Towards Accurate Forecasting of Renewable Energy : Building Datasets and Benchmarking Machine Learning Models for Solar and Wind Power in France
作者: Eloi Lindas, Yannig Goude, Philippe Ciais
分类: eess.SP, cs.AI, cs.LG, stat.ML
发布日期: 2025-04-14
备注: 24 pages, 4 tables, 18 figures
💡 一句话要点
构建法国太阳能和风能预测数据集,并基准测试机器学习模型
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 可再生能源预测 太阳能 风能 机器学习 空间数据 时间序列 交叉验证 神经网络
📋 核心要点
- 现有区域电力预测方法依赖电厂级预测,忽略空间数据潜力,导致预测精度受限。
- 利用空间天气数据和生产信息,训练机器学习模型,实现国家尺度可再生能源预测。
- 实验表明,针对时间序列的交叉验证和神经网络模型能有效降低预测误差。
📝 摘要(中文)
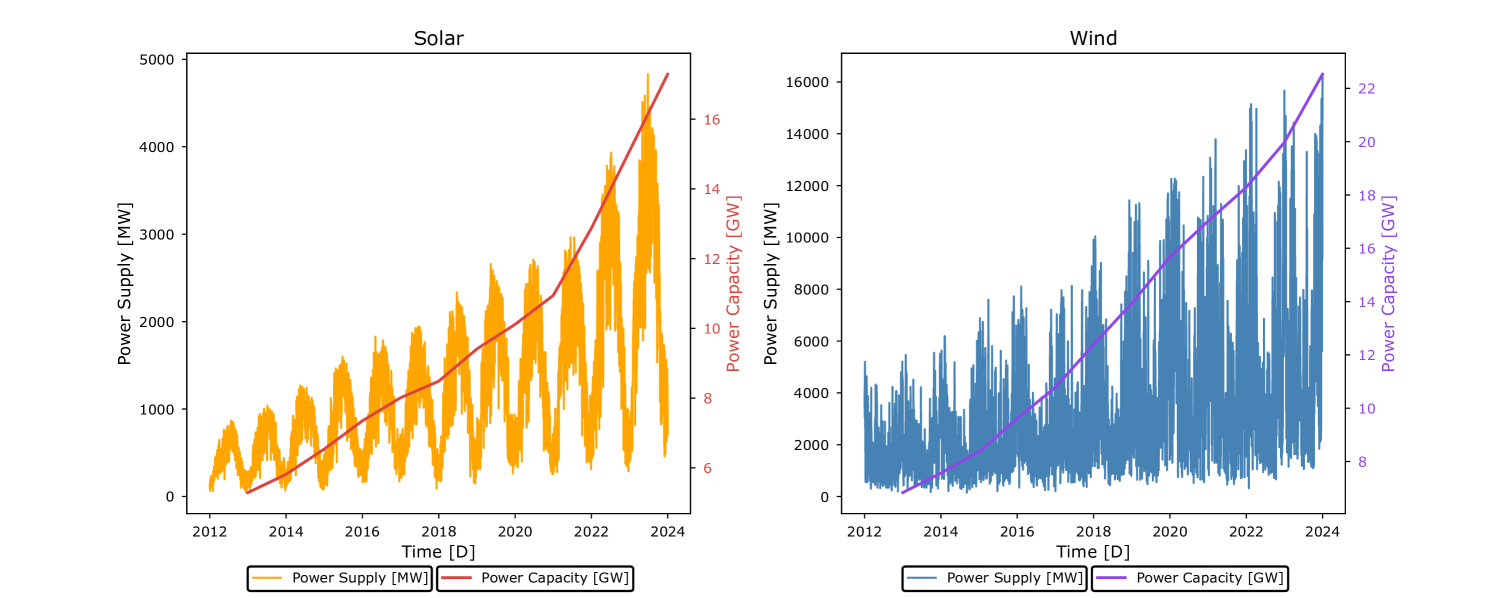
准确预测非调度性可再生能源对于电网稳定和价格预测至关重要。区域电力供应预测通常通过自下而上的电厂级预测间接进行,包含滞后的电力值,并且没有利用空间分辨率数据的潜力。本研究提出了一种综合方法,用于预测法国国家尺度的太阳能和风能发电量,使用机器学习模型,该模型使用空间显式天气数据以及生产地点容量的空间信息进行训练。构建了一个从2012年到2023年的数据集,使用来自RTE(国家电网运营商)的每日发电量数据作为目标变量,以及来自ERA5的每日天气数据、生产地点容量和位置以及电价作为输入特征。探索了三种建模方法来处理空间分辨率天气数据:全国空间平均、通过主成分分析进行降维以及利用复杂空间关系的计算机视觉架构。该研究对基于交叉验证方法的先进机器学习模型以及超参数调整方法进行了基准测试。结果表明,针对时间序列量身定制的交叉验证最适合达到低误差。我们发现,神经网络往往优于传统的基于树的模型,后者由于可再生能源容量随时间增加而面临外推挑战。模型性能在中期范围内nRMSE为4%到10%,实现了与在单个工厂级别建立的本地模型相似的误差指标,突出了这些方法在区域电力供应预测中的潜力。
🔬 方法详解
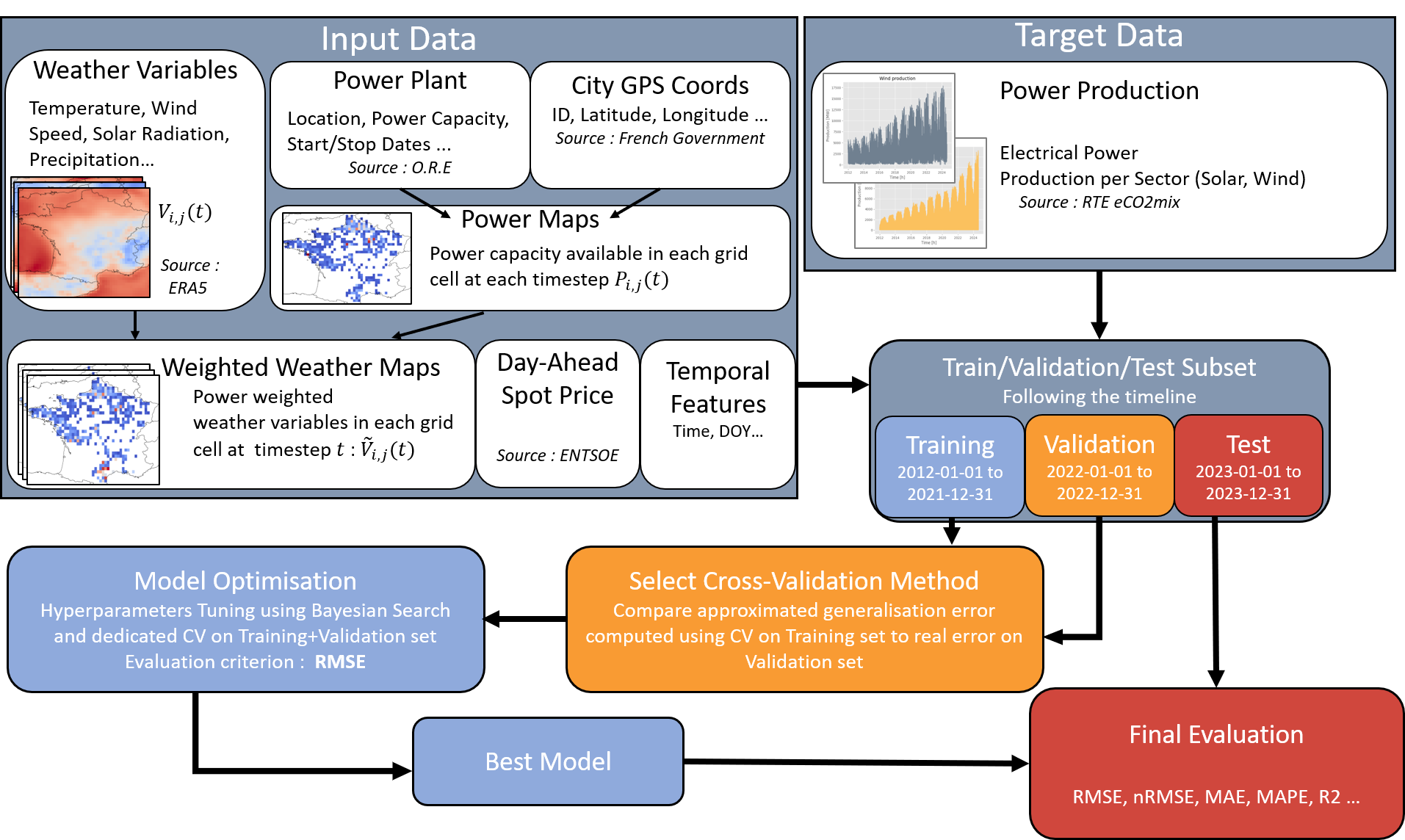
问题定义:论文旨在解决法国国家层面太阳能和风能发电量的精确预测问题。现有方法的痛点在于依赖于电厂级别的自下而上预测,未能充分利用空间分辨率的天气数据和生产地点信息,并且难以处理可再生能源容量随时间增长带来的外推挑战。
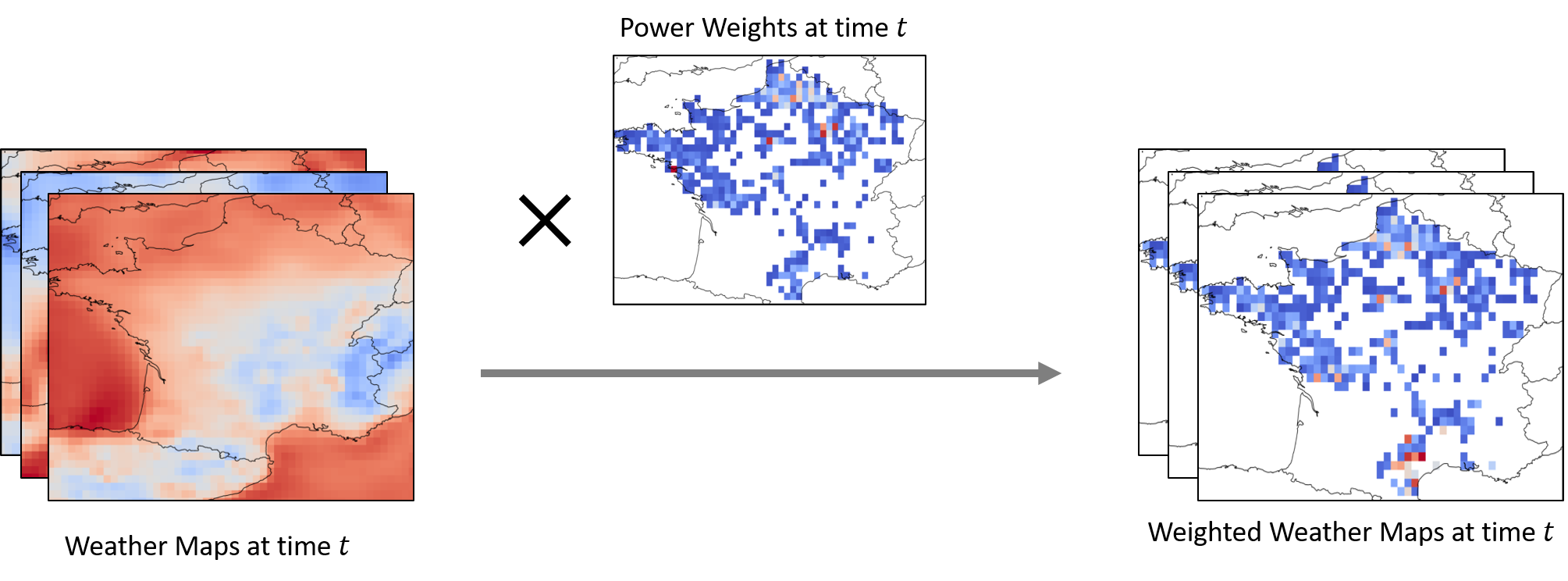
核心思路:论文的核心思路是利用机器学习模型,结合空间显式的天气数据(ERA5)、生产地点容量和位置信息,以及历史电力生产数据,直接预测国家层面的总发电量。通过整合空间信息,模型能够捕捉到不同区域天气状况对发电量的影响,从而提高预测精度。
技术框架:整体框架包括数据收集与预处理、特征工程、模型训练与验证三个主要阶段。首先,收集2012年至2023年的电力生产数据、天气数据、生产地点信息和电价数据。然后,进行特征工程,包括空间天气数据的处理(空间平均、PCA降维、计算机视觉方法)。接着,选择合适的机器学习模型(包括神经网络和树模型),并使用交叉验证方法进行训练和超参数调优。最后,评估模型在不同预测范围内的性能。
关键创新:论文的关键创新在于将空间显式的天气数据融入到国家层面的可再生能源预测中,并探索了不同的空间数据处理方法,包括空间平均、PCA降维和计算机视觉方法。此外,论文还针对时间序列数据特点,采用了定制化的交叉验证方法,提高了模型泛化能力。
关键设计:在空间数据处理方面,论文比较了三种方法:简单的空间平均、利用PCA进行降维以减少计算量,以及使用计算机视觉架构来捕捉复杂的空间关系。在模型选择方面,论文比较了神经网络和树模型,并发现神经网络在处理外推问题上更具优势。在交叉验证方面,论文采用了针对时间序列数据的交叉验证方法,例如滚动窗口交叉验证,以避免数据泄露。
🖼️ 关键图片
📊 实验亮点
研究结果表明,基于空间天气数据的机器学习模型能够实现4%到10%的nRMSE(中期预测),与单电厂级别的本地模型性能相当。神经网络模型在处理可再生能源容量增长带来的外推问题上表现优于传统树模型。针对时间序列的交叉验证方法显著提高了模型的泛化能力。
🎯 应用场景
该研究成果可应用于电网调度优化、电力市场价格预测、可再生能源投资决策等领域。通过提高可再生能源发电量的预测精度,有助于电网运营商更好地平衡供需,降低电网运行成本,促进可再生能源的更大规模应用,并为能源政策制定提供数据支持。
📄 摘要(原文)
Accurate prediction of non-dispatchable renewable energy sources is essential for grid stability and price prediction. Regional power supply forecasts are usually indirect through a bottom-up approach of plant-level forecasts, incorporate lagged power values, and do not use the potential of spatially resolved data. This study presents a comprehensive methodology for predicting solar and wind power production at country scale in France using machine learning models trained with spatially explicit weather data combined with spatial information about production sites capacity. A dataset is built spanning from 2012 to 2023, using daily power production data from RTE (the national grid operator) as the target variable, with daily weather data from ERA5, production sites capacity and location, and electricity prices as input features. Three modeling approaches are explored to handle spatially resolved weather data: spatial averaging over the country, dimension reduction through principal component analysis, and a computer vision architecture to exploit complex spatial relationships. The study benchmarks state-of-the-art machine learning models as well as hyperparameter tuning approaches based on cross-validation methods on daily power production data. Results indicate that cross-validation tailored to time series is best suited to reach low error. We found that neural networks tend to outperform traditional tree-based models, which face challenges in extrapolation due to the increasing renewable capacity over time. Model performance ranges from 4% to 10% in nRMSE for midterm horizon, achieving similar error metrics to local models established at a single-plant level, highlighting the potential of these methods for regional power supply forecasting.