TALES: Text Adventure Learning Environment Suite
作者: Christopher Zhang Cui, Xingdi Yuan, Ziang Xiao, Prithviraj Ammanabrolu, Marc-Alexandre Côté
分类: cs.AI, cs.CL
发布日期: 2025-04-19 (更新: 2025-04-24)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
TALES:用于评估LLM推理能力的文本冒险学习环境套件
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本冒险游戏 大型语言模型 推理能力 序列决策 人工智能
📋 核心要点
- 现有大型语言模型在复杂任务中,缺乏对上下文历史的结构化推理能力,难以进行有效的序列决策。
- TALES套件通过提供多样化的文本冒险游戏,旨在挑战和评估LLM在复杂环境下的推理能力。
- 实验结果表明,LLM在合成游戏上表现良好,但在人类设计的游戏中表现不佳,表明推理能力仍有提升空间。
📝 摘要(中文)
推理是大型语言模型(LLM)与世界交互的关键能力。随着任务复杂性增加,需要更复杂和多样化的推理能力来进行序列决策,这要求对上下文历史进行结构化推理以确定最佳行动。我们推出了TALES,这是一个多样化的合成和人工编写的文本冒险游戏集合,旨在挑战和评估各种推理能力。我们展示了一系列开放和封闭权重LLM的结果,并对表现最佳的模型进行了定性分析。尽管在合成游戏中表现出色,但即使是顶级的LLM驱动的智能体在专为人类设计的游戏中也未能达到15%的成功率。代码和实验可视化可在https://microsoft.github.io/tale-suite 找到。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂文本冒险游戏中推理能力不足的问题。现有方法在处理需要长期记忆、复杂逻辑和规划的任务时表现不佳,尤其是在人类设计的游戏中,LLM难以理解人类的意图和常识。
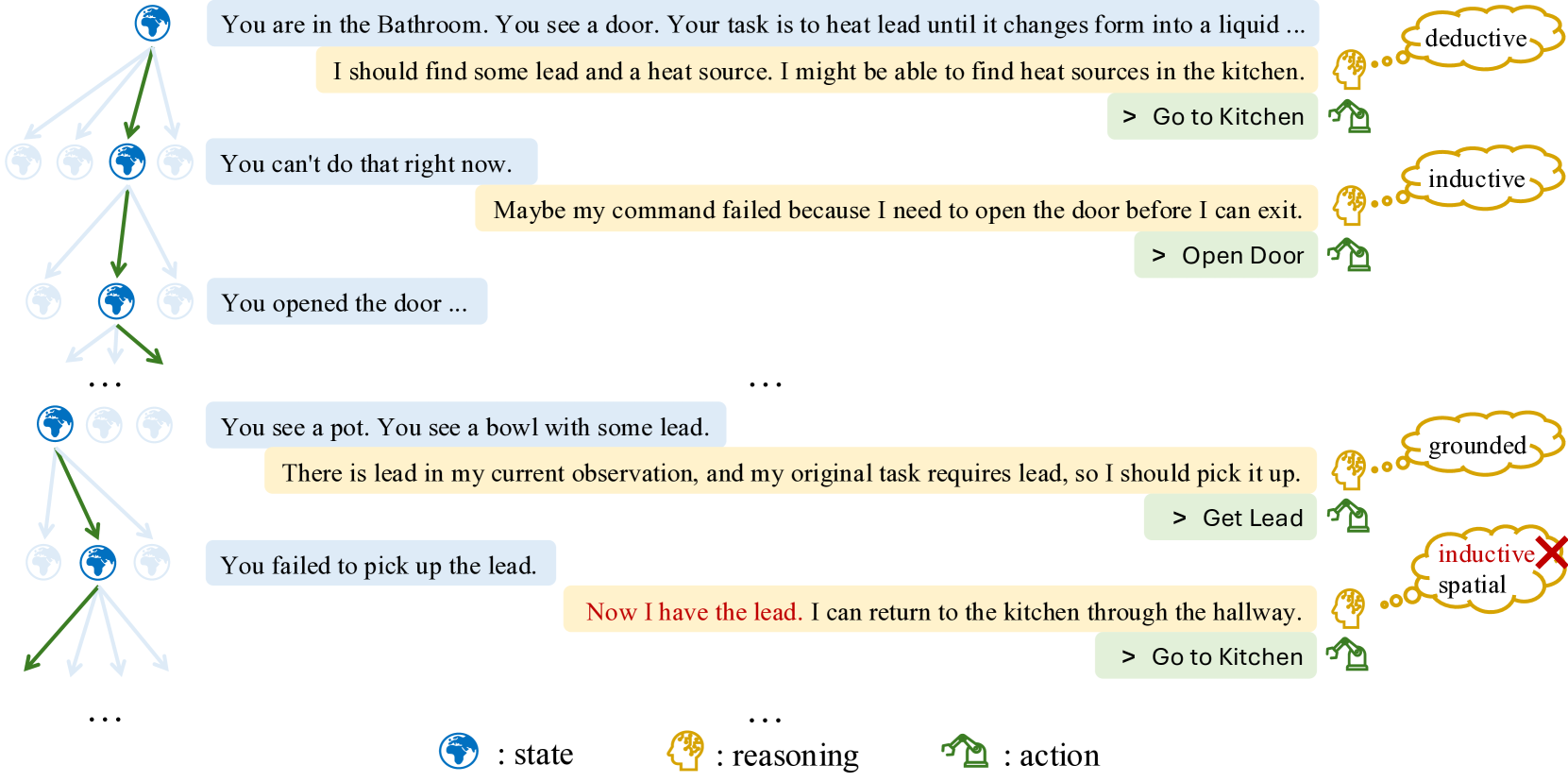
核心思路:论文的核心思路是构建一个多样化的文本冒险游戏环境套件(TALES),该套件包含合成游戏和人类编写的游戏,用于系统性地评估和提高LLM的推理能力。通过在这些游戏中训练和测试LLM,可以更好地了解LLM的优势和局限性,并推动LLM推理能力的提升。
技术框架:TALES套件包含两类游戏:合成游戏和人类编写的游戏。合成游戏旨在测试特定的推理能力,例如目标导向、导航和物品使用。人类编写的游戏更复杂,需要更广泛的推理能力和常识。研究人员使用不同的LLM(包括开源和闭源模型)作为智能体,在这些游戏中进行实验,并评估它们的性能。评估指标包括游戏完成率、得分和行动序列的合理性。
关键创新:TALES套件的关键创新在于其多样性和系统性。它不仅包含合成游戏,还包含人类编写的游戏,从而可以更全面地评估LLM的推理能力。此外,TALES套件还提供了一个标准化的评估平台,方便研究人员比较不同LLM的性能,并推动该领域的研究进展。
关键设计:TALES套件的设计考虑了以下关键因素:游戏的多样性(涵盖不同的推理能力)、游戏的难度(从简单到复杂)、评估指标的合理性(能够准确反映LLM的推理能力)以及平台的易用性(方便研究人员使用和扩展)。具体的技术细节包括游戏生成算法、LLM智能体的实现方式以及评估指标的定义。
🖼️ 关键图片

📊 实验亮点
实验结果表明,尽管LLM在合成游戏中表现出一定的推理能力,但在人类设计的游戏中,即使是顶级的LLM驱动的智能体也未能达到15%的成功率。这表明LLM在处理复杂、非结构化的环境时仍然面临挑战,需要进一步的研究和改进。该研究为LLM推理能力的评估和提升提供了重要的参考。
🎯 应用场景
该研究成果可应用于开发更智能的对话系统、游戏AI和自动化任务规划系统。通过提高LLM在文本冒险游戏中的推理能力,可以使其更好地理解和响应人类的指令,从而在更广泛的领域中发挥作用。例如,可以应用于智能客服、虚拟助手和自动化流程管理等。
📄 摘要(原文)
Reasoning is an essential skill to enable Large Language Models (LLMs) to interact with the world. As tasks become more complex, they demand increasingly sophisticated and diverse reasoning capabilities for sequential decision-making, requiring structured reasoning over the context history to determine the next best action. We introduce TALES, a diverse collection of synthetic and human-written text-adventure games designed to challenge and evaluate diverse reasoning capabilities. We present results over a range of LLMs, open- and closed-weights, performing a qualitative analysis on the top performing models. Despite an impressive showing on synthetic games, even the top LLM-driven agents fail to achieve 15% on games designed for human enjoyment. Code and visualization of the experiments can be found at https://microsoft.github.io/tale-suite.