RealWebAssist: A Benchmark for Long-Horizon Web Assistance with Real-World Users
作者: Suyu Ye, Haojun Shi, Darren Shih, Hyokun Yun, Tanya Roosta, Tianmin Shu
分类: cs.AI, cs.CL, cs.CV, cs.LG
发布日期: 2025-04-14 (更新: 2025-12-01)
备注: Project Website: https://scai.cs.jhu.edu/projects/RealWebAssist/ Code: https://github.com/SCAI-JHU/RealWebAssist
💡 一句话要点
RealWebAssist:一个面向真实用户的长时程Web辅助基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Web辅助 长时程交互 用户意图理解 GUI定位 真实用户数据 基准测试 人机交互
📋 核心要点
- 现有Web智能体基准测试难以处理真实用户指令的模糊性、演变性和多层次辅助需求。
- RealWebAssist通过构建真实用户指令数据集,模拟长时程Web交互,评估智能体理解用户意图和GUI定位能力。
- 实验表明,现有模型在理解和定位用户指令方面表现不佳,凸显了长时程Web辅助的挑战性。
📝 摘要(中文)
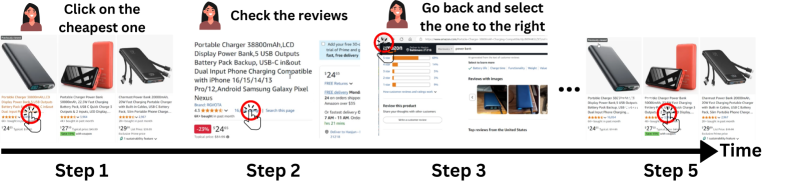
为了成功地辅助基于Web的长时程任务,AI智能体必须能够在较长时间内按顺序遵循真实用户的指令。与现有的基于Web的智能体基准测试不同,真实世界中的顺序指令遵循带来了重大挑战,而不仅仅是执行单个、明确定义的任务。例如,真实世界的人类指令可能是模糊的,需要不同级别的AI辅助,并且可能随着时间的推移而演变,反映用户心理状态的变化。为了解决这一差距,我们引入了RealWebAssist,这是一个新颖的基准测试,旨在评估在涉及与Web的长时程交互、可视化GUI定位以及理解模糊的真实世界用户指令的真实场景中的顺序指令遵循。RealWebAssist包括一个从真实世界人类用户收集的顺序指令数据集。每个用户指示一个基于Web的助手在一系列网站上执行一系列任务。一个成功的智能体必须推理每个指令背后的真实意图,跟踪用户的心理状态,理解用户特定的例程,并将预期的任务定位到正确的GUI元素上的动作。我们的实验结果表明,最先进的模型难以理解和定位用户指令,这给遵循真实世界用户指令进行长时程Web辅助带来了严峻的挑战。
🔬 方法详解
问题定义:现有基于Web的智能体基准测试无法很好地模拟真实世界用户指令的复杂性。真实用户指令通常是模糊的,需要不同程度的AI辅助,并且会随着用户心理状态的变化而演变。这使得智能体难以理解用户的真实意图,并将其转化为正确的GUI操作。
核心思路:RealWebAssist的核心思路是构建一个更贴近真实世界的Web辅助场景,通过收集真实用户的指令数据,来评估智能体在长时程交互中理解用户意图和执行任务的能力。这种方法强调了智能体对用户心理状态的建模和对用户特定习惯的理解。
技术框架:RealWebAssist包含一个数据集,其中每个样本都包含一个用户在多个网站上执行一系列任务的顺序指令。智能体需要根据这些指令,与Web环境进行交互,并完成相应的任务。整体流程包括:(1) 接收用户指令;(2) 理解指令意图;(3) 定位GUI元素;(4) 执行操作;(5) 更新用户状态;(6) 重复上述步骤,直到任务完成。
关键创新:RealWebAssist的关键创新在于其数据集的真实性。它不是通过人工合成或预定义规则生成指令,而是直接从真实用户收集。这使得数据集能够更好地反映真实世界用户指令的复杂性和多样性。此外,该基准测试还强调了长时程交互和用户状态建模的重要性,这在之前的Web智能体基准测试中往往被忽略。
关键设计:RealWebAssist数据集包含用户指令、Web页面状态、用户操作序列等信息。评估指标包括任务完成率、指令理解准确率、GUI定位准确率等。具体的模型训练和评估细节取决于所使用的智能体架构,但通常需要使用强化学习或模仿学习等方法来训练智能体。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有最先进的模型在RealWebAssist基准测试上表现不佳,难以准确理解和定位用户指令。这表明,在真实世界的Web辅助场景中,智能体仍然面临着巨大的挑战,需要进一步的研究和改进。
🎯 应用场景
RealWebAssist的研究成果可应用于开发更智能、更人性化的Web助手,例如智能客服、自动化测试工具、以及辅助残疾人使用Web的辅助技术。通过提高智能体理解用户意图和执行复杂Web任务的能力,可以显著提升用户体验和工作效率。
📄 摘要(原文)
To achieve successful assistance with long-horizon web-based tasks, AI agents must be able to sequentially follow real-world user instructions over a long period. Unlike existing web-based agent benchmarks, sequential instruction following in the real world poses significant challenges beyond performing a single, clearly defined task. For instance, real-world human instructions can be ambiguous, require different levels of AI assistance, and may evolve over time, reflecting changes in the user's mental state. To address this gap, we introduce RealWebAssist, a novel benchmark designed to evaluate sequential instruction-following in realistic scenarios involving long-horizon interactions with the web, visual GUI grounding, and understanding ambiguous real-world user instructions. RealWebAssist includes a dataset of sequential instructions collected from real-world human users. Each user instructs a web-based assistant to perform a series of tasks on multiple websites. A successful agent must reason about the true intent behind each instruction, keep track of the mental state of the user, understand user-specific routines, and ground the intended tasks to actions on the correct GUI elements. Our experimental results show that state-of-the-art models struggle to understand and ground user instructions, posing critical challenges in following real-world user instructions for long-horizon web assistance.