HypoBench: Towards Systematic and Principled Benchmarking for Hypothesis Generation
作者: Haokun Liu, Sicong Huang, Jingyu Hu, Yangqiaoyu Zhou, Chenhao Tan
分类: cs.AI, cs.CL, cs.CY, cs.LG
发布日期: 2025-04-15
备注: 29 pages, 6 figures, website link: https://chicagohai.github.io/HypoBench/
💡 一句话要点
提出HypoBench:一个系统且规范的假设生成基准评测框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 假设生成 大型语言模型 基准评测 科学发现 人工智能
📋 核心要点
- 现有假设生成方法在发现数据中所有相关和有意义的模式方面存在不足,尤其是在任务难度增加时性能显著下降。
- HypoBench通过构建包含真实世界和合成任务的综合基准,系统地评估LLMs和假设生成方法在实用性、泛化性和发现率等方面的性能。
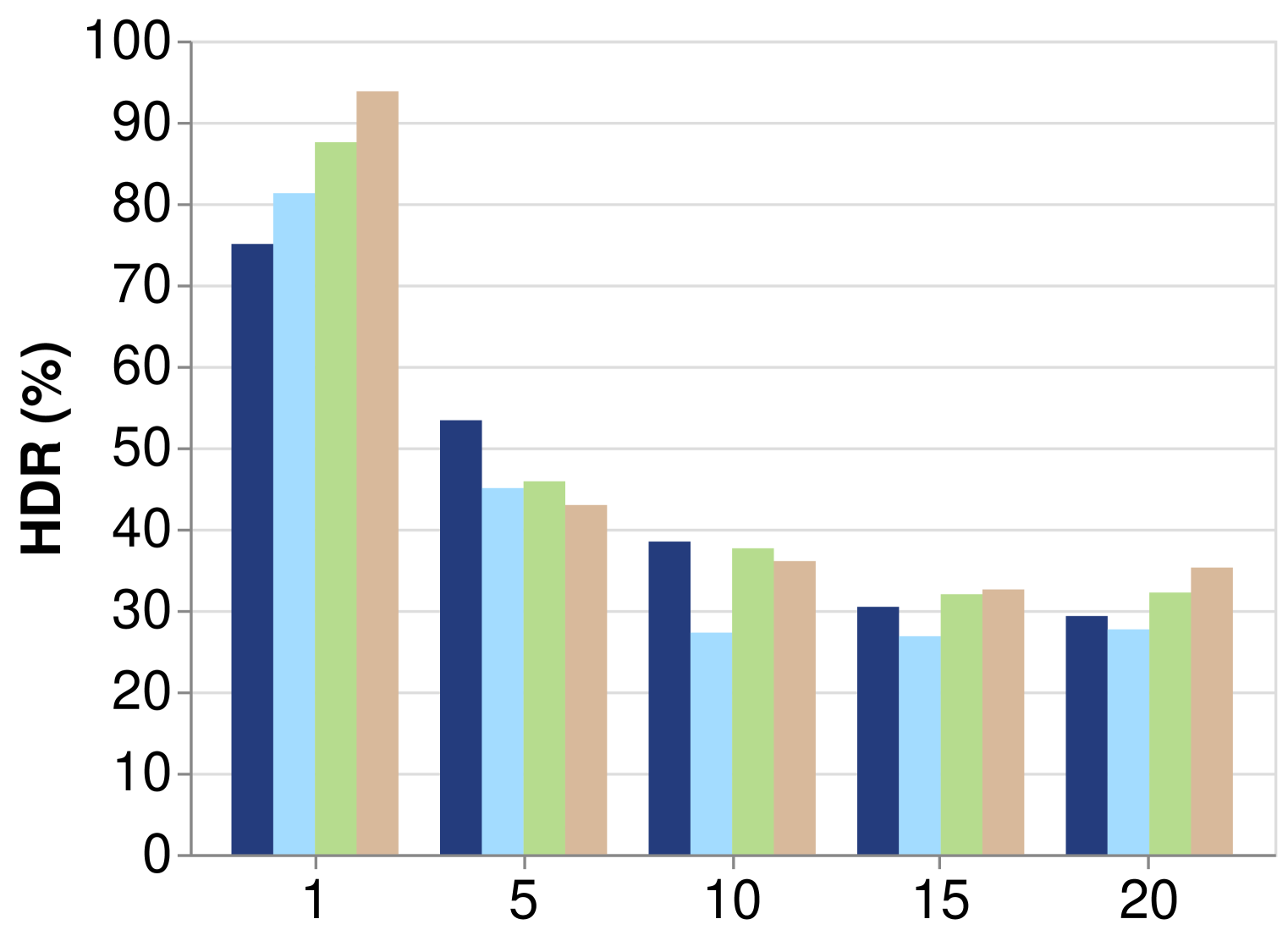
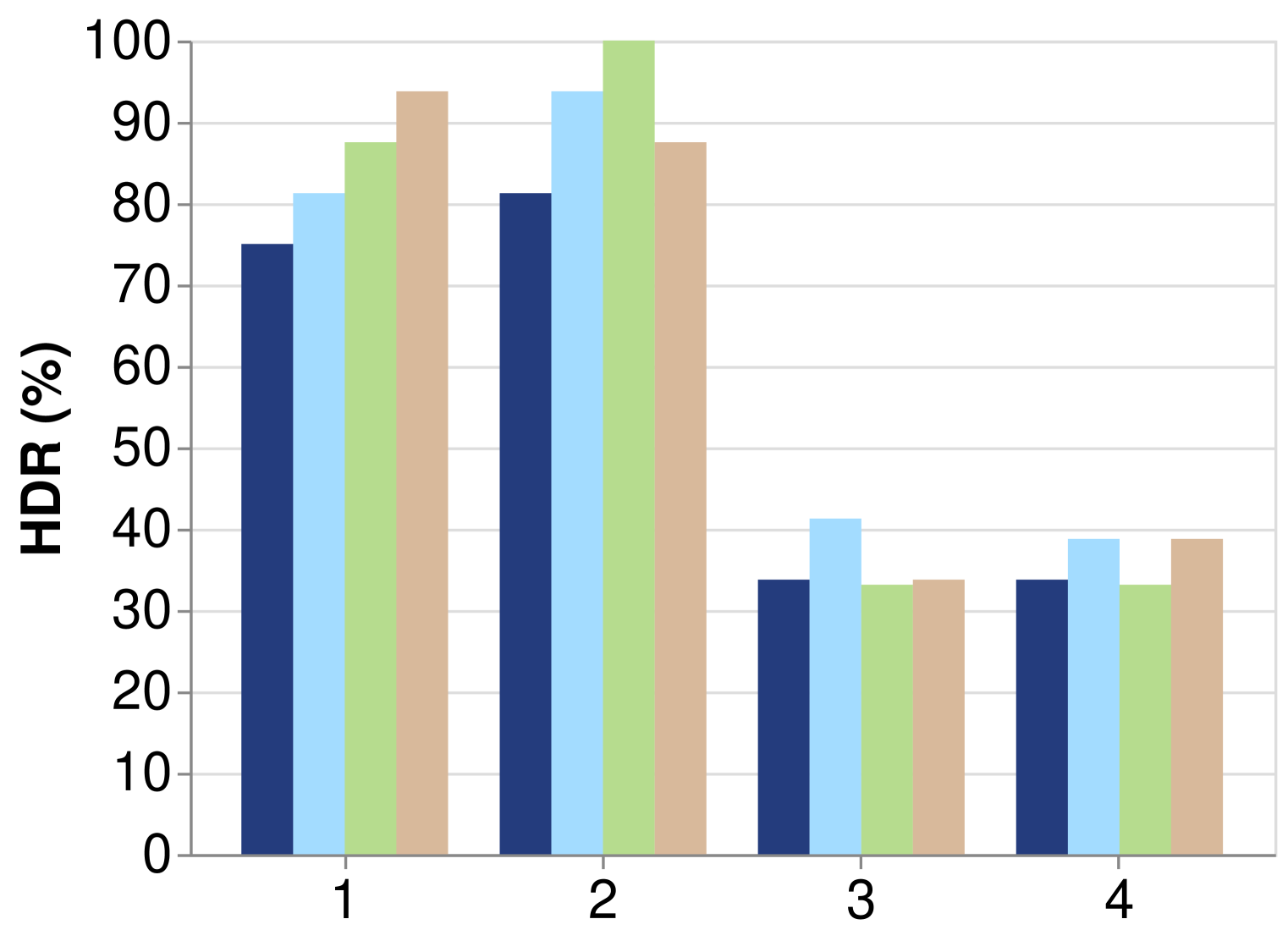
- 实验结果表明,现有方法能够发现有效和新颖的模式,但仍有改进空间,尤其是在高难度合成任务中,最佳模型仅能恢复38.8%的真实假设。
📝 摘要(中文)
本文介绍了一个名为HypoBench的新基准,旨在评估大型语言模型(LLMs)和假设生成方法在多个方面的性能,包括实用性、泛化性和假设发现率。HypoBench包含7个真实世界任务和5个合成任务,共计194个不同的数据集。研究人员评估了四种最先进的LLMs与六种现有的假设生成方法。结果表明,现有方法能够发现数据中有效且新颖的模式。然而,合成数据集的结果表明,仍有很大的改进空间,因为当前的假设生成方法并未完全揭示所有相关或有意义的模式。具体而言,在合成环境中,随着任务难度的增加,性能显著下降,最佳模型和方法仅能恢复38.8%的真实假设。这些发现突出了假设生成方面的挑战,并证明HypoBench可以作为改进旨在辅助科学发现的AI系统的宝贵资源。
🔬 方法详解
问题定义:现有的大型语言模型在假设生成方面展现出潜力,但缺乏系统性的评估方法来衡量其性能。如何定义一个“好的”假设,以及如何全面评估假设生成方法,是当前面临的挑战。现有方法缺乏统一的评估标准,难以比较不同方法的优劣,也难以发现方法的局限性。
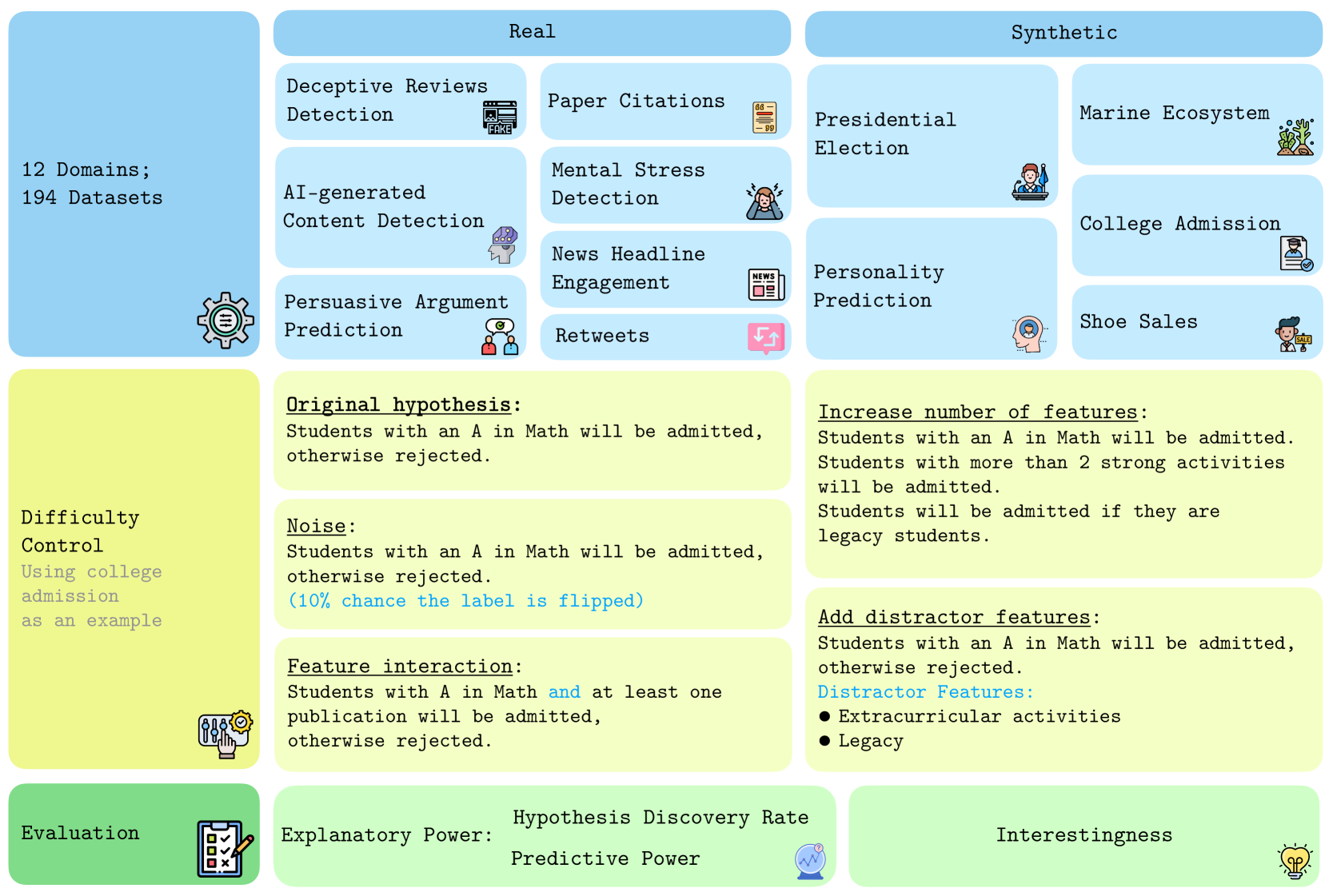
核心思路:HypoBench的核心思路是构建一个包含多种任务和数据集的综合性基准,从多个维度评估假设生成方法的性能。通过真实世界任务评估方法的实用性和泛化性,通过合成任务评估方法发现潜在模式的能力。这种多维度的评估方式能够更全面地了解方法的优缺点。
技术框架:HypoBench包含两个主要部分:真实世界任务和合成任务。真实世界任务包括7个不同的领域,例如医疗、金融等,每个领域包含多个数据集。合成任务则通过预定义的规则生成数据,并控制任务的难度。评估指标包括假设的有效性、新颖性和发现率。研究人员使用四种最先进的LLMs和六种现有的假设生成方法在HypoBench上进行评估。
关键创新:HypoBench的关键创新在于其系统性和规范性。它不仅提供了丰富的数据集和任务,还定义了一套清晰的评估指标,使得不同假设生成方法之间的比较更加公平和客观。此外,HypoBench还引入了合成任务,可以更精确地评估方法发现潜在模式的能力。
关键设计:在合成任务的设计中,研究人员精心设计了数据生成规则,以控制任务的难度和复杂性。评估指标的选择也经过仔细考虑,既要能够反映假设的质量,又要能够衡量方法发现新知识的能力。具体参数设置和网络结构取决于所使用的LLM和假设生成方法,论文中没有详细说明。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有方法在HypoBench上能够发现有效且新颖的模式,但在合成数据集上的表现仍有提升空间。在难度较高的合成任务中,最佳模型和方法仅能恢复38.8%的真实假设,这表明现有方法在处理复杂数据和发现潜在模式方面仍存在局限性。HypoBench为未来研究提供了明确的方向。
🎯 应用场景
HypoBench可应用于科学发现、商业智能、医疗诊断等领域。通过辅助研究人员或决策者自动生成假设,加速知识发现过程,提高决策效率。未来可用于开发更智能的AI系统,以支持更复杂的科学研究和问题解决。
📄 摘要(原文)
There is growing interest in hypothesis generation with large language models (LLMs). However, fundamental questions remain: what makes a good hypothesis, and how can we systematically evaluate methods for hypothesis generation? To address this, we introduce HypoBench, a novel benchmark designed to evaluate LLMs and hypothesis generation methods across multiple aspects, including practical utility, generalizability, and hypothesis discovery rate. HypoBench includes 7 real-world tasks and 5 synthetic tasks with 194 distinct datasets. We evaluate four state-of-the-art LLMs combined with six existing hypothesis-generation methods. Overall, our results suggest that existing methods are capable of discovering valid and novel patterns in the data. However, the results from synthetic datasets indicate that there is still significant room for improvement, as current hypothesis generation methods do not fully uncover all relevant or meaningful patterns. Specifically, in synthetic settings, as task difficulty increases, performance significantly drops, with best models and methods only recovering 38.8% of the ground-truth hypotheses. These findings highlight challenges in hypothesis generation and demonstrate that HypoBench serves as a valuable resource for improving AI systems designed to assist scientific discovery.