Controllable Expressive 3D Facial Animation via Diffusion in a Unified Multimodal Space
作者: Kangwei Liu, Junwu Liu, Xiaowei Yi, Jinlin Guo, Yun Cao
分类: cs.MM, cs.AI, cs.CV
发布日期: 2025-04-14
备注: Accepted by ICME2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于扩散模型的统一多模态空间,实现可控的富有表现力的3D面部动画
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D面部动画 扩散模型 多模态融合 情感控制 对比学习 注意力机制 FLAME模型
📋 核心要点
- 现有音频驱动面部动画方法依赖单一模态输入,忽略了多模态信息的互补性,限制了情感控制的灵活性。
- 论文提出基于扩散模型的框架,通过多模态情感绑定和内容感知注意力机制,实现可控且富有表现力的3D面部动画。
- 实验结果表明,该方法在情感相似性上显著优于现有方法,提升达21.6%,同时保证了面部动画的自然性和生理合理性。
📝 摘要(中文)
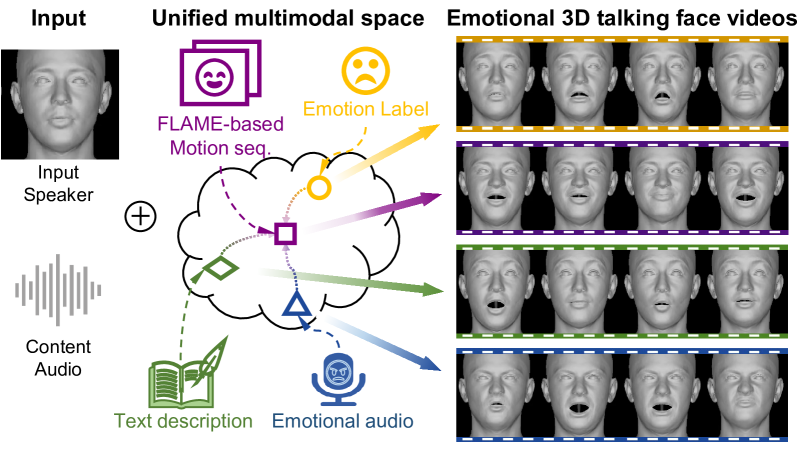
本文提出了一种基于扩散模型的可控的、富有表现力的3D面部动画框架,旨在解决音频驱动的情感3D面部动画中存在的两个主要挑战:一是依赖单一模态控制信号(视频、文本或情感标签),未能充分利用它们之间的互补优势进行全面的情感操控;二是确定性的基于回归的映射限制了情感表达和非语言行为的随机性,从而限制了合成动画的表现力。该方法引入了两项关键创新:一是基于FLAME的多模态情感绑定策略,通过对比学习对齐不同的模态(文本、音频和情感标签),从而实现从多个信号源进行灵活的情感控制;二是基于注意力机制的潜在扩散模型,该模型具有内容感知注意力和情感引导层,从而丰富了运动多样性,同时保持了时间连贯性和自然的脸部动态。大量实验表明,该方法在大多数指标上优于现有方法,在情感相似性方面提高了21.6%,同时保持了生理上合理的脸部动态。
🔬 方法详解
问题定义:现有音频驱动的3D面部动画方法主要存在两个痛点。首先,它们通常依赖于单一模态的控制信号,例如视频、文本或情感标签,而忽略了这些模态之间存在的互补信息,导致情感操控不够全面和灵活。其次,现有方法大多采用确定性的回归模型,这限制了情感表达的随机性和非语言行为的多样性,使得生成的动画缺乏表现力。
核心思路:本文的核心思路是利用扩散模型强大的生成能力,并结合多模态信息,从而生成更加自然、富有表现力且可控的3D面部动画。通过将不同模态的信息对齐到一个统一的特征空间,并利用注意力机制引导扩散过程,可以有效地融合不同模态的优势,并生成具有丰富细节和情感表达的动画。
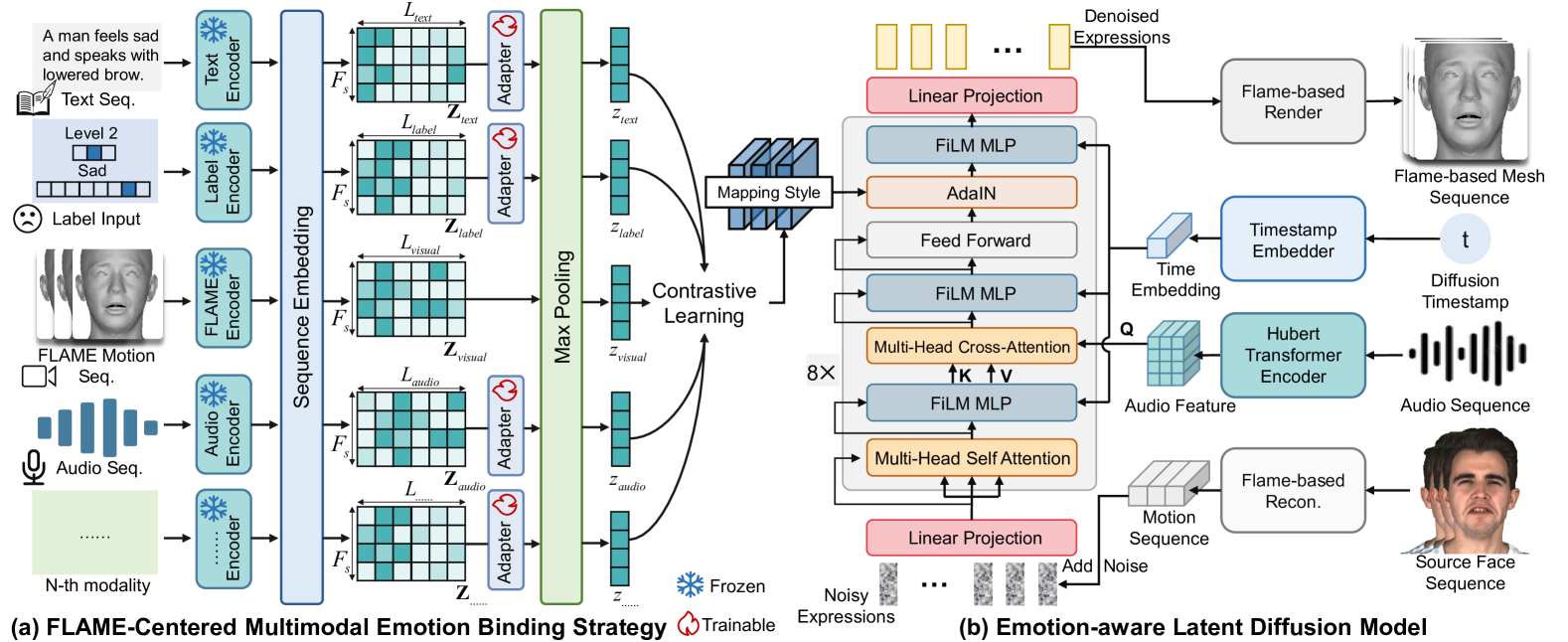
技术框架:该框架主要包含两个核心模块:多模态情感绑定模块和基于注意力机制的潜在扩散模型。多模态情感绑定模块负责将文本、音频和情感标签等不同模态的信息对齐到基于FLAME模型的统一特征空间中,从而实现多模态信息的融合。基于注意力机制的潜在扩散模型则负责根据融合后的多模态信息生成3D面部动画。该模型包含内容感知注意力和情感引导层,用于增强运动多样性,并保持时间连贯性和自然的脸部动态。
关键创新:该论文的关键创新在于以下两点:一是提出了基于FLAME的多模态情感绑定策略,该策略通过对比学习对齐不同模态的信息,从而实现从多个信号源进行灵活的情感控制。二是提出了基于注意力机制的潜在扩散模型,该模型具有内容感知注意力和情感引导层,从而丰富了运动多样性,同时保持了时间连贯性和自然的脸部动态。与现有方法相比,该方法能够更好地融合多模态信息,并生成更加自然、富有表现力且可控的3D面部动画。
关键设计:在多模态情感绑定模块中,使用了对比学习损失来对齐不同模态的特征表示。在基于注意力机制的潜在扩散模型中,使用了内容感知注意力机制来关注与当前内容相关的特征,并使用情感引导层来控制生成动画的情感表达。此外,还使用了时间卷积网络来保证生成动画的时间连贯性。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在情感相似性方面显著优于现有方法,提升达21.6%,同时保持了生理上合理的脸部动态。通过消融实验验证了多模态情感绑定策略和注意力机制的有效性。与多个state-of-the-art方法进行了对比,证明了该方法在生成高质量、富有表现力的3D面部动画方面的优越性。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、游戏开发、电影制作、人机交互等领域。例如,可以用于创建更加逼真和富有表现力的虚拟角色,提升用户在虚拟环境中的沉浸感。此外,还可以用于开发更加智能和自然的语音助手,使其能够根据用户的语音情感生成相应的面部表情,从而提升人机交互的自然性和流畅性。未来,该技术有望应用于个性化教育、心理咨询等领域,提供更加人性化的服务。
📄 摘要(原文)
Audio-driven emotional 3D facial animation encounters two significant challenges: (1) reliance on single-modal control signals (videos, text, or emotion labels) without leveraging their complementary strengths for comprehensive emotion manipulation, and (2) deterministic regression-based mapping that constrains the stochastic nature of emotional expressions and non-verbal behaviors, limiting the expressiveness of synthesized animations. To address these challenges, we present a diffusion-based framework for controllable expressive 3D facial animation. Our approach introduces two key innovations: (1) a FLAME-centered multimodal emotion binding strategy that aligns diverse modalities (text, audio, and emotion labels) through contrastive learning, enabling flexible emotion control from multiple signal sources, and (2) an attention-based latent diffusion model with content-aware attention and emotion-guided layers, which enriches motion diversity while maintaining temporal coherence and natural facial dynamics. Extensive experiments demonstrate that our method outperforms existing approaches across most metrics, achieving a 21.6\% improvement in emotion similarity while preserving physiologically plausible facial dynamics. Project Page: https://kangweiiliu.github.io/Control_3D_Animation.