ARise: Towards Knowledge-Augmented Reasoning via Risk-Adaptive Search
作者: Yize Zhang, Tianshu Wang, Sirui Chen, Kun Wang, Xingyu Zeng, Hongyu Lin, Xianpei Han, Le Sun, Chaochao Lu
分类: cs.AI, cs.CL
发布日期: 2025-04-15 (更新: 2025-05-26)
备注: Accepted to ACL 2025 Main. Project homepage: https://opencausalab.github.io/ARise
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ARise:通过风险自适应搜索增强知识推理,解决开放域复杂推理难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识增强推理 风险自适应搜索 蒙特卡洛树搜索 检索增强生成 开放域推理
📋 核心要点
- 现有推理方法在开放域知识密集型场景中泛化能力不足,知识增强推理方法存在错误传播和验证瓶颈问题。
- ARise框架通过风险评估中间推理状态,结合动态检索增强生成和蒙特卡洛树搜索,优化推理计划。
- 实验表明,ARise在知识增强推理任务上显著优于现有方法,性能提升高达25.37%。
📝 摘要(中文)
大型语言模型(LLMs)展现了强大的能力,通过扩展测试时计算来增强推理能力受到了越来越多的关注。然而,它们在开放式、知识密集型、复杂推理场景中的应用仍然有限。面向推理的方法由于隐含了完整世界知识的假设,难以推广到开放式场景。同时,知识增强推理(KAR)方法未能解决两个核心挑战:1)错误传播,即早期步骤中的错误会贯穿整个链条;2)验证瓶颈,即在多分支决策过程中出现的探索-利用权衡。为了克服这些限制,我们引入了ARise,这是一个新颖的框架,它将中间推理状态的风险评估与蒙特卡洛树搜索范式中的动态检索增强生成(RAG)相结合。这种方法能够有效地构建和优化跨多个维护的假设分支的推理计划。实验结果表明,ARise显著优于最先进的KAR方法,高达23.10%,并且优于最新的配备RAG的大型推理模型,高达25.37%。
🔬 方法详解
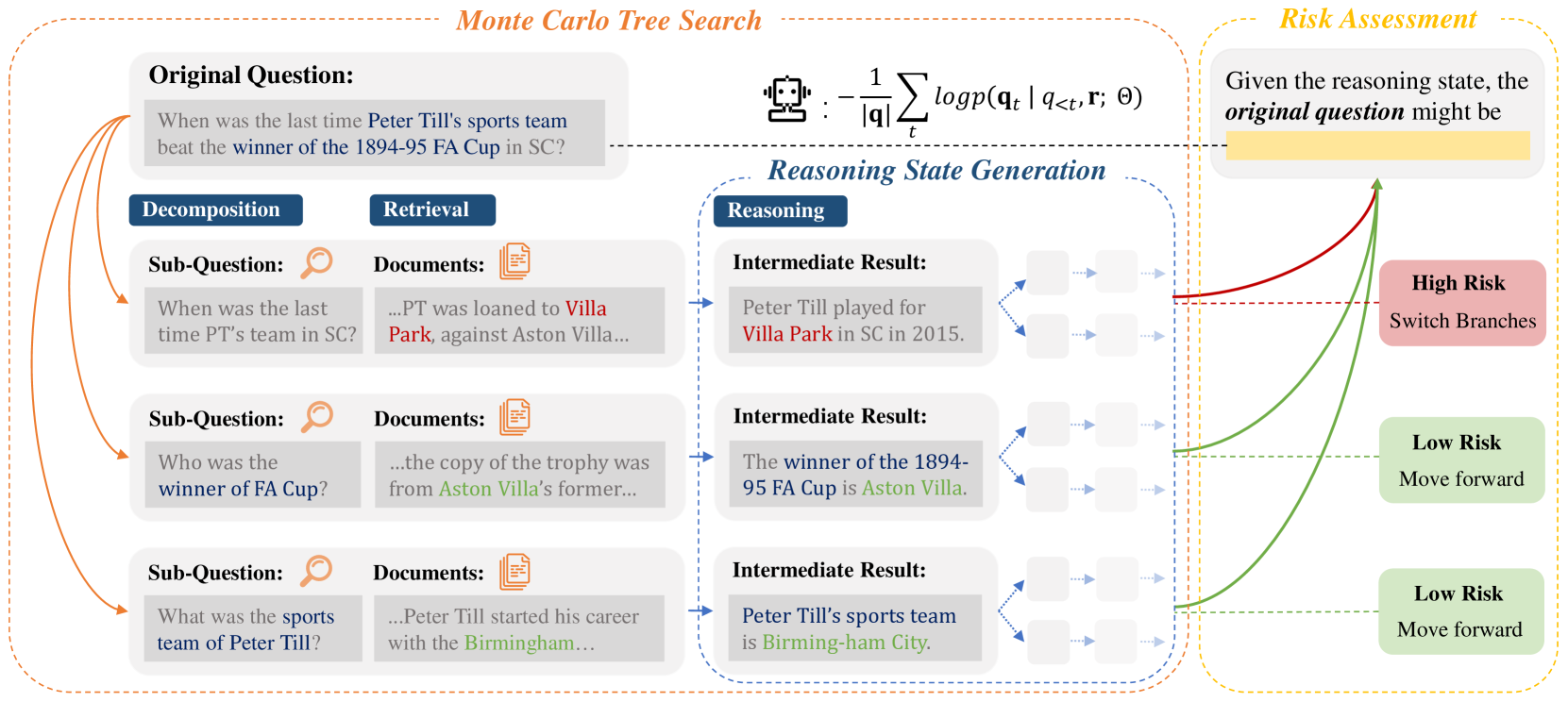
问题定义:论文旨在解决开放域、知识密集型、复杂推理场景下,现有大型语言模型推理能力不足的问题。现有方法,特别是知识增强推理(KAR)方法,存在两个主要痛点:一是错误传播,即早期推理步骤的错误会累积并影响后续步骤;二是验证瓶颈,即在多分支推理过程中,难以有效地进行探索和利用的权衡,导致推理效率低下。
核心思路:ARise的核心思路是将风险评估融入到推理过程中,通过评估中间推理状态的风险来指导检索增强生成(RAG)和推理路径的探索。具体来说,ARise使用蒙特卡洛树搜索(MCTS)来维护多个假设分支,并使用风险评估来指导MCTS的搜索过程,从而更有效地构建和优化推理计划。
技术框架:ARise的整体框架包含以下几个主要模块:1) 状态表示:将推理过程中的状态表示为包含当前推理步骤、检索到的知识和风险评估结果的向量。2) 风险评估模块:评估当前推理状态的风险,例如,通过预测当前推理步骤的正确性概率。3) 检索增强生成模块:根据当前状态和风险评估结果,从外部知识库中检索相关知识,并使用大型语言模型生成下一步的推理步骤。4) 蒙特卡洛树搜索模块:使用MCTS来探索不同的推理路径,并根据风险评估结果来选择最优的路径。
关键创新:ARise的关键创新在于将风险评估融入到知识增强推理过程中。与现有方法相比,ARise能够更有效地识别和避免错误的推理路径,从而提高推理的准确性和效率。此外,ARise还通过动态检索增强生成来利用外部知识,从而增强了模型在开放域场景下的推理能力。
关键设计:ARise的关键设计包括:1) 风险评估函数:可以使用各种方法来评估推理状态的风险,例如,可以使用一个分类器来预测当前推理步骤的正确性概率。2) 检索策略:可以使用不同的检索策略来从外部知识库中检索相关知识,例如,可以使用基于关键词的检索或基于语义相似度的检索。3) MCTS的奖励函数:可以使用风险评估结果来设计MCTS的奖励函数,从而引导MCTS搜索更可靠的推理路径。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ARise在知识增强推理任务上显著优于现有方法。具体来说,ARise在多个基准数据集上取得了最先进的性能,相比最先进的KAR方法,性能提升高达23.10%,相比最新的配备RAG的大型推理模型,性能提升高达25.37%。这些结果表明,ARise能够有效地解决错误传播和验证瓶颈问题,从而提高推理的准确性和效率。
🎯 应用场景
ARise框架可应用于各种需要知识密集型推理的场景,例如问答系统、对话系统、智能客服、科学研究等。通过提升模型在开放域复杂推理任务上的性能,ARise能够帮助人们更有效地获取和利用知识,从而解决实际问题,并有望推动人工智能在更广泛领域的应用。
📄 摘要(原文)
Large language models (LLMs) have demonstrated impressive capabilities and are receiving increasing attention to enhance their reasoning through scaling test--time compute. However, their application in open--ended, knowledge--intensive, complex reasoning scenarios is still limited. Reasoning--oriented methods struggle to generalize to open--ended scenarios due to implicit assumptions of complete world knowledge. Meanwhile, knowledge--augmented reasoning (KAR) methods fail to address two core challenges: 1) error propagation, where errors in early steps cascade through the chain, and 2) verification bottleneck, where the explore--exploit tradeoff arises in multi--branch decision processes. To overcome these limitations, we introduce ARise, a novel framework that integrates risk assessment of intermediate reasoning states with dynamic retrieval--augmented generation (RAG) within a Monte Carlo tree search paradigm. This approach enables effective construction and optimization of reasoning plans across multiple maintained hypothesis branches. Experimental results show that ARise significantly outperforms the state--of--the--art KAR methods by up to 23.10%, and the latest RAG-equipped large reasoning models by up to 25.37%. Our project page is at https://opencausalab.github.io/ARise.