Offline Dynamic Inventory and Pricing Strategy: Addressing Censored and Dependent Demand
作者: Korel Gundem, Zhengling Qi
分类: stat.ML, cs.AI, cs.LG, math.ST, stat.AP
发布日期: 2025-04-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出离线动态库存和定价策略,解决审查和依赖需求下的优化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 动态定价 库存控制 马尔可夫决策过程 离线强化学习 生存分析
📋 核心要点
- 现有方法在处理具有审查和依赖需求的动态库存和定价问题时,面临利润信息缺失和马尔可夫性质失效的挑战。
- 论文提出通过求解高阶MDP来近似最优策略,并设计专门的Bellman方程,结合离线强化学习和生存分析方法。
- 数值实验验证了所提出算法在估计最优策略方面的有效性,并提供了有限样本遗憾界限的理论支持。
📝 摘要(中文)
本文研究了基于离线序列特征的定价和库存控制问题,其中当前需求依赖于过去的需求水平,并且任何超过可用库存的需求都会丢失。我们的目标是利用离线数据集(包含过去的价格、订购数量、库存水平、协变量和审查销售水平)来估计最优的定价和库存控制策略,以最大化长期利润。虽然没有审查的基础动态可以由马尔可夫决策过程(MDP)建模,但主要障碍来自观察到的存在需求审查的过程,导致利润信息缺失、马尔可夫性质失效以及非平稳最优策略。为了克服这些挑战,我们首先通过求解一个由连续审查实例数量表征的高阶MDP来近似最优策略,这最终归结为求解一个为此问题量身定制的专门Bellman方程。受到离线强化学习和生存分析的启发,我们提出了两种新的数据驱动算法来求解这些Bellman方程,从而估计最优策略。此外,我们建立了有限样本遗憾界限来验证这些算法的有效性。最后,我们进行了数值实验来证明我们的算法在估计最优策略方面的有效性。据我们所知,这是第一个在以审查和依赖需求为特征的序列决策环境中学习最优定价和库存控制策略的数据驱动方法。所提出算法的实现可在https://github.com/gundemkorel/Inventory_Pricing_Control获得。
🔬 方法详解
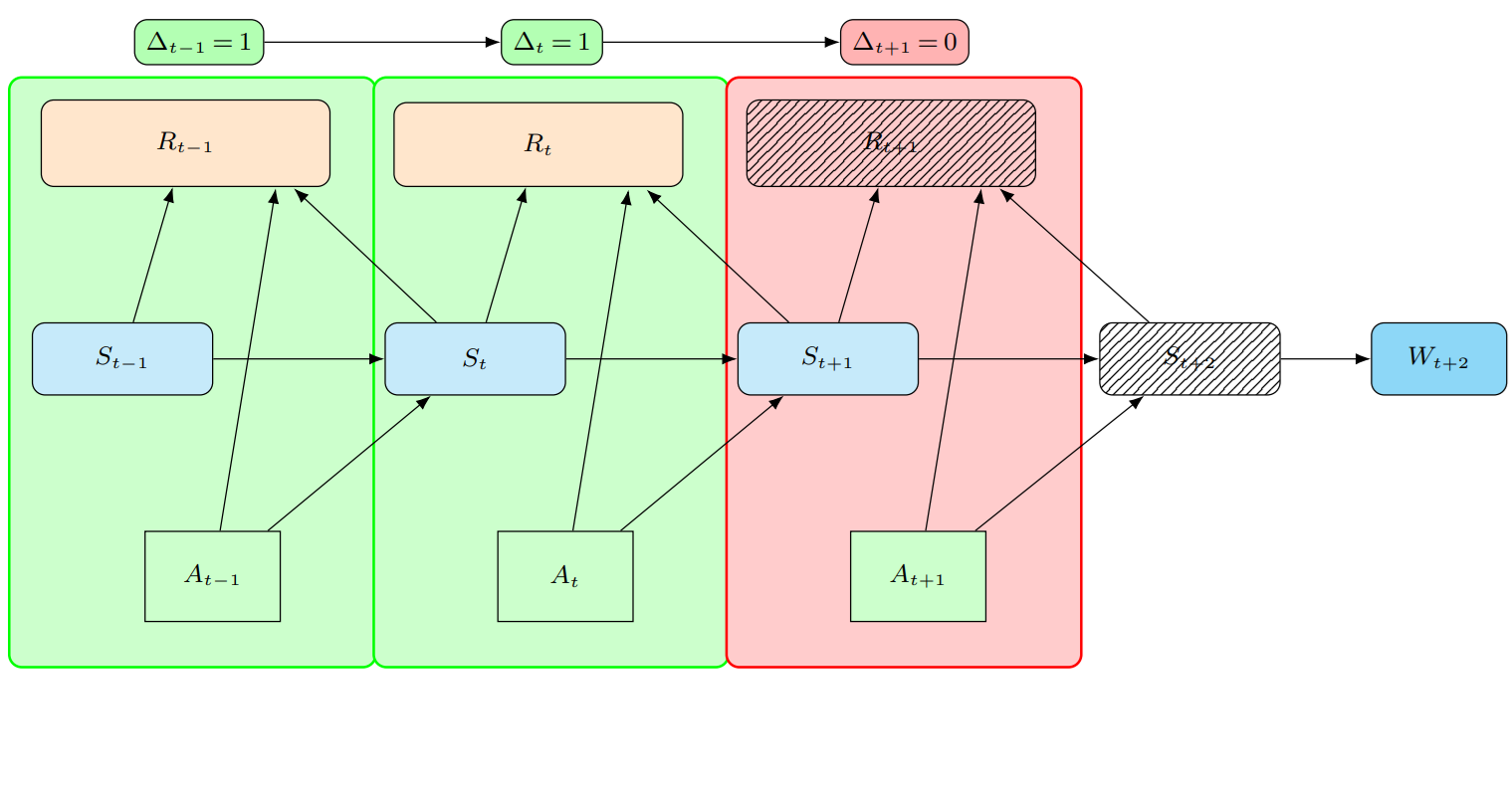
问题定义:论文旨在解决离线动态库存和定价策略问题,该问题涉及具有审查和依赖需求的情况。现有方法在处理此类问题时,由于需求审查导致利润信息缺失,使得传统的马尔可夫决策过程(MDP)不再适用,最优策略也变为非平稳的。这使得学习最优定价和库存控制策略变得困难。
核心思路:论文的核心思路是通过将问题建模为高阶MDP来解决需求审查带来的挑战。高阶MDP考虑了连续审查实例的数量,从而能够更好地捕捉需求之间的依赖关系。此外,论文还借鉴了离线强化学习和生存分析的思想,设计了数据驱动的算法来求解Bellman方程,从而估计最优策略。
技术框架:整体框架包括以下几个主要步骤:1) 将问题建模为高阶MDP;2) 推导出针对该问题的专门Bellman方程;3) 利用离线数据集,结合离线强化学习和生存分析方法,设计数据驱动的算法来求解Bellman方程;4) 估计最优定价和库存控制策略。
关键创新:论文的关键创新在于提出了一个数据驱动的框架,用于在具有审查和依赖需求的序列决策环境中学习最优定价和库存控制策略。该框架通过高阶MDP建模和专门的Bellman方程,有效地解决了需求审查带来的挑战。此外,结合离线强化学习和生存分析的方法,使得可以利用离线数据来学习最优策略。
关键设计:论文的关键设计包括:1) 高阶MDP的阶数选择,需要根据实际问题的需求依赖程度进行调整;2) Bellman方程的求解算法,论文提出了两种数据驱动的算法,具体实现细节需要在代码中查看;3) 损失函数的设计,需要考虑利润最大化和库存成本最小化等因素。
🖼️ 关键图片
📊 实验亮点
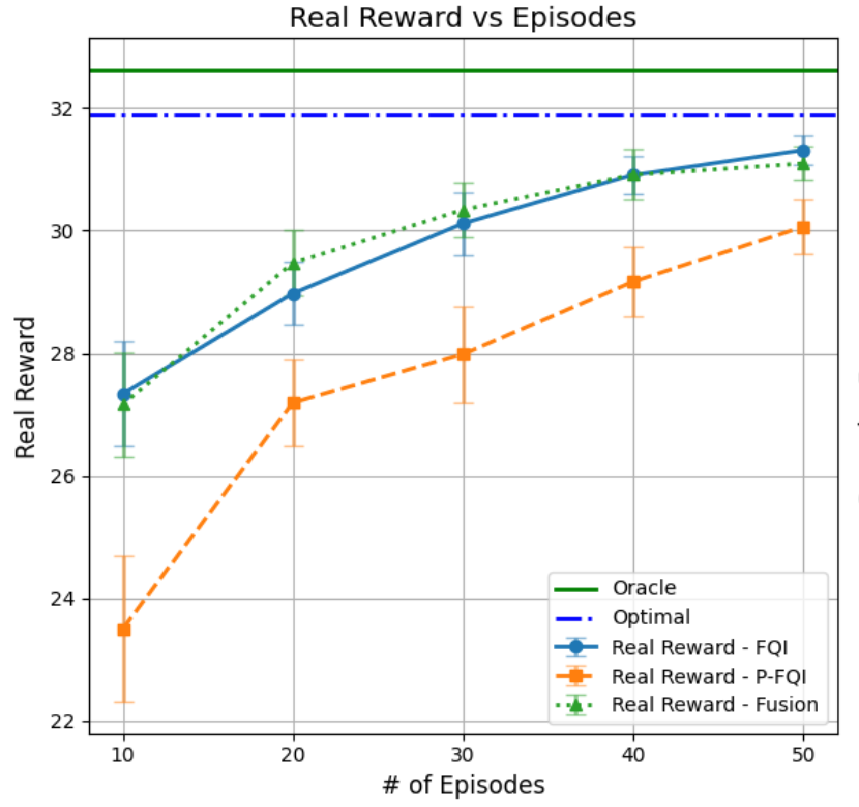
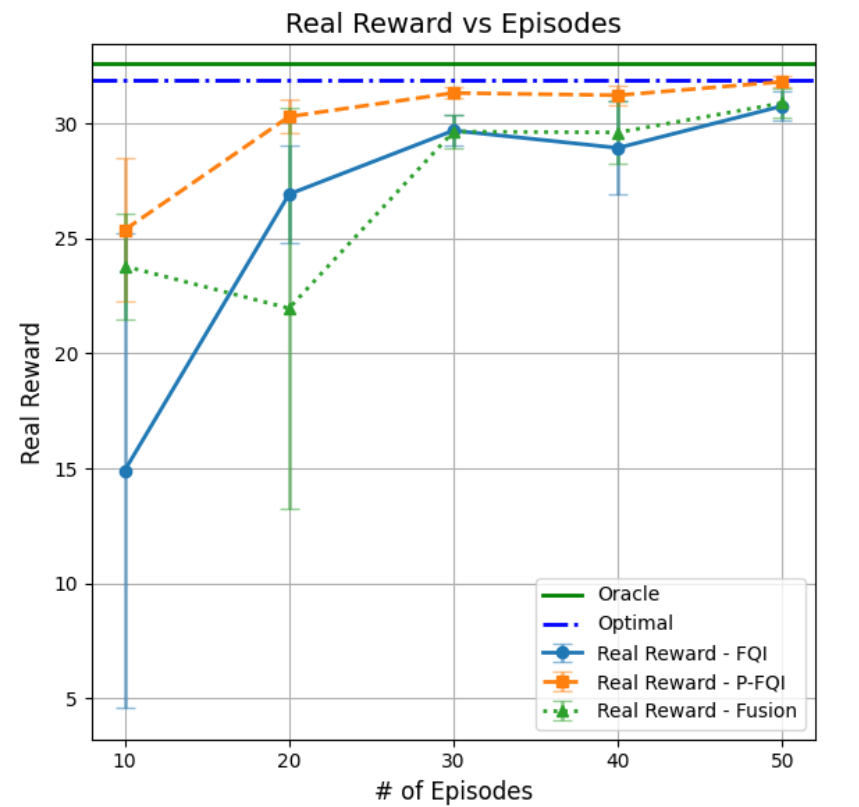
论文通过数值实验验证了所提出算法的有效性,证明其能够有效地估计最优定价和库存控制策略。此外,论文还提供了有限样本遗憾界限的理论分析,为算法的性能提供了理论保障。实验结果表明,该方法在处理审查和依赖需求问题时,能够显著优于传统方法。
🎯 应用场景
该研究成果可应用于零售、电商、供应链管理等领域,帮助企业在需求不确定且受历史销售影响的情况下,制定更优的定价和库存控制策略,从而提高利润和运营效率。尤其适用于存在销售数据审查(例如缺货导致的需求无法观测)的场景。
📄 摘要(原文)
In this paper, we study the offline sequential feature-based pricing and inventory control problem where the current demand depends on the past demand levels and any demand exceeding the available inventory is lost. Our goal is to leverage the offline dataset, consisting of past prices, ordering quantities, inventory levels, covariates, and censored sales levels, to estimate the optimal pricing and inventory control policy that maximizes long-term profit. While the underlying dynamic without censoring can be modeled by Markov decision process (MDP), the primary obstacle arises from the observed process where demand censoring is present, resulting in missing profit information, the failure of the Markov property, and a non-stationary optimal policy. To overcome these challenges, we first approximate the optimal policy by solving a high-order MDP characterized by the number of consecutive censoring instances, which ultimately boils down to solving a specialized Bellman equation tailored for this problem. Inspired by offline reinforcement learning and survival analysis, we propose two novel data-driven algorithms to solving these Bellman equations and, thus, estimate the optimal policy. Furthermore, we establish finite sample regret bounds to validate the effectiveness of these algorithms. Finally, we conduct numerical experiments to demonstrate the efficacy of our algorithms in estimating the optimal policy. To the best of our knowledge, this is the first data-driven approach to learning optimal pricing and inventory control policies in a sequential decision-making environment characterized by censored and dependent demand. The implementations of the proposed algorithms are available at https://github.com/gundemkorel/Inventory_Pricing_Control