Understanding and Optimizing Multi-Stage AI Inference Pipelines
作者: Abhimanyu Rajeshkumar Bambhaniya, Hanjiang Wu, Suvinay Subramanian, Sudarshan Srinivasan, Souvik Kundu, Amir Yazdanbakhsh, Midhilesh Elavazhagan, Madhu Kumar, Tushar Krishna
分类: cs.AR, cs.AI, cs.DC, cs.LG
发布日期: 2025-04-14 (更新: 2025-11-25)
备注: Inference System Design for Multi-Stage AI Inference Pipelines. 13 Pages, 15 Figues, 3 Tables
💡 一句话要点
HERMES:用于理解和优化多阶段AI推理流水线的异构执行模拟器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推理 异构计算 性能模拟 硬件架构 RAG KV缓存 多阶段流水线
📋 核心要点
- 现有模拟器无法准确建模异构、多引擎的LLM推理流水线,阻碍了硬件架构的优化。
- HERMES通过集成真实硬件追踪和分析建模,模拟异构硬件上的多阶段LLM推理过程。
- HERMES通过案例研究,分析了推理阶段的影响、最佳批处理策略和远程KV缓存的架构影响。
📝 摘要(中文)
大型语言模型(LLM)的快速发展推动了对日益复杂的推理流水线和硬件平台的需求。现代LLM服务超越了传统的预填充-解码工作流程,整合了检索增强生成(RAG)、键值(KV)缓存检索、动态模型路由和多步推理等多个阶段。这些阶段表现出不同的计算需求,需要集成GPU、ASIC、CPU和以内存为中心的架构的分布式系统。然而,现有的模拟器缺乏对这些异构、多引擎工作流程进行建模的保真度,限制了它们为架构决策提供信息的能力。为了解决这一差距,我们推出了HERMES,一个异构多阶段LLM推理执行模拟器。HERMES对包括RAG、KV检索、推理、预填充和解码等不同请求阶段进行建模,跨越复杂的硬件层次结构。与之前的框架不同,HERMES支持同时执行多个模型的异构客户端,同时结合了先进的批处理策略和多级内存层次结构。通过将真实硬件跟踪与分析建模相结合,HERMES捕捉了混合CPU-加速器部署中的关键权衡,如内存带宽争用、集群间通信延迟和批处理效率。通过案例研究,我们探讨了推理阶段对端到端延迟的影响、混合流水线的最佳批处理策略以及远程KV缓存检索的架构影响。HERMES使系统设计人员能够驾驭LLM推理的不断发展的格局,为优化下一代AI工作负载的硬件-软件协同设计提供可操作的见解。
🔬 方法详解
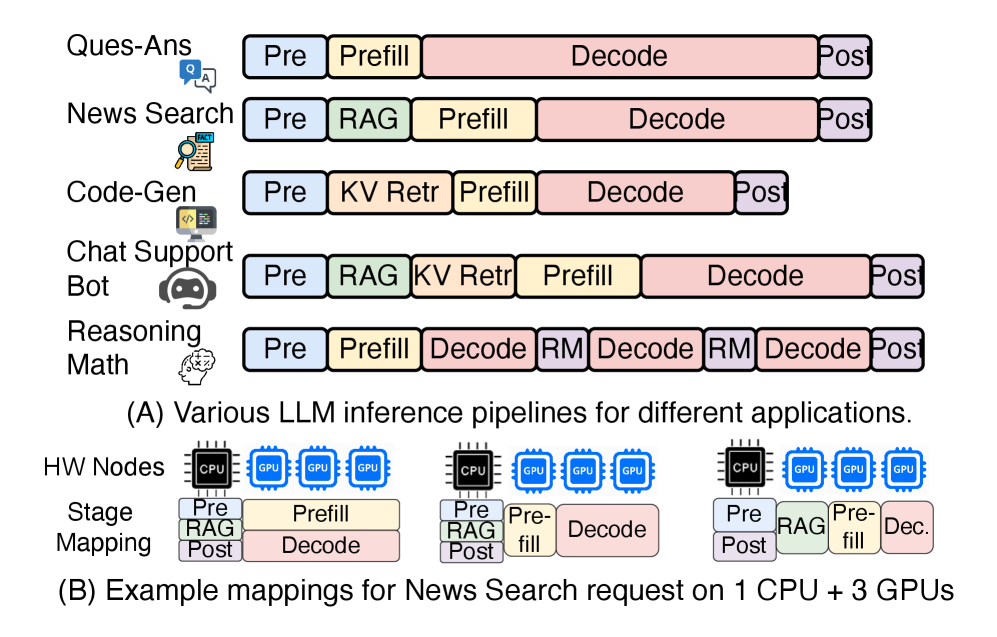
问题定义:现有LLM推理服务变得越来越复杂,包含RAG、KV缓存检索、动态模型路由和多步推理等多个阶段,这些阶段对硬件资源的需求各不相同。现有的模拟器无法准确地模拟这些异构的、多引擎的工作流程,导致无法有效地进行硬件架构的优化和选择。
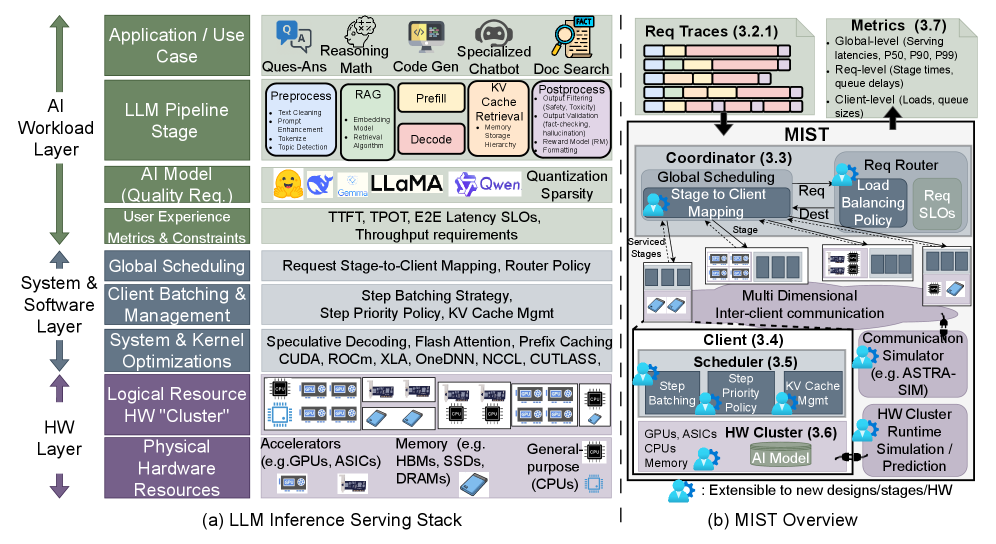
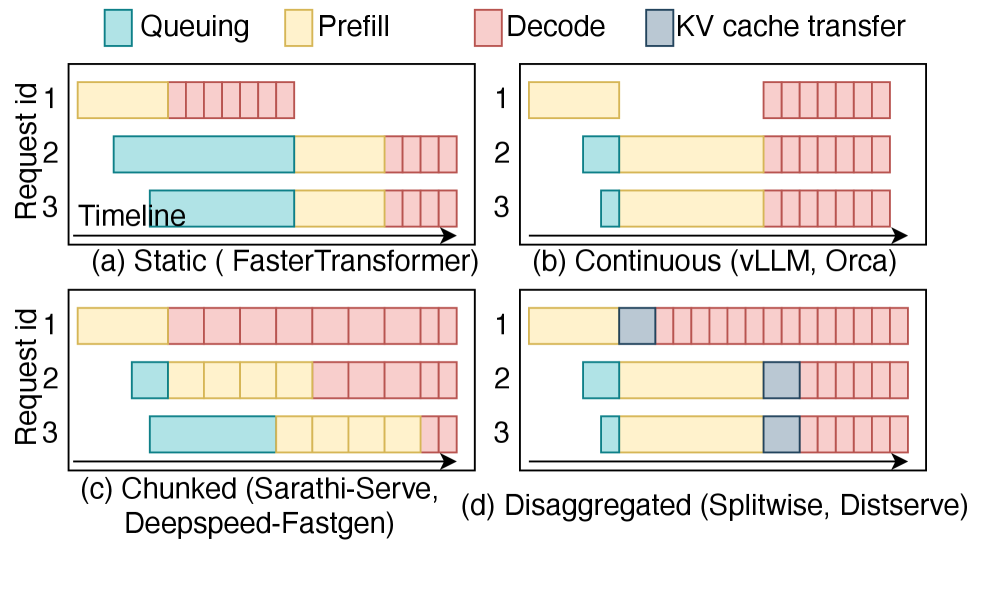
核心思路:HERMES的核心思路是构建一个高保真的、异构的LLM推理执行模拟器,它能够模拟不同类型的硬件(如CPU、GPU、ASIC)以及不同的推理阶段(如RAG、KV检索、推理、预填充、解码)。通过将真实硬件的追踪数据与分析模型相结合,HERMES能够捕捉到关键的性能瓶颈,如内存带宽争用、集群间通信延迟和批处理效率。
技术框架:HERMES的整体架构包含以下几个主要模块:1) 请求生成器:模拟不同类型的客户端请求,包括RAG、KV检索等;2) 硬件模型:模拟异构硬件平台,包括CPU、GPU、ASIC以及多级内存层次结构;3) 推理引擎模型:模拟不同的推理阶段,如预填充、解码、推理等;4) 调度器:负责将请求调度到不同的硬件资源上执行;5) 性能分析器:收集和分析模拟结果,提供性能瓶颈的分析报告。
关键创新:HERMES的关键创新在于它能够同时模拟异构硬件和多阶段的LLM推理过程。与现有的模拟器相比,HERMES能够更准确地捕捉到真实系统中的性能瓶颈,并为硬件架构的优化提供更有效的指导。此外,HERMES还支持先进的批处理策略和多级内存层次结构,使其能够更好地模拟现代LLM推理系统的复杂性。
关键设计:HERMES的关键设计包括:1) 使用真实硬件的追踪数据来校准硬件模型,提高模拟的准确性;2) 采用模块化的设计,方便扩展和定制;3) 支持多种批处理策略,如静态批处理、动态批处理等;4) 采用多级内存层次结构模型,模拟内存带宽争用和缓存效应;5) 提供详细的性能分析报告,帮助用户识别性能瓶颈。
🖼️ 关键图片
📊 实验亮点
通过案例研究,HERMES展示了推理阶段对端到端延迟的显著影响,揭示了混合流水线的最佳批处理策略,并阐明了远程KV缓存检索的架构影响。这些结果为优化LLM推理系统提供了宝贵的见解。
🎯 应用场景
HERMES可用于指导下一代AI硬件平台的设计和优化,例如,可以用于评估不同硬件架构对LLM推理性能的影响,优化批处理策略,以及设计更有效的内存层次结构。此外,HERMES还可以用于评估不同LLM模型的性能,并为模型部署提供指导。
📄 摘要(原文)
The rapid evolution of Large Language Models (LLMs) has driven the need for increasingly sophisticated inference pipelines and hardware platforms. Modern LLM serving extends beyond traditional prefill-decode workflows, incorporating multi-stage processes such as Retrieval Augmented Generation (RAG), key-value (KV) cache retrieval, dynamic model routing, and multi step reasoning. These stages exhibit diverse computational demands, requiring distributed systems that integrate GPUs, ASICs, CPUs, and memory-centric architectures. However, existing simulators lack the fidelity to model these heterogeneous, multi-engine workflows, limiting their ability to inform architectural decisions. To address this gap, we introduce HERMES, a Heterogeneous Multi-stage LLM inference Execution Simulator. HERMES models diverse request stages; including RAG, KV retrieval, reasoning, prefill, and decode across complex hardware hierarchies. HERMES supports heterogeneous clients executing multiple models concurrently unlike prior frameworks while incorporating advanced batching strategies and multi-level memory hierarchies. By integrating real hardware traces with analytical modeling, HERMES captures critical trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator deployments. Through case studies, we explore the impact of reasoning stages on end-to-end latency, optimal batching strategies for hybrid pipelines, and the architectural implications of remote KV cache retrieval. HERMES empowers system designers to navigate the evolving landscape of LLM inference, providing actionable insights into optimizing hardware-software co-design for next-generation AI workloads.