Antidistillation Sampling
作者: Yash Savani, Asher Trockman, Zhili Feng, Yixuan Even Xu, Avi Schwarzschild, Alexander Robey, Marc Finzi, J. Zico Kolter
分类: cs.AI, cs.CL
发布日期: 2025-04-17 (更新: 2025-10-26)
💡 一句话要点
提出Antidistillation Sampling,通过毒化推理轨迹提升模型蒸馏防御能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模型蒸馏 对抗性采样 知识产权保护 推理轨迹 模型安全
📋 核心要点
- 大型语言模型易受蒸馏攻击,攻击者可利用模型生成的推理轨迹进行知识窃取。
- Antidistillation Sampling通过修改模型token概率分布,生成对蒸馏无效的“毒化”推理轨迹。
- 该方法在保证模型原有性能的同时,显著降低了蒸馏攻击的有效性,提升了模型安全性。
📝 摘要(中文)
前沿模型在生成扩展推理轨迹时,会无意中产生丰富的token序列,这有利于模型蒸馏。意识到这种脆弱性,模型所有者可能会寻求既能限制蒸馏效果又不影响模型性能的采样策略。Antidistillation Sampling 正是提供了这种能力。通过策略性地修改模型的下一个token概率分布,Antidistillation Sampling 可以毒化推理轨迹,使其在蒸馏中的效果显著降低,同时保持模型的实际效用。更多详情请访问 https://antidistillation.com。
🔬 方法详解
问题定义:论文旨在解决大型语言模型易受蒸馏攻击的问题。现有方法难以在不影响模型自身性能的前提下,有效防御基于推理轨迹的蒸馏攻击。攻击者可以利用模型生成的token序列进行知识窃取,威胁模型所有者的知识产权。
核心思路:论文的核心思路是通过策略性地修改模型的下一个token概率分布,生成对蒸馏无效的“毒化”推理轨迹。这些轨迹在保持模型原有性能的同时,能够显著降低蒸馏攻击的有效性。这样设计的目的是使蒸馏模型无法从这些轨迹中学习到有用的知识,从而达到防御蒸馏攻击的目的。
技术框架:Antidistillation Sampling 的整体框架涉及修改模型在推理过程中的token采样策略。具体来说,它不是直接从原始的概率分布中采样,而是首先对概率分布进行修改,然后再进行采样。这个修改过程旨在生成“毒化”的推理轨迹。框架主要包含两个阶段:1) 确定需要修改的token概率分布;2) 使用修改后的概率分布进行采样。
关键创新:最重要的技术创新点在于提出了一种新的采样策略,该策略能够在不影响模型自身性能的前提下,生成对蒸馏无效的推理轨迹。与现有方法不同,Antidistillation Sampling 不是试图隐藏或混淆推理轨迹,而是直接“毒化”它们,使其对蒸馏模型无用。
关键设计:关键设计在于如何修改token的概率分布。具体的技术细节(如修改概率分布的具体算法、损失函数等)在摘要中没有明确说明,需要参考论文全文或相关网站才能了解。但可以推测,关键在于找到一种既能保证模型生成合理输出,又能使蒸馏模型难以学习的修改策略。这可能涉及到对某些特定token的概率进行放大或缩小,或者引入一些噪声。
🖼️ 关键图片
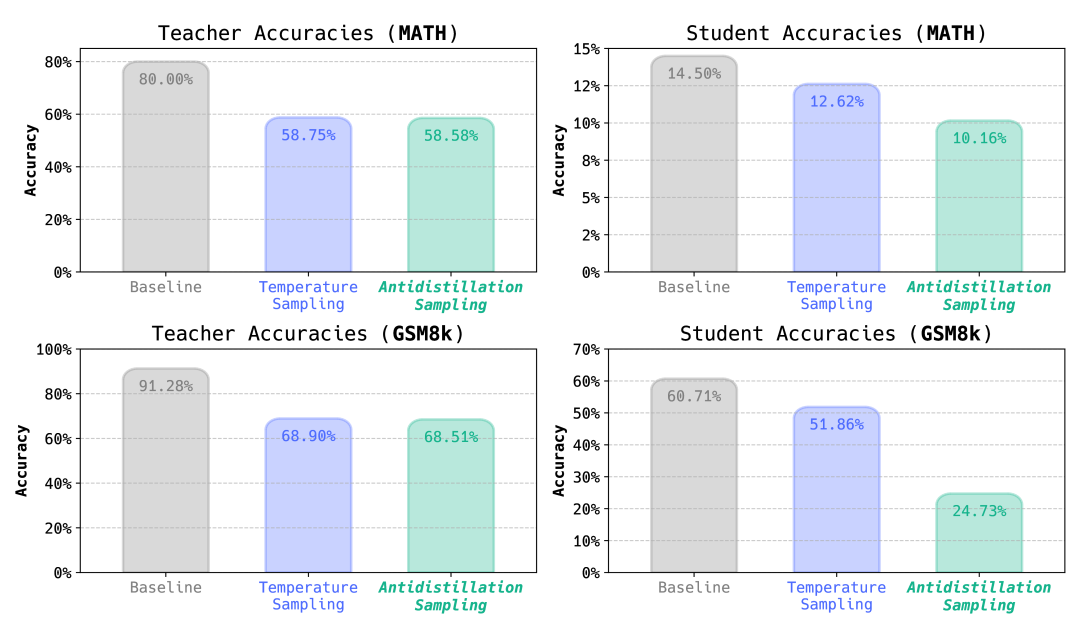
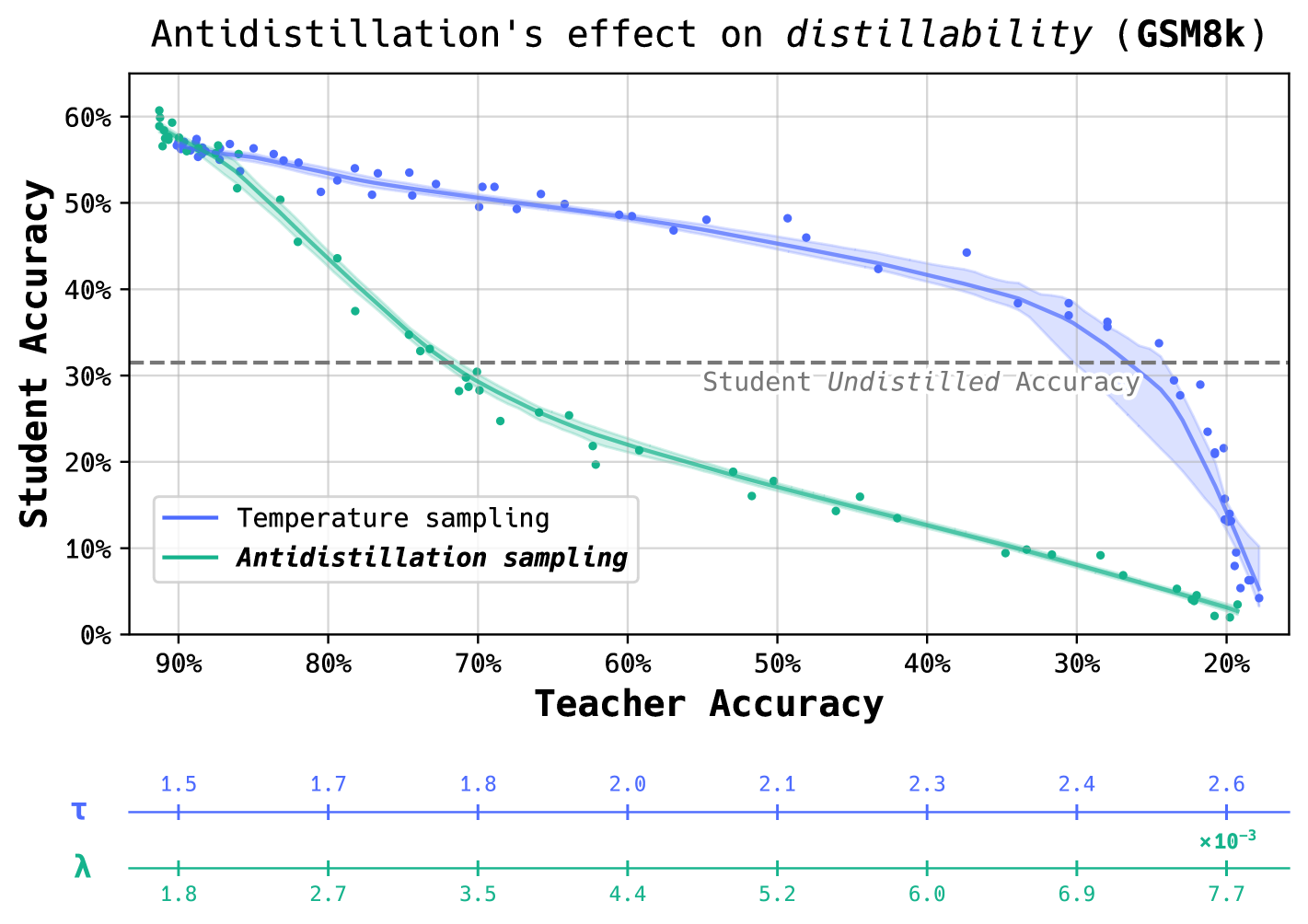
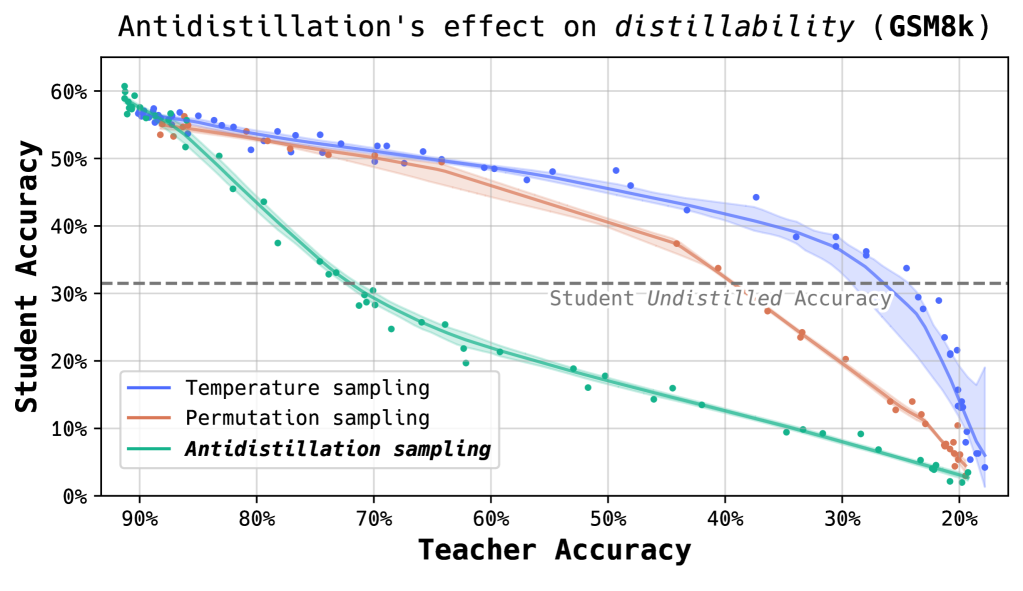
📊 实验亮点
由于摘要信息有限,具体的实验数据和性能提升未知。但根据摘要描述,Antidistillation Sampling 能够在保持模型原有性能的同时,显著降低蒸馏攻击的有效性。具体的性能数据和对比基线需要在论文全文中查找。
🎯 应用场景
Antidistillation Sampling 可应用于保护大型语言模型的知识产权,防止未经授权的模型复制和窃取。该技术能够有效防御基于推理轨迹的蒸馏攻击,提高模型的安全性。此外,该方法还可用于评估不同蒸馏算法的鲁棒性,促进更安全的模型蒸馏技术的发展。
📄 摘要(原文)
Frontier models that generate extended reasoning traces inadvertently produce rich token sequences that can facilitate model distillation. Recognizing this vulnerability, model owners may seek sampling strategies that limit the effectiveness of distillation without compromising model performance. Antidistillation sampling provides exactly this capability. By strategically modifying a model's next-token probability distribution, antidistillation sampling poisons reasoning traces, rendering them significantly less effective for distillation while preserving the model's practical utility. For further details, see https://antidistillation.com.