QLLM: Do We Really Need a Mixing Network for Credit Assignment in Multi-Agent Reinforcement Learning?
作者: Zhouyang Jiang, Bin Zhang, Yuanjun Li, Zhiwei Xu
分类: cs.MA, cs.AI
发布日期: 2025-04-17 (更新: 2025-12-27)
备注: Following the correction of experimental and data preprocessing errors, all experiments have been rerun and the results have been validated. The code is now publicly available for reproducibility
🔗 代码/项目: GITHUB
💡 一句话要点
QLLM:利用大语言模型自动构建信用分配函数,提升多智能体强化学习性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体强化学习 信用分配 大语言模型 代码生成 函数式表示
📋 核心要点
- 现有MARL方法在信用分配方面存在不足,例如贡献归因不精确、可解释性有限以及高维状态空间中的可扩展性差。
- QLLM利用大语言模型自动构建信用分配函数,通过TFCAF将信用分配表示为非线性函数,并使用编码器-评估器框架指导LLM生成代码。
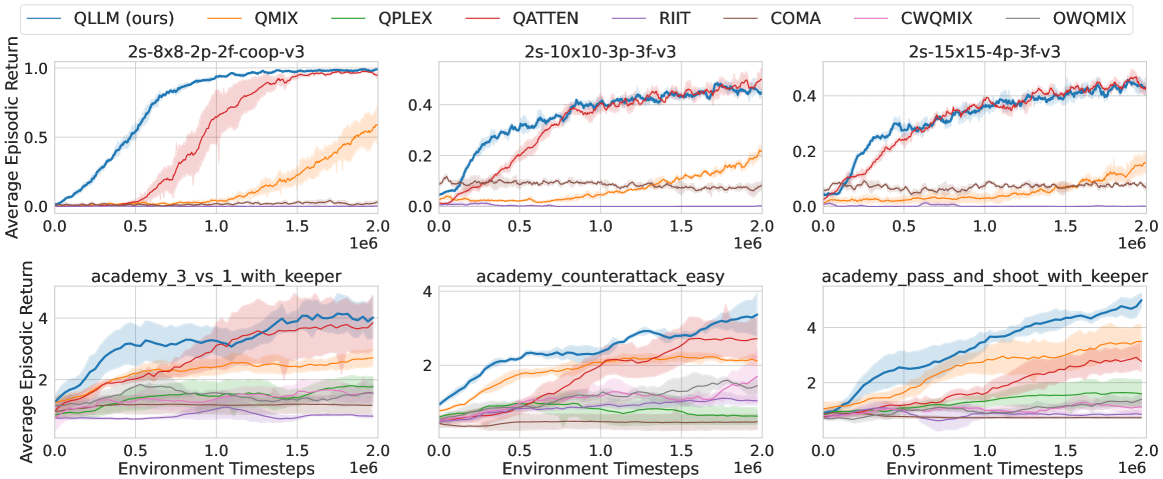
- 实验结果表明,QLLM在多个MARL基准测试中优于现有方法,并具有良好的泛化能力和兼容性。
📝 摘要(中文)
信用分配一直是多智能体强化学习(MARL)中的一个根本挑战。以往的研究主要通过集中式训练和分散式执行范式下的值分解方法来解决这个问题,其中神经网络被用于近似个体Q值和全局Q值之间的非线性关系。尽管这些方法在各种基准任务中取得了显著成功,但它们仍然存在一些局限性,包括贡献的不精确归因、有限的可解释性以及在高维状态空间中的较差可扩展性。为了应对这些挑战,我们提出了一种新颖的算法QLLM,该算法利用大型语言模型(LLM)来促进信用分配函数的自动构建。具体来说,引入了TFCAF的概念,其中信用分配过程被表示为直接且富有表现力的非线性函数公式。进一步采用定制设计的编码器-评估器框架来指导LLM生成和验证可执行代码,从而显著减轻了推理过程中的幻觉和浅层推理等问题。此外,IGM门控机制使QLLM能够根据任务需求灵活地强制或放宽单调性约束,涵盖了符合IGM和非单调性场景。在几个标准MARL基准上进行的大量实验表明,所提出的方法始终优于现有的最先进基线。此外,QLLM表现出强大的泛化能力,并与各种使用混合网络(mixing networks)的MARL算法保持兼容性,使其成为复杂多智能体场景中一种有前景且通用的解决方案。
🔬 方法详解
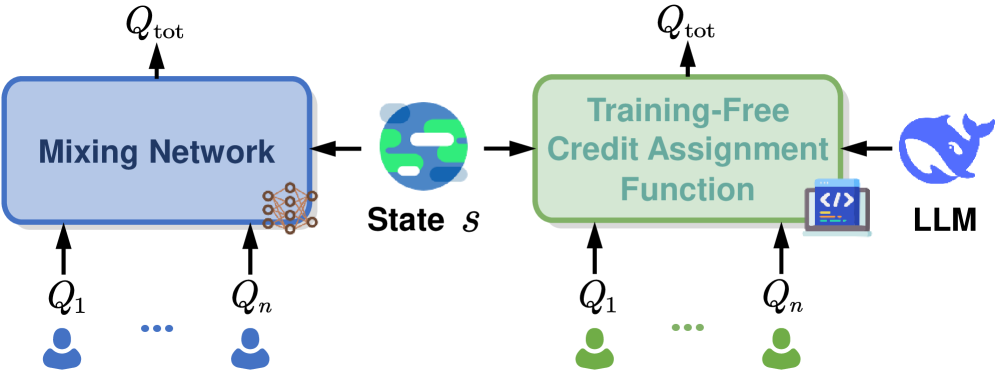
问题定义:多智能体强化学习中的信用分配问题,即如何将团队的整体奖励有效地分配给各个智能体的行为,以便每个智能体能够学习到最优策略。现有方法,如基于混合网络的方法,依赖于神经网络来近似个体Q值和全局Q值之间的关系,但这些方法存在贡献归因不精确、可解释性差以及在高维状态空间中可扩展性差等问题。
核心思路:利用大型语言模型(LLM)的强大代码生成和推理能力,自动构建信用分配函数。将信用分配过程表示为直接且富有表现力的非线性函数公式(TFCAF),并设计一个编码器-评估器框架来指导LLM生成和验证可执行代码,从而减轻LLM推理过程中的幻觉和浅层推理等问题。
技术框架:QLLM包含以下主要模块:1) TFCAF(Task-Free Credit Assignment Function):将信用分配表示为非线性函数。2) 编码器-评估器框架:指导LLM生成和验证可执行代码,包括编码器将环境信息编码为LLM可理解的提示,LLM生成代码,评估器验证代码的正确性。3) IGM-Gating Mechanism:根据任务需求灵活地强制或放宽单调性约束。
关键创新:1) 利用LLM自动构建信用分配函数,无需手动设计复杂的网络结构。2) 提出TFCAF,将信用分配表示为直接且富有表现力的非线性函数公式。3) 设计编码器-评估器框架,有效缓解LLM的幻觉问题,保证代码的正确性。4) IGM-Gating Mechanism,可以灵活地处理单调和非单调的信用分配场景。
关键设计:1) 编码器将环境信息编码为LLM可理解的提示,提示的设计至关重要,需要包含足够的信息,以便LLM能够生成正确的代码。2) 评估器验证代码的正确性,可以使用多种方法,例如执行生成的代码并检查其输出是否符合预期。3) IGM-Gating Mechanism通过一个门控网络来控制是否强制执行单调性约束,门控网络的输入是环境状态和个体Q值,输出是一个介于0和1之间的值,表示强制执行单调性约束的程度。
🖼️ 关键图片

📊 实验亮点
QLLM在多个标准MARL基准测试中取得了显著的性能提升,例如在StarCraft II中,QLLM优于现有的最先进基线。实验结果表明,QLLM具有强大的泛化能力,可以应用于不同的MARL算法和任务。此外,QLLM的可解释性更强,可以帮助研究人员更好地理解信用分配的过程。
🎯 应用场景
QLLM具有广泛的应用前景,可以应用于各种需要多智能体协作的场景,例如机器人协同、自动驾驶、资源分配、博弈游戏等。该方法能够提升多智能体系统的性能和可解释性,并降低人工设计的复杂性,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Credit assignment has remained a fundamental challenge in multi-agent reinforcement learning (MARL). Previous studies have primarily addressed this issue through value decomposition methods under the centralized training with decentralized execution paradigm, where neural networks are utilized to approximate the nonlinear relationship between individual Q-values and the global Q-value. Although these approaches have achieved considerable success in various benchmark tasks, they still suffer from several limitations, including imprecise attribution of contributions, limited interpretability, and poor scalability in high-dimensional state spaces. To address these challenges, we propose a novel algorithm, QLLM, which facilitates the automatic construction of credit assignment functions using large language models (LLMs). Specifically, the concept of TFCAF is introduced, wherein the credit allocation process is represented as a direct and expressive nonlinear functional formulation. A custom-designed coder-evaluator framework is further employed to guide the generation and verification of executable code by LLMs, significantly mitigating issues such as hallucination and shallow reasoning during inference. Furthermore, an IGM-Gating Mechanism enables QLLM to flexibly enforce or relax the monotonicity constraint depending on task demands, covering both IGM-compliant and non-monotonic scenarios. Extensive experiments conducted on several standard MARL benchmarks demonstrate that the proposed method consistently outperforms existing state-of-the-art baselines. Moreover, QLLM exhibits strong generalization capability and maintains compatibility with a wide range of MARL algorithms that utilize mixing networks, positioning it as a promising and versatile solution for complex multi-agent scenarios. The code is available at https://github.com/zhouyangjiang71-sys/QLLM.