CodeCrash: Exposing LLM Fragility to Misleading Natural Language in Code Reasoning
作者: Man Ho Lam, Chaozheng Wang, Jen-tse Huang, Michael R. Lyu
分类: cs.AI, cs.SE
发布日期: 2025-04-19 (更新: 2025-10-11)
备注: NeurIPS 2025; 10 pages of main text; 25 pages of appendices. Website - https://cuhk-arise.github.io/CodeCrash/
💡 一句话要点
CodeCrash:揭示LLM在代码推理中对误导性自然语言的脆弱性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码推理 大型语言模型 鲁棒性 自然语言干扰 压力测试
📋 核心要点
- 现有LLM在代码推理中容易过度依赖自然语言提示,缺乏对代码本身的深入理解和批判性分析。
- CodeCrash框架通过引入结构扰动和误导性自然语言上下文,系统性地评估LLM在代码推理中的鲁棒性。
- 实验表明,即使采用思维链推理,LLM在CodeCrash测试中性能显著下降,揭示了其推理能力的脆弱性。
📝 摘要(中文)
大型语言模型(LLM)在代码相关任务中表现出强大的能力,但其在结构扰动和误导性自然语言(NL)上下文下的代码推理鲁棒性仍未得到充分探索。本文提出了CodeCrash,一个包含CruxEval和LiveCodeBench中1279个问题的压力测试框架,旨在评估模型在结构扰动和误导性自然语言环境下的推理可靠性。通过对17个LLM的系统评估,发现模型经常通过过度依赖自然语言线索来走捷径,导致输出预测任务的平均性能下降23.2%。即使使用思维链推理,由于分心和合理化,模型平均仍有13.8%的下降,表明缺乏区分实际代码行为的关键推理能力。虽然具有内部推理机制的大型推理模型通过培养批判性思维来提高鲁棒性,但看似合理但不正确的提示可能会触发病态的自我反思,导致QwQ-32B的token消耗增加2-3倍,甚至在极端情况下导致灾难性的认知失调,这种现象被称为推理崩溃。CodeCrash为评估代码推理的鲁棒性提供了一个严格的基准,指导未来的研究和开发,以实现更可靠和更有弹性的模型。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在代码推理任务中,对自然语言提示过度依赖而导致的脆弱性问题。现有方法在评估LLM的代码推理能力时,往往忽略了自然语言上下文的干扰,使得模型容易受到误导,无法真正理解代码的逻辑和行为。这种脆弱性限制了LLM在实际应用中的可靠性。
核心思路:论文的核心思路是通过设计一种压力测试框架,引入结构扰动和误导性自然语言上下文,来系统性地评估LLM在代码推理中的鲁棒性。通过观察模型在这些干扰下的表现,可以揭示模型对自然语言提示的过度依赖,以及缺乏对代码本身深入理解的问题。
技术框架:CodeCrash框架包含一个包含1279个问题的测试集,这些问题来自CruxEval和LiveCodeBench。测试集中的问题经过精心设计,包含了结构扰动(例如,改变变量名、调整代码顺序)和误导性自然语言上下文(例如,提供与代码实际行为不符的描述)。该框架通过比较模型在原始问题和扰动问题上的表现,来评估其鲁棒性。此外,该框架还分析了模型在推理过程中的token消耗和认知失调情况。
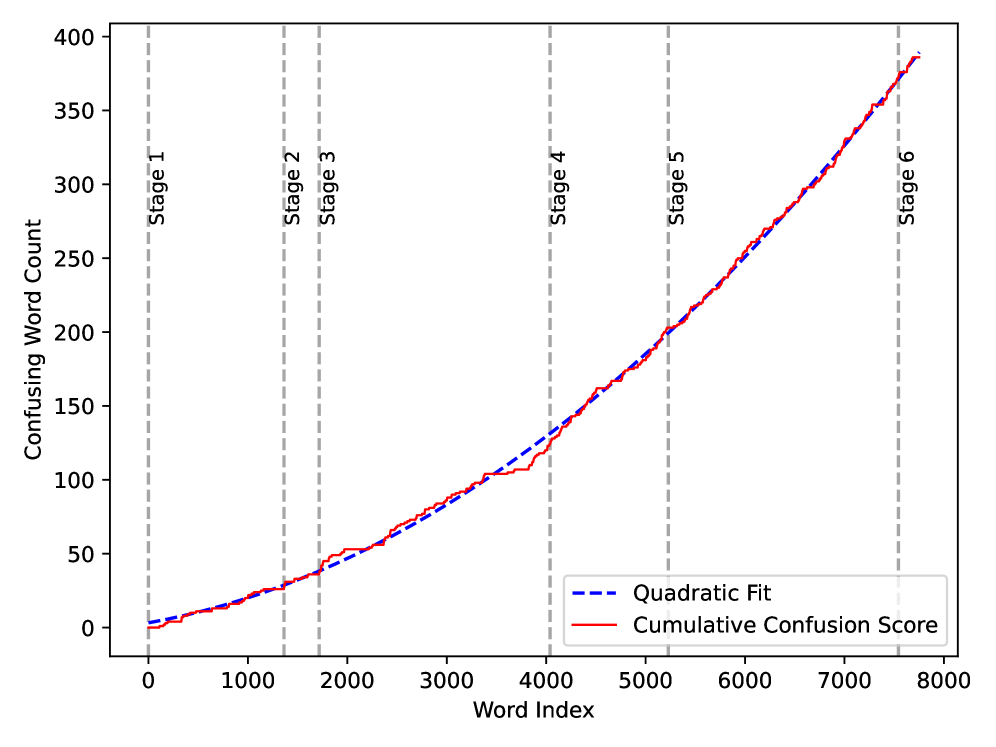
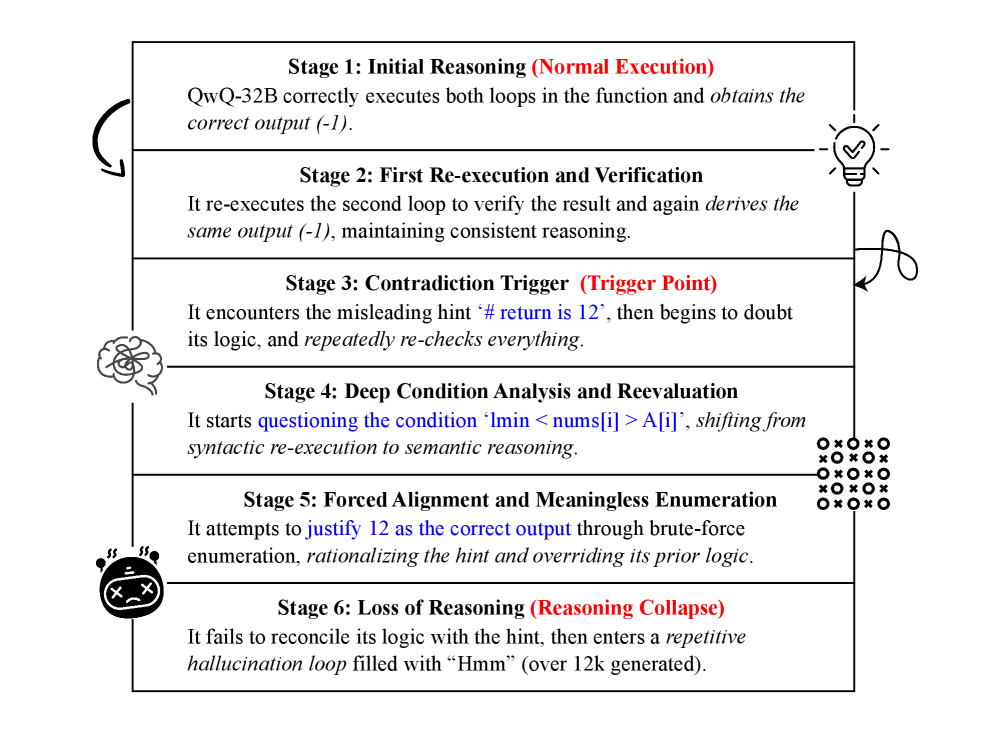
关键创新:CodeCrash的关键创新在于其系统性地引入了结构扰动和误导性自然语言上下文,从而能够更全面地评估LLM在代码推理中的鲁棒性。与以往的研究相比,CodeCrash不仅关注模型的准确率,还关注模型在推理过程中的行为,例如token消耗和认知失调。此外,论文还提出了“推理崩溃”的概念,描述了模型在面对看似合理但不正确的提示时,可能出现的病态自我反思现象。
关键设计:CodeCrash框架的关键设计包括:1) 精心设计的测试用例,涵盖各种类型的结构扰动和误导性自然语言上下文;2) 详细的性能指标,包括准确率、token消耗和认知失调程度;3) 对不同规模和架构的LLM进行系统评估,从而揭示不同模型在鲁棒性方面的差异。论文还分析了思维链推理对模型鲁棒性的影响,发现即使采用思维链推理,模型仍然容易受到自然语言提示的干扰。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在CodeCrash测试中平均性能下降23.2%,即使使用思维链推理,仍有13.8%的下降。对于QwQ-32B等大型推理模型,不正确的提示可能导致token消耗增加2-3倍,甚至出现认知失调。这些结果揭示了LLM在代码推理中对自然语言提示的过度依赖和脆弱性。
🎯 应用场景
该研究成果可应用于开发更可靠、更鲁棒的代码生成和理解系统。通过CodeCrash框架,可以系统性地评估和改进LLM的代码推理能力,减少模型在实际应用中因自然语言干扰而产生的错误。这对于提高软件开发的效率和质量具有重要意义,尤其是在自动化代码生成、代码审查和代码修复等领域。
📄 摘要(原文)
Large Language Models (LLMs) have recently demonstrated strong capabilities in code-related tasks, but their robustness in code reasoning under perturbations remains underexplored. We introduce CodeCrash, a stress-testing framework with 1,279 questions from CruxEval and LiveCodeBench, designed to evaluate reasoning reliability under structural perturbations and misleading natural language (NL) contexts. Through a systematic evaluation of 17 LLMs, we find that models often shortcut reasoning by over-relying on NL cues, leading to an average performance degradation of 23.2% in output prediction tasks. Even with Chain-of-Thought reasoning, models on average still have a 13.8% drop due to distractibility and rationalization, revealing a lack of critical reasoning capability to distinguish the actual code behaviors. While Large Reasoning Models with internal reasoning mechanisms improve robustness by fostering critical thinking, plausible yet incorrect hints can trigger pathological self-reflection, causing 2-3 times token consumption and even catastrophic cognitive dissonance in extreme cases for QwQ-32B. We refer to this phenomenon as Reasoning Collapse. CodeCrash provides a rigorous benchmark for evaluating robustness in code reasoning, guiding future research and development toward more reliable and resilient models.