Understanding LLM Behaviors via Compression: Data Generation, Knowledge Acquisition and Scaling Laws
作者: Zhixuan Pan, Shaowen Wang, Jian Li
分类: cs.AI, cs.IT, cs.LG
发布日期: 2025-04-13 (更新: 2025-11-09)
💡 一句话要点
通过压缩理解LLM行为:数据生成、知识获取与缩放规律
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 压缩理论 知识获取 缩放规律 数据生成模型 柯尔莫哥洛夫复杂性 信息论 幻觉现象
📋 核心要点
- 现有LLM的缩放规律、幻觉等现象缺乏原理性解释,阻碍了对其底层机制的深入理解。
- 论文利用压缩和预测的经典关系,结合柯尔莫哥洛夫复杂性和香农信息论,分析LLM的行为。
- 提出了句法-知识模型,并在贝叶斯框架下分析了LLM的学习和缩放行为,实验验证了理论预测。
📝 摘要(中文)
大型语言模型(LLM)在众多任务中展现了卓越的能力,但对其底层机制和一些现象(如缩放规律、幻觉及相关行为)的原理性解释仍然难以捉摸。本文重新审视了压缩和预测之间的经典关系,该关系基于柯尔莫哥洛夫复杂性和香农信息论,以提供对LLM行为的更深入见解。通过利用柯尔莫哥洛夫结构函数并将LLM压缩解释为两部分编码过程,我们详细地了解了LLM如何在不断增长的模型和数据规模上获取和存储信息——从普遍存在的句法模式到逐渐稀有的知识元素。受此理论视角以及受Heap定律和Zipf定律启发的自然假设的推动,我们引入了一个简化的但具有代表性的分层数据生成框架,称为句法-知识模型。在贝叶斯设置下,我们表明该模型中的预测和压缩自然会导致LLM中观察到的各种学习和缩放行为。特别是,我们的理论分析为数据和模型缩放规律、训练和微调期间的知识获取动态以及LLM中的事实知识幻觉提供了直观且有原则的解释。实验结果验证了我们的理论预测。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中缩放规律、幻觉等现象缺乏理论解释的问题。现有方法难以从根本上理解LLM的行为,阻碍了模型优化和可靠性提升。
核心思路:论文的核心思路是将LLM的训练过程视为一个压缩过程,利用柯尔莫哥洛夫复杂性和香农信息论来分析LLM如何获取和存储信息。通过研究压缩过程,可以揭示LLM的学习机制和行为模式。
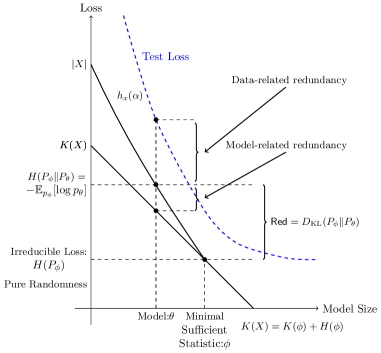
技术框架:论文提出了一个名为“句法-知识模型”的分层数据生成框架。该框架模拟了数据中句法结构和知识元素的分布,并在此基础上分析LLM的预测和压缩行为。整体流程包括:1)构建句法-知识模型;2)在贝叶斯框架下分析模型的预测和压缩特性;3)推导数据和模型缩放规律;4)解释知识获取动态和幻觉现象;5)实验验证理论预测。
关键创新:论文的关键创新在于将压缩理论应用于理解LLM的行为,并提出了句法-知识模型。该模型能够捕捉数据中的分层结构,并为LLM的学习和缩放行为提供直观的解释。与现有方法相比,该方法更加注重理论分析,并能够从根本上理解LLM的内在机制。
关键设计:句法-知识模型的设计灵感来源于Heap定律和Zipf定律,假设数据中存在普遍的句法模式和稀有的知识元素。模型参数包括句法模式的分布、知识元素的分布以及模型容量等。论文在贝叶斯框架下分析了模型的预测和压缩特性,并推导了数据和模型缩放规律。具体的损失函数和网络结构设计未在论文信息中体现,属于未知信息。
🖼️ 关键图片
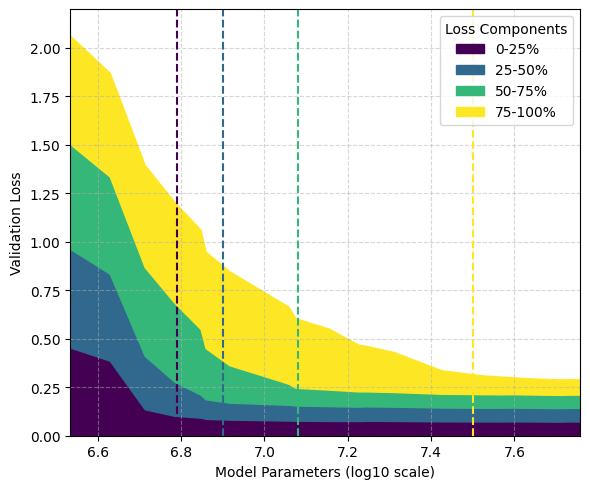

📊 实验亮点
论文通过实验验证了理论预测,表明句法-知识模型能够有效地模拟LLM的学习和缩放行为。实验结果支持了论文提出的关于数据和模型缩放规律、知识获取动态和幻觉现象的解释。具体的性能数据和提升幅度未在论文信息中体现,属于未知信息。
🎯 应用场景
该研究成果可应用于LLM的优化和改进,例如指导数据选择、模型设计和训练策略。通过理解LLM的内在机制,可以提高模型的性能、可靠性和可解释性。此外,该研究还可以帮助我们更好地理解人类语言和知识的本质。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities across numerous tasks, yet principled explanations for their underlying mechanisms and several phenomena, such as scaling laws, hallucinations, and related behaviors, remain elusive. In this work, we revisit the classical relationship between compression and prediction, grounded in Kolmogorov complexity and Shannon information theory, to provide deeper insights into LLM behaviors. By leveraging the Kolmogorov Structure Function and interpreting LLM compression as a two-part coding process, we offer a detailed view of how LLMs acquire and store information across increasing model and data scales -- from pervasive syntactic patterns to progressively rarer knowledge elements. Motivated by this theoretical perspective and natural assumptions inspired by Heap's and Zipf's laws, we introduce a simplified yet representative hierarchical data-generation framework called the Syntax-Knowledge model. Under the Bayesian setting, we show that prediction and compression within this model naturally lead to diverse learning and scaling behaviors observed in LLMs. In particular, our theoretical analysis offers intuitive and principled explanations for both data and model scaling laws, the dynamics of knowledge acquisition during training and fine-tuning, factual knowledge hallucinations in LLMs. The experimental results validate our theoretical predictions.