本模型确定LoRA和KV缓存的换入或换出。实验结果表明,与最先进的工作相比,ELORA平均降低了63.4%的TTFT。
🔬 方法详解
问题定义:现有的Multi-LoRA serving系统在优化服务性能,特别是Time-To-First-Token (TTFT)方面存在不足。它们忽略了LoRA适配器和KV缓存之间的使用依赖关系,导致缓存策略效率低下,无法充分利用高带宽内存(HBM)的优势。因此,如何高效地管理和调度LoRA适配器和KV缓存,以最小化TTFT,是本论文要解决的核心问题。
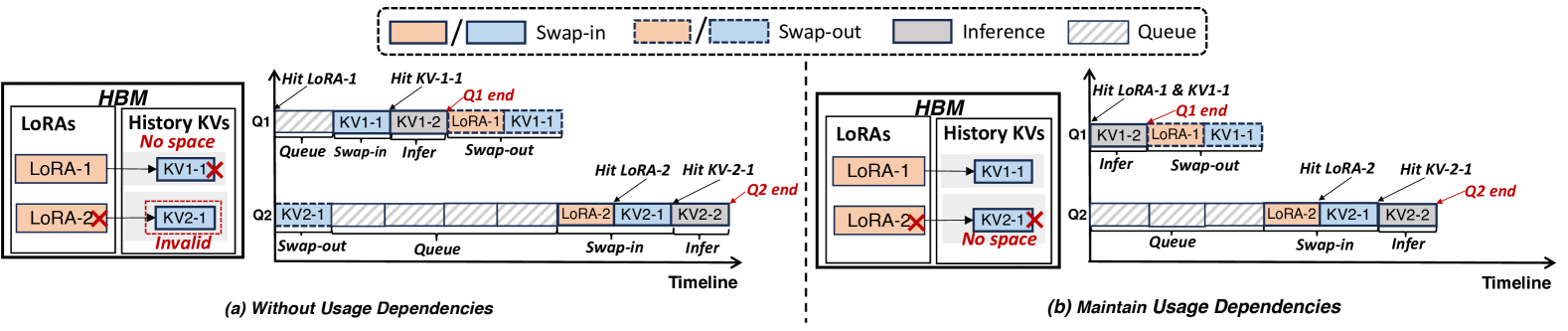
核心思路:FASTLIBRA的核心思路是建立一个依赖感知的缓存管理机制,同时考虑LoRA适配器和KV缓存的使用依赖性。通过统一的缓存池和成本模型,动态地调整LoRA和KV缓存的换入换出,从而优化整体的推理性能。这种方法旨在充分利用HBM的带宽,减少数据传输的开销。
技术框架:FASTLIBRA包含两个主要模块:依赖感知缓存管理器和性能驱动缓存交换器。依赖感知缓存管理器负责跟踪LoRA和KV缓存之间的使用关系,并维护一个统一的缓存池。性能驱动缓存交换器则根据HBM的繁忙程度,基于统一的成本模型,决定LoRA和KV缓存的换入或换出。整体流程是,在推理过程中,缓存管理器记录LoRA和KV的使用情况,缓存交换器根据HBM状态和成本模型,动态调整缓存内容。
关键创新:FASTLIBRA的关键创新在于其依赖感知的缓存管理和性能驱动的缓存交换策略。与现有方法不同,FASTLIBRA不仅考虑了LoRA和KV缓存的独立重要性,还考虑了它们之间的依赖关系,从而更有效地利用HBM资源。此外,统一的成本模型能够根据HBM的繁忙程度,动态调整缓存策略,进一步优化性能。
关键设计:FASTLIBRA的关键设计包括:1) 依赖关系图的构建和维护,用于跟踪LoRA和KV缓存之间的使用关系;2) 统一的成本模型,用于评估LoRA和KV缓存的换入换出代价,该模型可能考虑了访问频率、大小、依赖关系等因素;3) 缓存交换器的调度策略,根据HBM状态和成本模型,决定何时以及如何进行缓存交换。具体的参数设置和损失函数等细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
📊 实验亮点
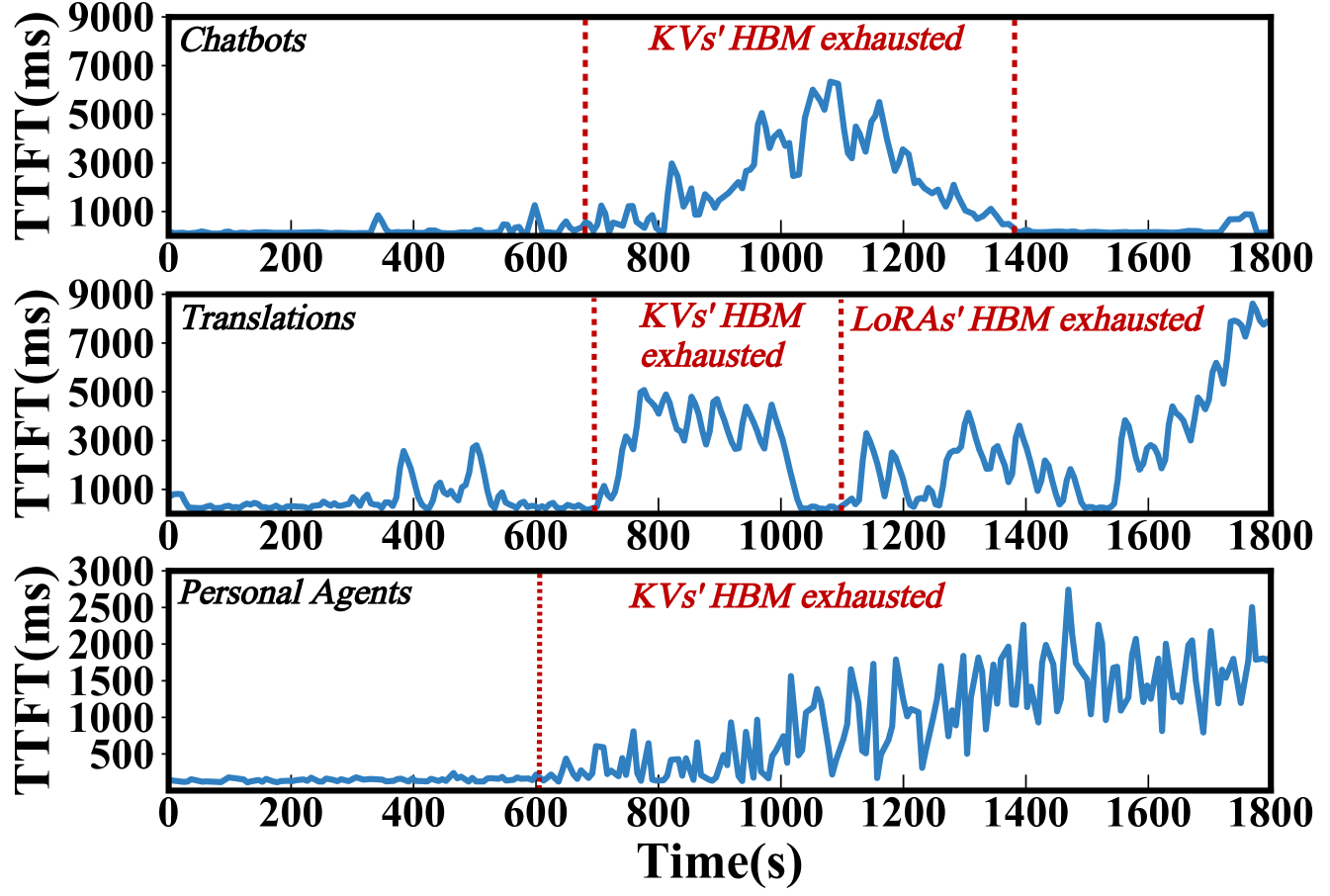
实验结果表明,FASTLIBRA在首个token生成时间(TTFT)上取得了显著的性能提升,平均降低了63.4%,优于现有技术。这一结果验证了FASTLIBRA在优化多LoRA大语言模型服务性能方面的有效性。具体的实验设置和对比基线在论文中应该有详细描述。
🎯 应用场景
FASTLIBRA适用于需要快速响应和高吞吐量的多任务大语言模型服务场景,例如智能客服、对话式AI和个性化推荐系统。通过优化LoRA和KV缓存管理,可以显著提升用户体验,降低服务延迟,并提高硬件资源的利用率。该研究成果有望推动多LoRA大语言模型在实际应用中的广泛部署。
📄 摘要(原文)
Multiple Low-Rank Adapters (Multi-LoRAs) are gaining popularity for task-specific Large Language Model (LLM) applications. For multi-LoRA serving, caching hot KV caches and LoRA adapters in high bandwidth memory of accelerations can improve inference performance. However, existing Multi-LoRA inference systems fail to optimize serving performance like Time-To-First-Toke (TTFT), neglecting usage dependencies when caching LoRAs and KVs. We therefore propose FASTLIBRA, a Multi-LoRA caching system to optimize the serving performance. FASTLIBRA comprises a dependency-aware cache manager and a performance-driven cache swapper. The cache manager maintains the usage dependencies between LoRAs and KV caches during the inference with a unified caching pool. The cache swapper determines the swap-in or out of LoRAs and KV caches based on a unified cost model, when the HBM is idle or busy, respectively. Experimental results show that ELORA reduces the TTFT by 63.4% on average, compared to state-of-the-art works.