Direct Advantage Regression: Aligning LLMs with Online AI Reward
作者: Li He, He Zhao, Stephen Wan, Dadong Wang, Lina Yao, Tongliang Liu
分类: cs.AI, cs.CL, cs.HC
发布日期: 2025-04-19
💡 一句话要点
提出直接优势回归(DAR),利用在线AI奖励对齐LLM,提升人机一致性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型对齐 在线AI反馈 直接优势回归 无强化学习 监督微调
📋 核心要点
- 在线AI反馈(OAIF)旨在替代RLHF,但直接用AI替代人类会使LLM无法学习到二元信号之外的更细粒度的AI监督。
- DAR利用在线AI奖励,通过加权监督微调优化策略改进,无需强化学习,简化了实现并提高了学习效率。
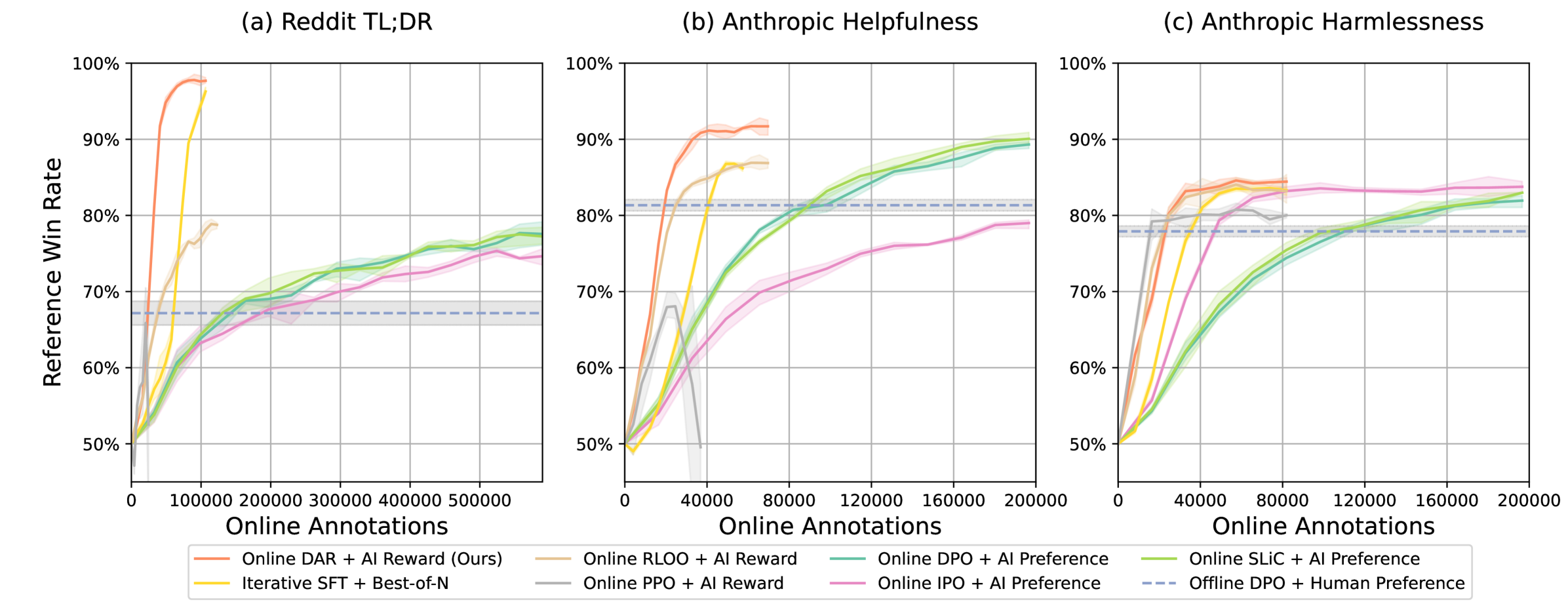
- 实验表明,AI奖励优于AI偏好,能实现更高的人机一致性。DAR在GPT-4-Turbo和MT-bench上优于OAIF和在线RLHF。
📝 摘要(中文)
本文提出了一种名为直接优势回归(DAR)的简单对齐算法,该算法使用在线AI奖励,通过加权监督微调来优化策略改进,从而对齐大型语言模型(LLM)。作为一种无强化学习(RL-free)的方法,DAR在理论上与在线RLHF流程保持一致,同时显著降低了实现复杂性并提高了学习效率。实验结果表明,相对于AI偏好,AI奖励是一种更好的AI监督形式,能够持续实现更高的人机一致性。此外,使用GPT-4-Turbo和MT-bench的评估表明,DAR优于OAIF和在线RLHF基线。
🔬 方法详解
问题定义:现有在线AI反馈方法,如OAIF,虽然尝试用AI偏好代替人类偏好来对齐LLM,但它们提供的监督信号过于粗糙,仅限于二元偏好。这限制了LLM学习更细粒度的AI监督信息,阻碍了模型性能的进一步提升。现有方法无法充分利用AI反馈的潜力。
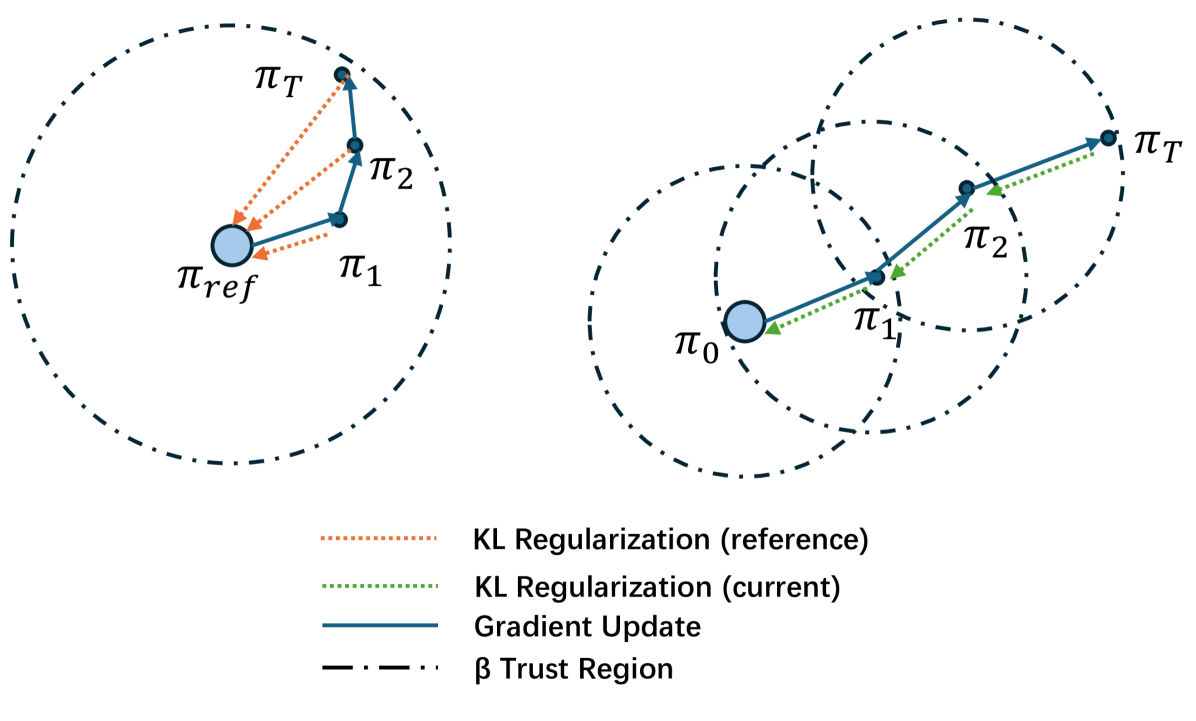
核心思路:DAR的核心思路是利用在线AI奖励,而不是仅仅使用AI偏好,来提供更丰富、更细粒度的监督信号。通过直接回归AI奖励所蕴含的优势函数,DAR能够更有效地引导LLM的策略改进。这种方法避免了复杂的强化学习过程,简化了对齐流程。
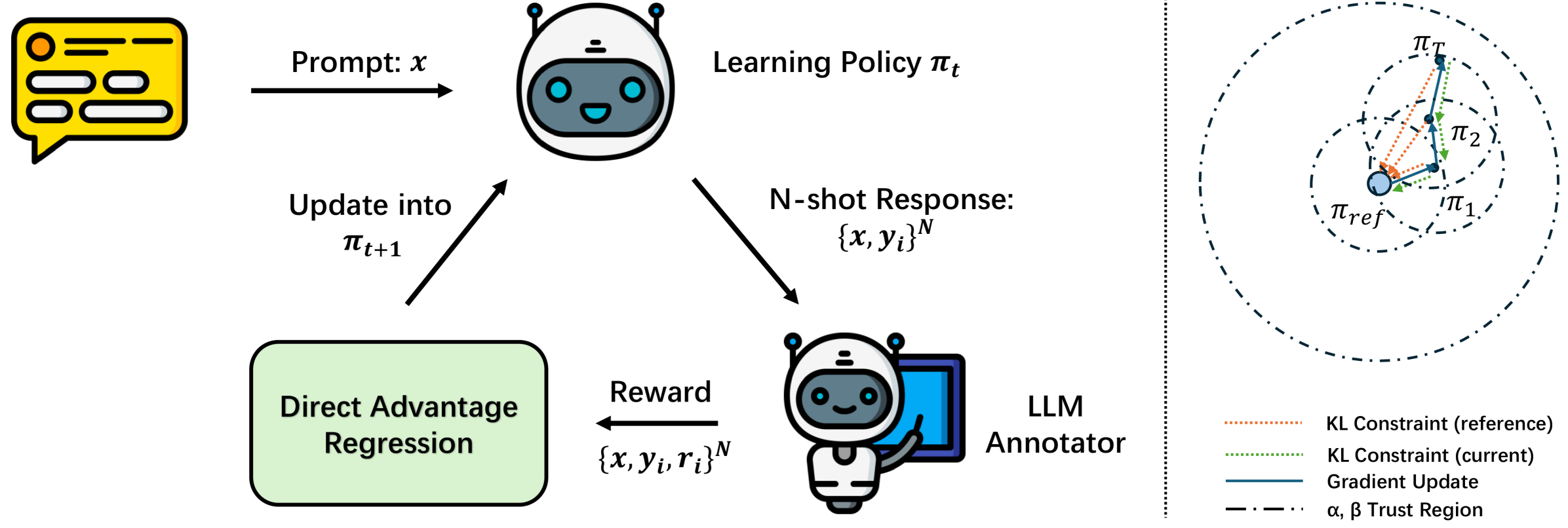
技术框架:DAR的整体框架包括以下几个主要步骤:1) 使用LLM生成文本序列;2) 使用在线AI模型对生成的文本序列进行评估,并给出奖励值;3) 使用这些奖励值计算优势函数;4) 使用加权监督微调,根据优势函数对LLM进行优化。整个过程无需强化学习,是一个纯粹的监督学习流程。
关键创新:DAR最重要的创新点在于直接使用AI奖励进行优势回归,而不是像传统RLHF那样依赖于人类偏好或AI偏好。这种方法能够提供更细粒度的监督信号,从而更有效地引导LLM的策略改进。此外,DAR避免了复杂的强化学习过程,显著降低了实现复杂性。
关键设计:DAR的关键设计包括:1) 优势函数的计算方式,通常采用指数加权平均或其他平滑技术,以减少噪声的影响;2) 加权监督微调的损失函数,通常采用交叉熵损失或均方误差损失,并根据优势函数的值进行加权;3) 微调的学习率和训练轮数等超参数的设置,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DAR在人机一致性方面优于OAIF和在线RLHF基线。具体而言,DAR在GPT-4-Turbo和MT-bench上的评估结果显示,其性能显著优于其他方法。这表明AI奖励是一种比AI偏好更好的监督形式,DAR能够更有效地利用AI反馈来对齐LLM,提升模型性能。
🎯 应用场景
DAR可应用于各种需要对齐LLM的任务,例如对话生成、文本摘要、代码生成等。通过利用在线AI奖励,DAR能够更有效地引导LLM生成符合人类期望的文本,提高生成质量和人机交互体验。此外,DAR的无RL特性使其更易于部署和维护,降低了应用成本,具有广泛的应用前景。
📄 摘要(原文)
Online AI Feedback (OAIF) presents a promising alternative to Reinforcement Learning from Human Feedback (RLHF) by utilizing online AI preference in aligning language models (LLMs). However, the straightforward replacement of humans with AI deprives LLMs from learning more fine-grained AI supervision beyond binary signals. In this paper, we propose Direct Advantage Regression (DAR), a simple alignment algorithm using online AI reward to optimize policy improvement through weighted supervised fine-tuning. As an RL-free approach, DAR maintains theoretical consistency with online RLHF pipelines while significantly reducing implementation complexity and improving learning efficiency. Our empirical results underscore that AI reward is a better form of AI supervision consistently achieving higher human-AI agreement as opposed to AI preference. Additionally, evaluations using GPT-4-Turbo and MT-bench show that DAR outperforms both OAIF and online RLHF baselines.