CodeVisionary: An Agent-based Framework for Evaluating Large Language Models in Code Generation
作者: Xinchen Wang, Pengfei Gao, Chao Peng, Ruida Hu, Cuiyun Gao
分类: cs.SE, cs.AI, cs.CL, cs.LG
发布日期: 2025-04-18 (更新: 2025-10-20)
🔗 代码/项目: GITHUB
💡 一句话要点
提出CodeVisionary,一个基于Agent的框架,用于评估大语言模型在代码生成方面的能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大语言模型 评估框架 Agent 复杂代码
📋 核心要点
- 现有LLM代码生成评估方法依赖静态提示,难以应对复杂场景,且缺乏细粒度评估,可解释性不足。
- CodeVisionary采用Agent框架,通过需求引导的上下文提炼和细粒度评分,实现对复杂代码生成更全面的评估。
- 实验结果表明,CodeVisionary在评估复杂代码生成方面显著优于现有基线方法,提升了评估的准确性和可信度。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成方面表现出强大的能力,因此迫切需要进行严格而全面的评估。现有的评估方法分为三类,包括以人为中心的方法、基于指标的方法和基于LLM的方法。考虑到以人为中心的方法劳动密集,而基于指标的方法过度依赖参考答案,基于LLM的方法因其更强的上下文理解能力而受到越来越多的关注。然而,它们通常基于静态提示评估生成的代码,并且在复杂的代码场景中容易失败,这些场景通常涉及多个需求并需要更多的上下文信息。此外,这些方法缺乏对复杂代码的细粒度评估,导致可解释性有限。为了缓解这些限制,我们提出了CodeVisionary,这是第一个用于评估复杂代码生成的基于Agent的评估框架。CodeVisionary包括两个阶段:(1)需求引导的多维上下文提炼阶段和(2)细粒度评分和总结阶段。还生成一份全面的评估报告,以增强可解释性。为了验证,我们构建了一个新的基准,包含363个样本,涵盖37个编码场景和23种编程语言。大量的实验表明,CodeVisionary在评估复杂代码生成方面实现了最佳性能,优于最佳基线,在Pearson、Spearman和Kendall-Tau系数方面分别平均提高了0.217、0.163和0.141。CodeVisionary的资源可在https://github.com/Eshe0922/CodeVisionary上找到。
🔬 方法详解
问题定义:现有的大语言模型代码生成评估方法,特别是基于LLM的评估方法,在评估复杂代码生成时存在局限性。它们通常依赖于静态的prompt,无法充分捕捉复杂代码场景中多方面的需求和上下文信息。此外,现有的评估方法缺乏对代码的细粒度分析,难以提供充分的可解释性,从而限制了对LLM代码生成能力的深入理解。
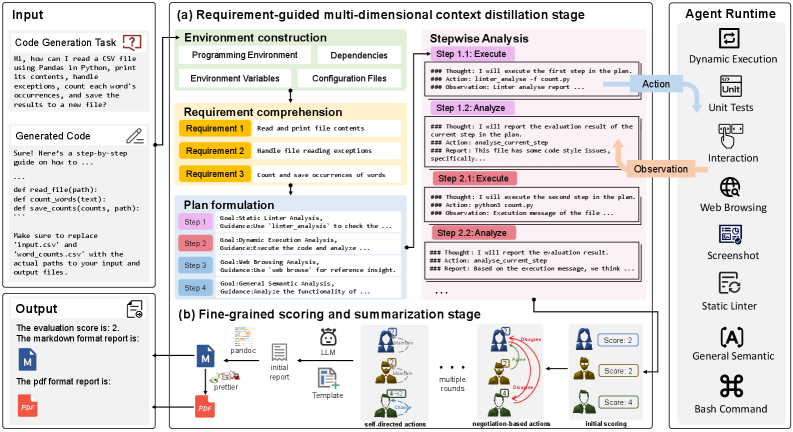
核心思路:CodeVisionary的核心思路是利用Agent的思想,模拟人类专家评估代码的过程。通过构建一个能够理解需求、提炼上下文、细粒度分析代码并给出综合评价的Agent,从而更准确、全面地评估LLM在复杂代码生成方面的能力。这种方法旨在克服现有方法在处理复杂场景和提供可解释性方面的不足。
技术框架:CodeVisionary框架包含两个主要阶段:(1)需求引导的多维上下文提炼阶段:该阶段Agent根据给定的代码生成需求,从多个维度提取相关的上下文信息,例如代码的功能、约束、潜在的错误类型等。这有助于Agent更全面地理解代码的意图。(2)细粒度评分和总结阶段:该阶段Agent对生成的代码进行细粒度的分析和评分,例如代码的正确性、效率、可读性、安全性等。然后,Agent会生成一份综合的评估报告,总结代码的优点和缺点,并给出改进建议。
关键创新:CodeVisionary的关键创新在于其基于Agent的评估框架,它能够模拟人类专家评估代码的过程,从而更准确、全面地评估LLM在复杂代码生成方面的能力。与现有的基于静态prompt的评估方法相比,CodeVisionary能够更好地处理复杂场景,并提供更细粒度的评估结果和更强的可解释性。
关键设计:CodeVisionary的具体实现细节未知,但可以推测其关键设计可能包括:(1) 如何设计Agent的架构,使其能够有效地理解需求、提炼上下文和分析代码。(2) 如何定义细粒度的评分指标,以全面评估代码的各个方面。(3) 如何训练Agent,使其能够准确地评估代码的质量。(4) 如何生成易于理解的评估报告,以帮助用户了解代码的优点和缺点。
🖼️ 关键图片

📊 实验亮点
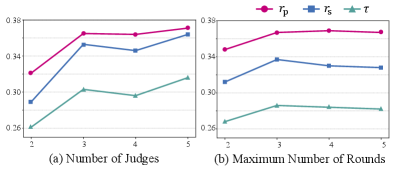
CodeVisionary在包含363个样本的新基准测试中,显著优于现有基线方法。具体而言,在Pearson相关系数上提升了0.217,Spearman相关系数上提升了0.163,Kendall-Tau相关系数上提升了0.141。这些结果表明,CodeVisionary在评估复杂代码生成方面具有显著优势。
🎯 应用场景
CodeVisionary可应用于评估和改进大语言模型在代码生成方面的能力,帮助开发者选择更合适的模型,并指导模型训练过程。此外,该框架还可用于自动化代码评审,提高软件开发的效率和质量。未来,该研究或可扩展到其他类型的代码生成任务,例如自然语言到代码的转换。
📄 摘要(原文)
Large language models (LLMs) have demonstrated strong capabilities in code generation, underscoring the critical need for rigorous and comprehensive evaluation. Existing evaluation approaches fall into three categories, including human-centered, metric-based, and LLM-based. Considering that human-centered approaches are labour-intensive and metric-based ones overly rely on reference answers, LLM-based approaches are gaining increasing attention due to their stronger contextual understanding capabilities. However, they generally evaluate the generated code based on static prompts, and tend to fail for complex code scenarios which typically involve multiple requirements and require more contextual information. In addition, these approaches lack fine-grained evaluation for complex code, resulting in limited explainability. To mitigate the limitations, we propose CodeVisionary, the first agent-based evaluation framework for complex code generation. CodeVisionary consists of two stages: (1) Requirement-guided multi-dimensional context distillation stage and (2) Fine-grained scoring and summarization stage. A comprehensive evaluation report is also generated for enhanced explainability. For validation, we construct a new benchmark consisting of 363 samples spanning 37 coding scenarios and 23 programming languages. Extensive experiments demonstrate that CodeVisionary achieves the best performance among three baselines for evaluating complex code generation, outperforming the best baseline with average improvements of 0.217, 0.163, and 0.141 in Pearson, Spearman, and Kendall-Tau coefficients, respectively. The resources of CodeVisionary are available at https://github.com/Eshe0922/CodeVisionary.