EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
作者: Guanrou Yang, Chen Yang, Qian Chen, Ziyang Ma, Wenxi Chen, Wen Wang, Tianrui Wang, Yifan Yang, Zhikang Niu, Wenrui Liu, Fan Yu, Zhihao Du, Zhifu Gao, ShiLiang Zhang, Xie Chen
分类: eess.AS, cs.AI, cs.CL
发布日期: 2025-04-17 (更新: 2025-08-13)
备注: Accepted at ACMMM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
EmoVoice:基于LLM和自由文本提示的情感可控语音合成模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感语音合成 文本到语音 大型语言模型 自由文本提示 音素增强 情感控制 多模态评估
📋 核心要点
- 现有TTS模型在控制生成语音中的情感表达方面仍面临挑战,难以实现细粒度的情感控制。
- EmoVoice利用LLM进行自由文本情感控制,并采用音素增强设计,并行生成音素和音频token,提升内容一致性。
- EmoVoice在EmoVoice-DB和Secap数据集上取得了SOTA性能,并探索了使用多模态LLM评估情感语音的方法。
📝 摘要(中文)
本文提出了一种名为EmoVoice的新型情感可控语音合成(TTS)模型,该模型利用大型语言模型(LLM)实现细粒度的自由文本自然语言情感控制。受到思维链(CoT)和模态链(CoM)技术的启发,设计了一种音素增强变体,使模型能够并行输出音素token和音频token,从而增强内容一致性。此外,本文还引入了EmoVoice-DB,一个高质量的40小时英语情感数据集,其特点是富有表现力的语音和带有自然语言描述的细粒度情感标签。EmoVoice仅使用合成训练数据,就在英语EmoVoice-DB测试集上取得了最先进的性能,并且在使用内部数据在中文Secap测试集上取得了领先。本文进一步研究了现有情感评估指标的可靠性及其与人类感知偏好的对齐情况,并探索使用SOTA多模态LLM GPT-4o-audio和Gemini来评估情感语音。
🔬 方法详解
问题定义:现有的文本到语音(TTS)模型在情感表达的控制上存在不足,难以实现自然、细粒度的情感控制。用户希望能够通过自由文本描述来精确控制合成语音的情感,而现有方法通常依赖于预定义的情感标签或强度等级,缺乏灵活性和表达能力。
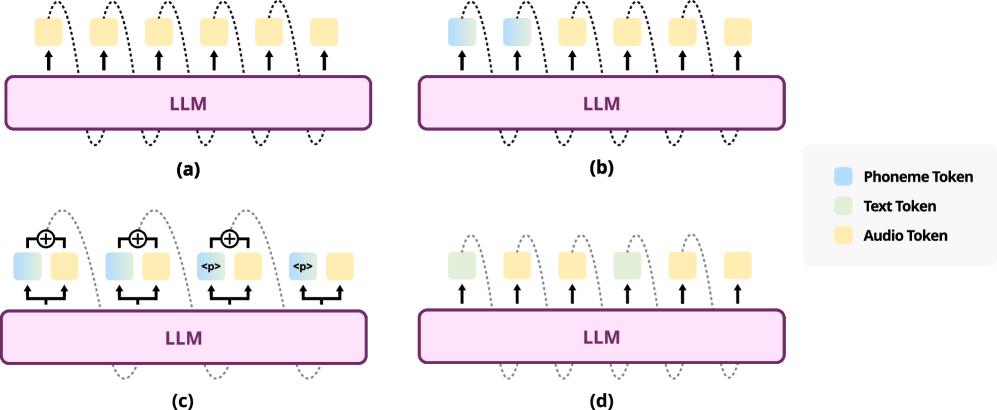
核心思路:EmoVoice的核心思路是利用大型语言模型(LLM)的强大文本理解和生成能力,将情感描述转化为模型可以理解和利用的内部表示。通过自由文本提示,用户可以更自然地表达所需的情感,而LLM则负责将这些情感信息融入到语音合成过程中。此外,借鉴思维链(CoT)和模态链(CoM)的思想,引入音素增强变体,并行生成音素和音频,以提高内容一致性。
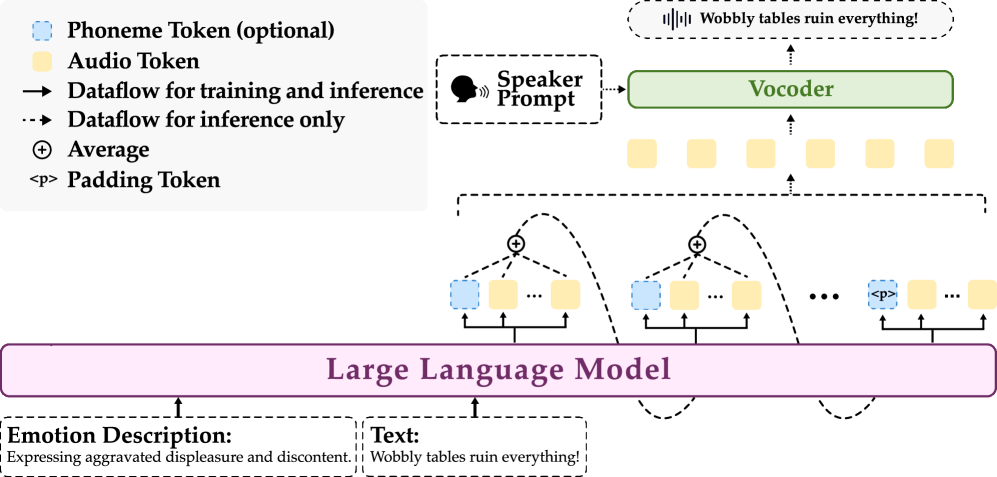
技术框架:EmoVoice的整体框架包含以下几个主要模块:1) 文本编码器:将输入的文本转换为向量表示。2) 情感编码器:利用LLM将自由文本情感描述转换为情感向量。3) 音素预测器:预测与文本内容对应的音素序列。4) 音频合成器:根据文本表示、情感向量和音素序列生成最终的语音。音素预测器和音频合成器并行工作,相互促进,提高内容一致性。
关键创新:EmoVoice的关键创新在于:1) 基于LLM的自由文本情感控制:允许用户使用自然语言描述来控制语音的情感,提高了情感控制的灵活性和表达能力。2) 音素增强变体:通过并行生成音素和音频,增强了内容一致性,避免了传统TTS模型中容易出现的发音错误。3) EmoVoice-DB数据集:构建了一个高质量的、包含丰富情感表达和自然语言描述的英语情感数据集,为情感TTS的研究提供了新的资源。
关键设计:在情感编码器中,使用了预训练的LLM,并对其进行了微调,以更好地理解和生成情感向量。音素预测器和音频合成器采用了Transformer架构,并针对语音合成任务进行了优化。损失函数包括内容损失、情感损失和对抗损失,以保证合成语音的质量、情感表达的准确性和自然度。在训练过程中,使用了对抗训练的方法,以提高模型的鲁棒性和泛化能力。
🖼️ 关键图片
📊 实验亮点
EmoVoice在英语EmoVoice-DB测试集上,仅使用合成训练数据就取得了SOTA性能,证明了其在情感语音合成方面的优越性。同时,在中文Secap测试集上,使用内部数据也取得了领先结果。此外,论文还探索了使用GPT-4o-audio和Gemini等SOTA多模态LLM来评估情感语音,为情感语音评估提供了新的思路。
🎯 应用场景
EmoVoice具有广泛的应用前景,包括:1) 个性化语音助手:根据用户的情绪状态提供定制化的语音服务。2) 情感化游戏角色:为游戏角色赋予更丰富的情感表达,增强游戏体验。3) 辅助沟通工具:帮助有沟通障碍的人群更有效地表达情感。4) 语音内容创作:为播客、有声书等内容创作提供更具表现力的语音合成技术。
📄 摘要(原文)
Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Dataset, code, checkpoints, and demo samples are available at https://github.com/yanghaha0908/EmoVoice.