Exploring the Potential for Large Language Models to Demonstrate Rational Probabilistic Beliefs
作者: Gabriel Freedman, Francesca Toni
分类: cs.AI, cs.CL
发布日期: 2025-04-18
备注: 8 pages, 4 figures
💡 一句话要点
揭示大型语言模型在理性概率信念表达上的不足
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 概率推理 不确定性量化 理性信念 数据集构建
📋 核心要点
- 现有大型语言模型在概率推理方面表现出不足,无法提供理性和连贯的概率信念表示。
- 论文构建了一个包含不确定真值声明的新数据集,用于评估LLMs的概率推理能力。
- 实验结果表明,当前版本的LLMs在遵守概率推理基本属性方面存在缺陷。
📝 摘要(中文)
大型语言模型(LLMs)的通用能力不断提升,已被广泛应用于信息检索和自动化决策系统。在这些应用中,模型对概率推理的忠实表示至关重要,以确保其性能的可信度、可解释性和有效性。尽管之前的研究表明LLMs能够进行复杂的推理和良好校准的不确定性量化,但我们发现当前版本的LLMs缺乏提供理性和连贯的概率信念表示的能力。为了证明这一点,我们引入了一个包含真值不确定性声明的新数据集,并应用了多种成熟的不确定性量化技术,以评估LLMs是否能遵守概率推理的基本属性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在概率推理方面表现出的非理性问题。现有方法虽然在不确定性量化方面取得了一些进展,但未能保证LLMs能够提供理性和连贯的概率信念表示,这限制了它们在需要可信、可解释决策场景中的应用。
核心思路:论文的核心思路是通过构建一个包含真值不确定性声明的新数据集,并结合成熟的不确定性量化技术,来系统性地评估LLMs是否能够遵守概率推理的基本属性。通过这种方式,可以量化LLMs在概率推理方面的非理性程度。
技术框架:论文的技术框架主要包含以下几个阶段:1) 构建包含不确定真值声明的新数据集;2) 选择并应用多种成熟的不确定性量化技术,例如温度缩放、蒙特卡洛dropout等;3) 使用这些技术来测量LLMs对概率推理基本属性的遵守程度,例如概率的加法规则、条件概率等;4) 分析实验结果,揭示LLMs在概率推理方面的不足。
关键创新:论文的关键创新在于:1) 提出了一个用于评估LLMs概率推理能力的新数据集,该数据集包含具有不确定真值的声明,更贴近现实世界的复杂场景;2) 系统性地应用多种不确定性量化技术,并结合概率推理的基本属性,对LLMs的概率推理能力进行了全面评估;3) 揭示了当前版本的LLMs在概率推理方面存在的缺陷,为未来改进LLMs的推理能力提供了指导。
关键设计:论文的关键设计包括:1) 数据集的构建方式,需要保证声明的真值具有不确定性,并且能够覆盖不同的主题和领域;2) 不确定性量化技术的选择,需要选择能够有效量化LLMs预测结果不确定性的方法;3) 评估指标的设计,需要设计能够量化LLMs对概率推理基本属性遵守程度的指标,例如KL散度、交叉熵等。
🖼️ 关键图片

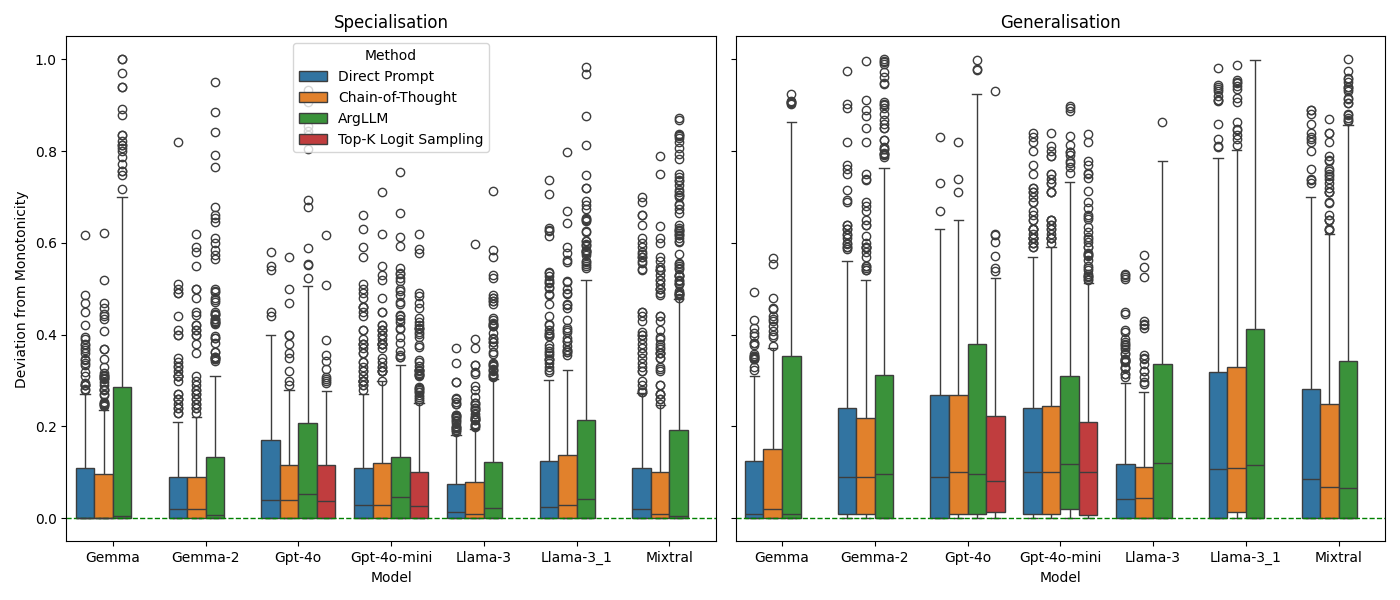
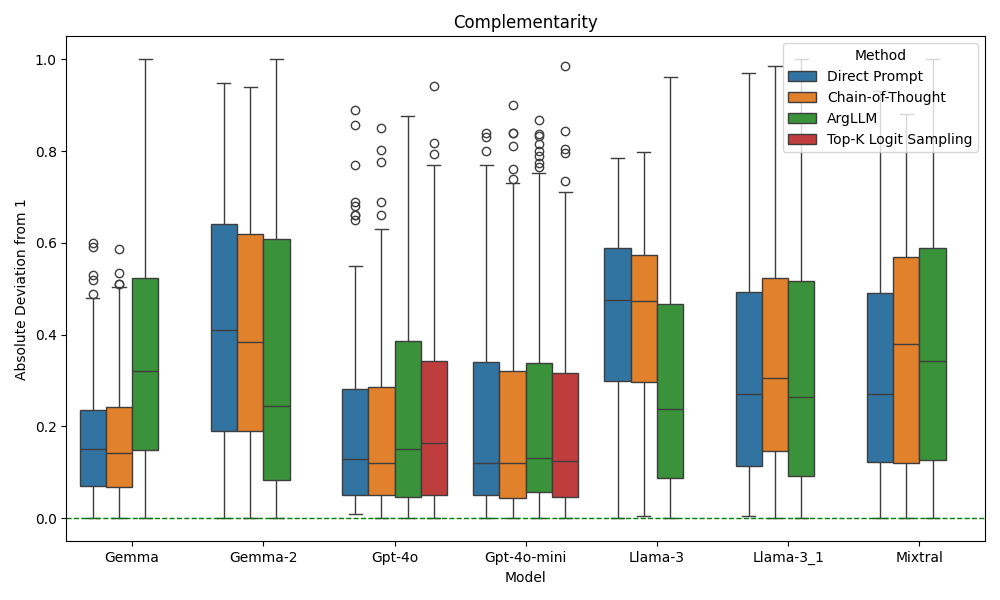
📊 实验亮点
论文通过实验证明,当前版本的LLMs在处理具有不确定真值的声明时,无法提供理性和连贯的概率信念表示。具体而言,实验结果表明LLMs在遵守概率的加法规则、条件概率等方面存在显著偏差,这表明它们在概率推理方面存在根本性的缺陷。这些发现为改进LLMs的推理能力提供了重要的依据。
🎯 应用场景
该研究成果可应用于提升LLMs在信息检索、自动化决策等领域的可靠性和可解释性。通过改进LLMs的概率推理能力,可以使其在医疗诊断、金融风险评估等关键领域做出更明智、更值得信赖的决策。未来的研究可以进一步探索如何将概率推理的约束融入到LLMs的训练过程中,从而提高其理性程度。
📄 摘要(原文)
Advances in the general capabilities of large language models (LLMs) have led to their use for information retrieval, and as components in automated decision systems. A faithful representation of probabilistic reasoning in these models may be essential to ensure trustworthy, explainable and effective performance in these tasks. Despite previous work suggesting that LLMs can perform complex reasoning and well-calibrated uncertainty quantification, we find that current versions of this class of model lack the ability to provide rational and coherent representations of probabilistic beliefs. To demonstrate this, we introduce a novel dataset of claims with indeterminate truth values and apply a number of well-established techniques for uncertainty quantification to measure the ability of LLM's to adhere to fundamental properties of probabilistic reasoning.