A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
作者: Zixuan Ke, Fangkai Jiao, Yifei Ming, Xuan-Phi Nguyen, Austin Xu, Do Xuan Long, Minzhi Li, Chengwei Qin, Peifeng Wang, Silvio Savarese, Caiming Xiong, Shafiq Joty
分类: cs.AI, cs.CL
发布日期: 2025-04-12 (更新: 2025-08-05)
备注: 72 pages, 6 figures. Accepted to TMLR, with Survey Certification award
💡 一句话要点
综述LLM推理前沿:推理规模化、学习推理及Agent系统
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 Agent系统 思维链 提示工程
📋 核心要点
- 现有LLM在复杂推理任务中面临挑战,需要更有效的推理方法和架构。
- 该综述对LLM推理方法进行系统分类,涵盖推理机制、架构、输入输出优化等方面。
- 综述强调了从推理规模化到学习推理的转变,以及Agent系统在LLM推理中的作用。
📝 摘要(中文)
推理是实现逻辑推断、问题解决和决策制定的基本认知过程。随着大型语言模型(LLM)的快速发展,推理已成为区分高级AI系统与传统聊天机器人模型的关键能力。本综述将现有方法沿两个正交维度进行分类:(1)机制,定义了实现推理的阶段(推理时或通过专门训练);(2)架构,确定了推理过程中涉及的组件,区分了独立的LLM和包含外部工具的Agent复合系统以及多Agent协作。在每个维度内,我们分析了两个关键视角:(1)输入层面,侧重于构建LLM所依赖的高质量提示的技术;(2)输出层面,侧重于改进多个采样候选以提高推理质量的方法。这种分类系统地理解了LLM推理的演进格局,突出了新兴趋势,例如从推理规模化到学习推理的转变(例如,DeepSeek-R1),以及向Agent工作流的过渡(例如,OpenAI Deep Research,Manus Agent)。此外,我们还涵盖了广泛的学习算法,从监督微调到强化学习(如PPO和GRPO),以及推理器和验证器的训练。我们还研究了Agent工作流的关键设计,从生成器-评估器和LLM辩论等既定模式到最新创新。
🔬 方法详解
问题定义:现有大型语言模型(LLM)在复杂推理任务中面临挑战,例如逻辑推理、问题解决和决策制定。传统的LLM方法往往依赖于大规模的参数和数据,但缺乏有效的推理机制,导致在复杂任务上的表现不佳。此外,如何有效地利用外部知识和工具来增强LLM的推理能力也是一个重要的挑战。
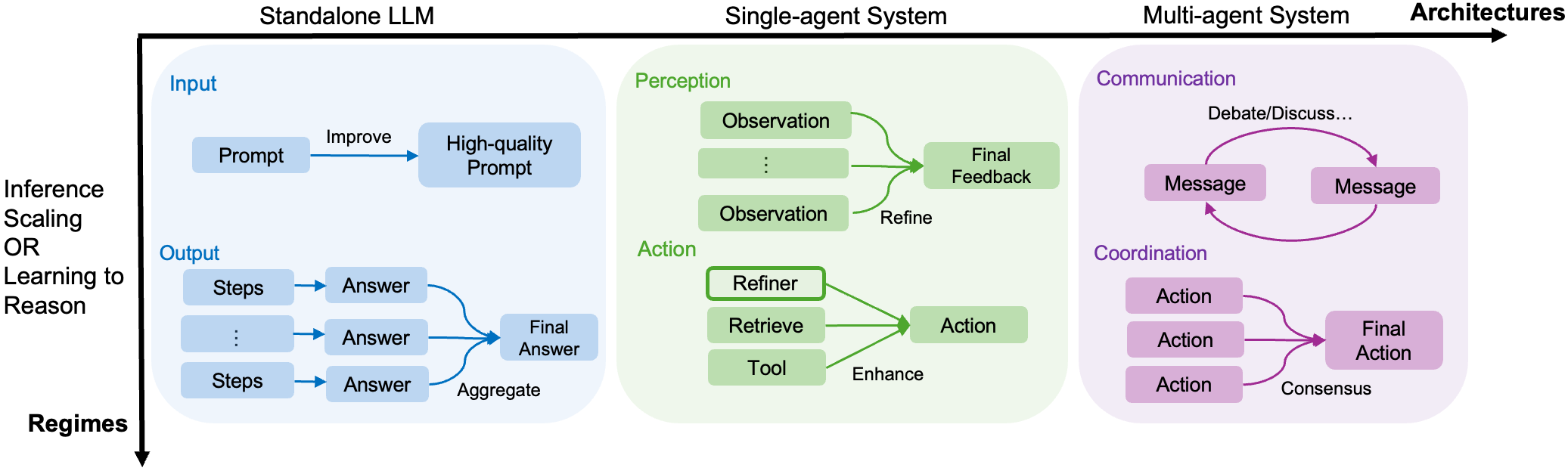
核心思路:本综述的核心思路是将现有的LLM推理方法按照两个正交的维度进行分类:推理机制(推理时或训练时)和架构(独立LLM或Agent系统)。通过这种分类,可以系统地理解LLM推理的演进格局,并突出新兴趋势。同时,综述还关注输入和输出层面的优化技术,以及各种学习算法和Agent工作流的设计。
技术框架:该综述没有提出新的技术框架,而是对现有技术进行了梳理和分类。主要框架包括:1) 推理机制:包括推理时的方法(例如,思维链)和训练时的方法(例如,微调);2) 架构:包括独立LLM和Agent系统(包含外部工具和多Agent协作);3) 输入层面:包括提示工程等技术;4) 输出层面:包括采样和排序等技术;5) 学习算法:包括监督学习、强化学习等。
关键创新:该综述的创新之处在于其系统性的分类方法,将LLM推理方法按照推理机制和架构两个维度进行划分,从而提供了一个更清晰和全面的视角。此外,综述还强调了从推理规模化到学习推理的转变,以及Agent系统在LLM推理中的作用,这些都是LLM推理领域的重要发展趋势。
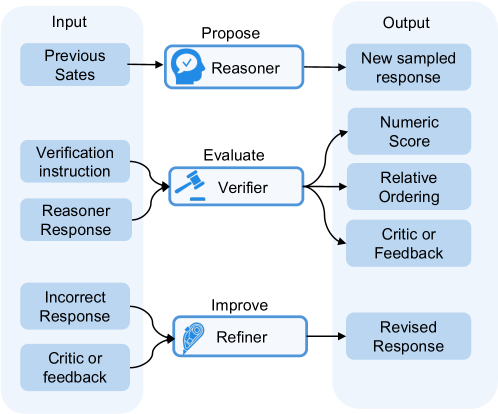
关键设计:该综述主要关注现有方法的分类和分析,没有涉及具体的技术细节。但是,综述中提到了各种学习算法(例如,PPO和GRPO)和Agent工作流(例如,生成器-评估器和LLM辩论)的设计,这些都是LLM推理领域的重要技术细节。
🖼️ 关键图片
📊 实验亮点
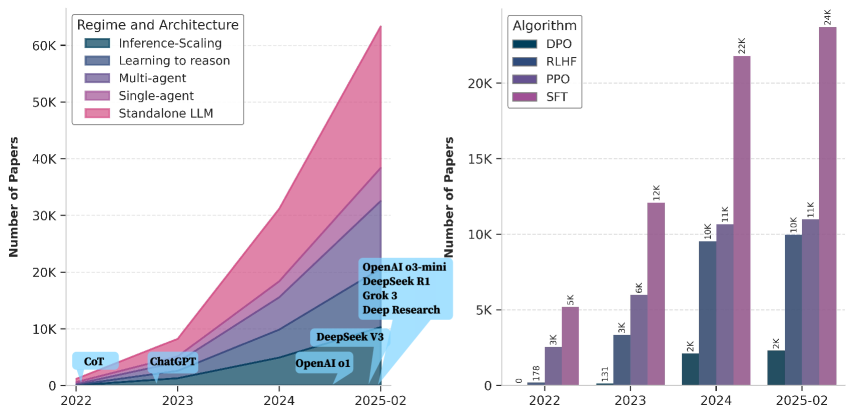
该综述强调了从推理规模化到学习推理的转变,并突出了Agent系统在LLM推理中的作用。例如,DeepSeek-R1代表了学习推理的趋势,而OpenAI Deep Research和Manus Agent则代表了Agent工作流的发展方向。这些趋势表明,未来的LLM推理将更加注重模型的学习能力和与外部环境的交互能力。
🎯 应用场景
该研究对LLM推理技术的应用具有广泛的指导意义,可应用于智能客服、自动驾驶、金融分析、医疗诊断等领域。通过提升LLM的推理能力,可以构建更智能、更可靠的AI系统,从而解决更复杂的问题,并为人类提供更好的服务。
📄 摘要(原文)
Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multi-agent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. ...