Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
作者: Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, Gao Huang
分类: cs.AI, cs.CL, cs.CV
发布日期: 2025-04-18 (更新: 2025-11-24)
备注: 31 pages, 27 figures
期刊: NeurIPS 2025 Oral; ICML 2025 AI4MATH workshop best paper
💡 一句话要点
研究表明:基于可验证奖励的强化学习未能显著提升LLM的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 推理能力 可验证奖励 蒸馏学习
📋 核心要点
- 现有基于可验证奖励的强化学习(RLVR)被认为能提升LLM推理能力,但其有效性缺乏充分验证。
- 论文通过系统性实验,探究RLVR训练的LLM在不同任务和算法下的推理能力边界。
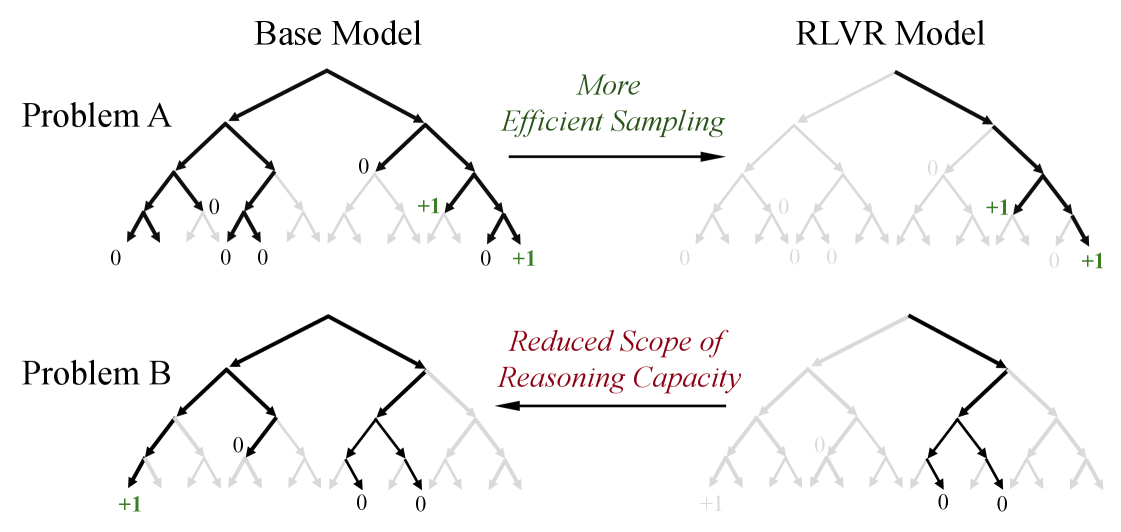
- 实验结果表明,RLVR训练的模型并未展现超越基础模型的根本性新推理模式,蒸馏方法表现更优。
📝 摘要(中文)
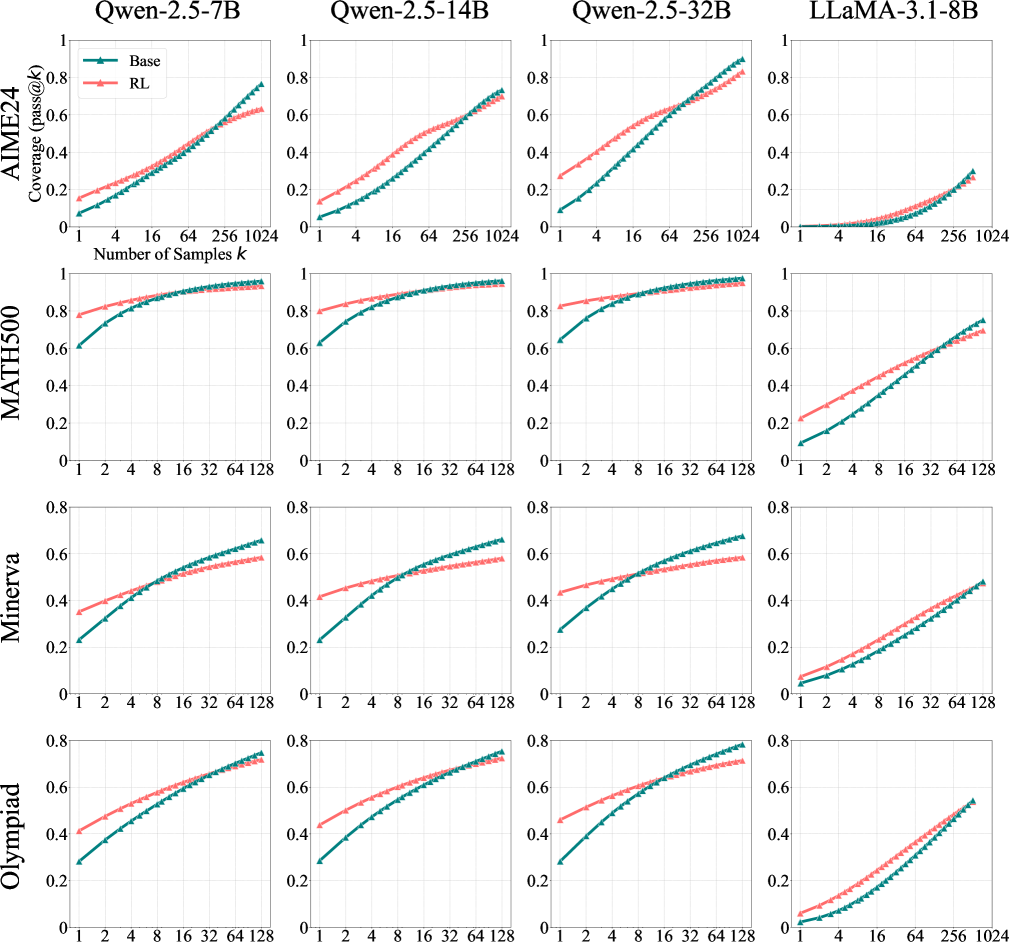
最近,基于可验证奖励的强化学习(RLVR)在提升大型语言模型(LLM)的推理性能方面取得了显著成功,尤其是在数学和编程任务上。类似于传统强化学习帮助智能体探索和学习新策略的方式,RLVR被认为能够使LLM持续自我改进,从而获得超越其对应基础模型的新推理能力。本研究通过系统地探究RLVR训练的LLM在各种模型家族、强化学习算法以及数学、编程和视觉推理基准测试中的推理能力边界,严格审查了当前RLVR的状态,使用大k值的pass@k作为评估指标。令人惊讶的是,我们发现当前的训练设置并没有引发根本性的新推理模式。虽然RLVR训练的模型在小k值(例如,k = 1)时优于其基础模型,但基础模型在k值较大时实现了更高的pass@k分数。覆盖率和困惑度分析表明,观察到的推理能力源于基础模型并受其限制。将基础模型视为上限,我们的定量分析表明,六种流行的RLVR算法表现相似,并且在利用基础模型的潜力方面远未达到最佳状态。相比之下,我们发现蒸馏可以从教师模型中引入新的推理模式,并真正扩展模型的推理能力。总的来说,我们的研究结果表明,当前的RLVR方法尚未实现强化学习在LLM中引发真正新颖的推理能力的潜力。这突显了对改进的强化学习范例的需求,例如持续扩展和多轮智能体-环境交互,以释放这种潜力。
🔬 方法详解
问题定义:论文旨在解决现有基于可验证奖励的强化学习(RLVR)方法是否真正能够提升大型语言模型(LLM)的推理能力,使其超越基础模型的问题。现有方法的痛点在于,虽然在某些指标上有所提升,但缺乏对模型推理能力本质的深入分析,无法确定提升是否源于新推理模式的产生。
核心思路:论文的核心思路是通过系统性的实验,使用大k值的pass@k指标,探究RLVR训练的LLM在不同模型家族、强化学习算法以及数学、编程和视觉推理基准测试中的推理能力边界。通过对比RLVR训练模型和基础模型在大k值下的表现,以及分析模型的覆盖率和困惑度,来判断RLVR是否引入了新的推理模式。
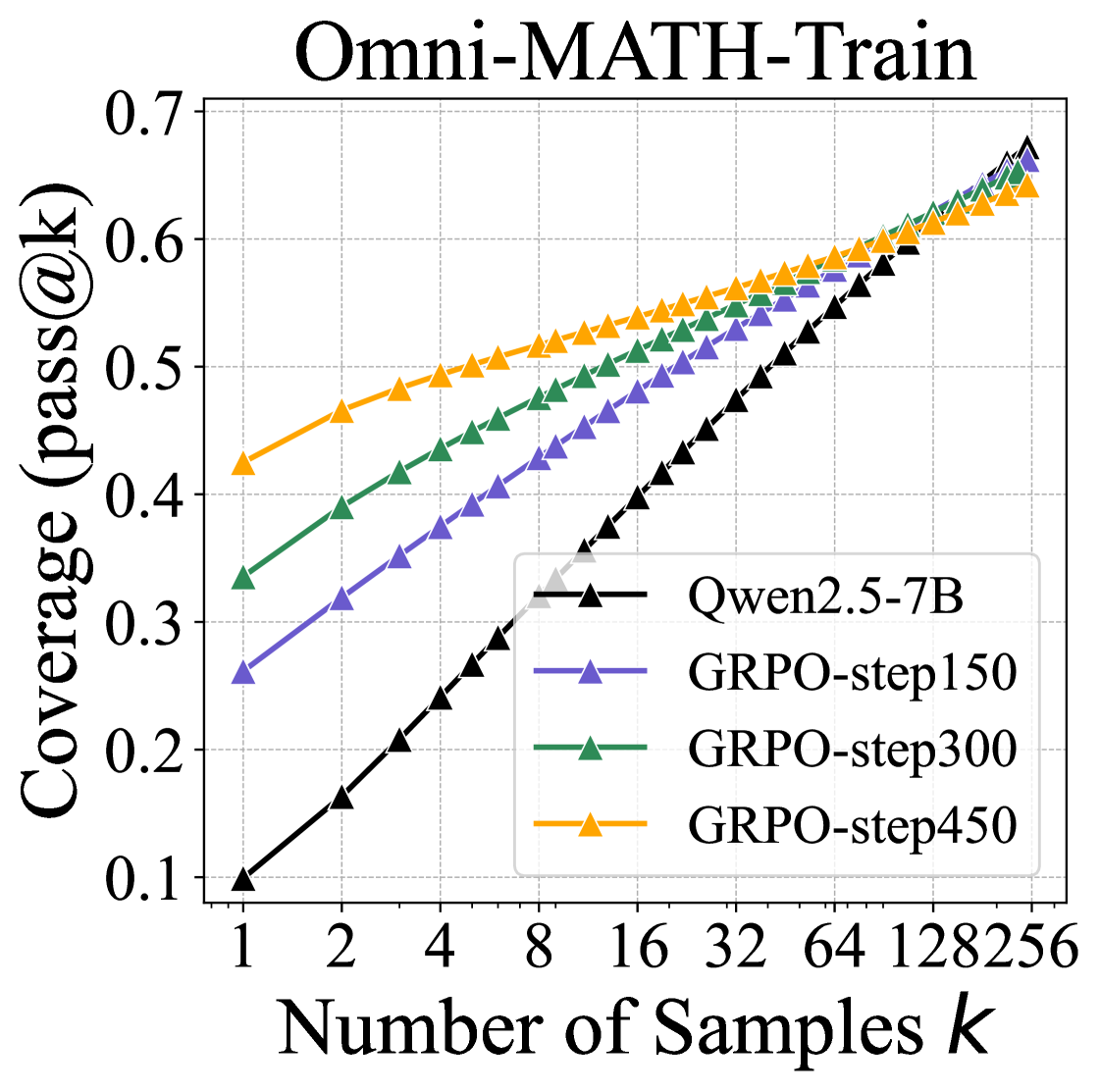
技术框架:论文的技术框架主要包括以下几个部分:1) 选择多种LLM模型家族和RL算法;2) 在数学、编程和视觉推理等多个基准测试上进行实验;3) 使用pass@k(k取较大值)作为主要评估指标;4) 进行覆盖率和困惑度分析,以评估模型生成的多样性和流畅性;5) 将RLVR训练的模型与基础模型以及通过蒸馏训练的模型进行比较。
关键创新:论文最重要的技术创新点在于对RLVR效果的质疑和验证方式。以往研究主要关注小k值的pass@k指标,而该论文关注大k值,从而更严格地评估模型是否产生了新的推理模式。此外,通过覆盖率和困惑度分析,更深入地理解了RLVR对模型推理能力的影响。与现有方法的本质区别在于,该论文不是简单地报告性能提升,而是深入分析了提升的来源和本质。
关键设计:论文的关键设计包括:1) 选择了多种具有代表性的LLM模型家族和RL算法,以保证结论的普适性;2) 使用pass@k(k取较大值)作为评估指标,更严格地评估模型是否产生了新的推理模式;3) 进行了覆盖率和困惑度分析,以评估模型生成的多样性和流畅性;4) 将RLVR训练的模型与基础模型以及通过蒸馏训练的模型进行比较,以更全面地评估RLVR的效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,虽然RLVR训练的模型在小k值(例如,k = 1)时优于其基础模型,但基础模型在k值较大时实现了更高的pass@k分数。定量分析表明,六种流行的RLVR算法表现相似,并且在利用基础模型的潜力方面远未达到最佳状态。相比之下,蒸馏可以从教师模型中引入新的推理模式,并真正扩展模型的推理能力。
🎯 应用场景
该研究成果对未来LLM的训练和优化具有重要指导意义。它表明,当前的RLVR方法可能无法有效提升LLM的推理能力,需要探索新的强化学习范式,例如持续扩展和多轮智能体-环境交互。此外,该研究也提示研究者们在评估LLM的推理能力时,应采用更严格的评估指标和更深入的分析方法。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated notable success in enhancing the reasoning performance of large language models (LLMs), particularly on mathematics and programming tasks. Similar to how traditional RL helps agents explore and learn new strategies, RLVR is believed to enable LLMs to continuously self-improve, thus acquiring novel reasoning abilities beyond those of the corresponding base models. In this study we critically examine the current state of RLVR by systematically probing the reasoning capability boundaries of RLVR-trained LLMs across various model families, RL algorithms, and math, coding, and visual reasoning benchmarks, using pass@k at large k values as the evaluation metric. Surprisingly, we find that the current training setup does not elicit fundamentally new reasoning patterns. While RLVR-trained models outperform their base models at small k (e.g., k = 1), the base models achieve a higher pass@k score when k is large. Coverage and perplexity analyses show that the observed reasoning abilities originate from and are bounded by the base model. Treating the base model as an upper bound, our quantitative analysis shows that six popular RLVR algorithms perform similarly and remain far from optimal in leveraging the potential of the base model. By contrast, we find that distillation can introduce new reasoning patterns from the teacher and genuinely expand the model's reasoning capabilities. Overall, our findings suggest that current RLVR methods have not yet realized the potential of RL to elicit truly novel reasoning abilities in LLMs. This highlights the need for improved RL paradigms, such as continual scaling and multi-turn agent-environment interaction, to unlock this potential.