RTLRepoCoder: Repository-Level RTL Code Completion through the Combination of Fine-Tuning and Retrieval Augmentation
作者: Peiyang Wu, Nan Guo, Junliang Lv, Xiao Xiao, Xiaochun Ye
分类: cs.SE, cs.AI
发布日期: 2025-04-11
💡 一句话要点
RTLRepoCoder:结合微调与检索增强,实现仓库级RTL代码补全
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RTL代码生成 代码补全 大型语言模型 检索增强生成 硬件设计自动化
📋 核心要点
- 现有方法难以处理大型RTL代码仓库,面临长上下文管理和跨文件依赖的挑战。
- RTLRepoCoder通过领域微调和检索增强生成,实现仓库级Verilog代码补全。
- 实验表明,该方法在公共基准测试上超越GPT-4和领域特定LLM,性能显著提升。
📝 摘要(中文)
现代硬件设计中,手动编写寄存器传输级(RTL)代码(如Verilog)非常耗时。大型语言模型(LLM)的巨大成功促使研究人员探索利用LLM生成RTL代码。然而,当前研究主要集中于生成简单的单个模块,无法满足实际需求。由于管理长上下文RTL代码和复杂跨文件依赖关系的挑战,现有解决方案无法处理实际硬件开发中的大型Verilog仓库。我们提出了RTLRepoCoder,这是一种开创性的解决方案,它结合了特定领域的微调和检索增强生成(RAG),用于仓库级Verilog代码补全。使用来自真实世界的开源Verilog仓库以及扩展的上下文大小进行领域特定的微调。优化的RAG系统通过检索相关代码片段来提高输入上下文的信息密度。对RAG进行了定制优化,包括嵌入模型、跨文件上下文分割策略和块大小。我们的解决方案在公共基准测试上实现了最先进的性能,在编辑相似度和精确匹配率方面显著超过了GPT-4和先进的领域特定LLM。全面的实验证明了我们方法的显著有效性,并为未来的工作提供了见解。
🔬 方法详解
问题定义:现有方法在利用大型语言模型生成RTL代码时,主要集中于单个模块,无法有效处理实际硬件开发中大型Verilog代码仓库。主要痛点在于难以管理长上下文的RTL代码,以及处理复杂的跨文件依赖关系,导致生成质量不高。
核心思路:RTLRepoCoder的核心思路是结合领域特定的微调和检索增强生成(RAG),从而使LLM能够更好地理解和生成仓库级别的RTL代码。通过RAG,模型可以检索相关的代码片段,从而提高输入上下文的信息密度,更好地利用已有知识。
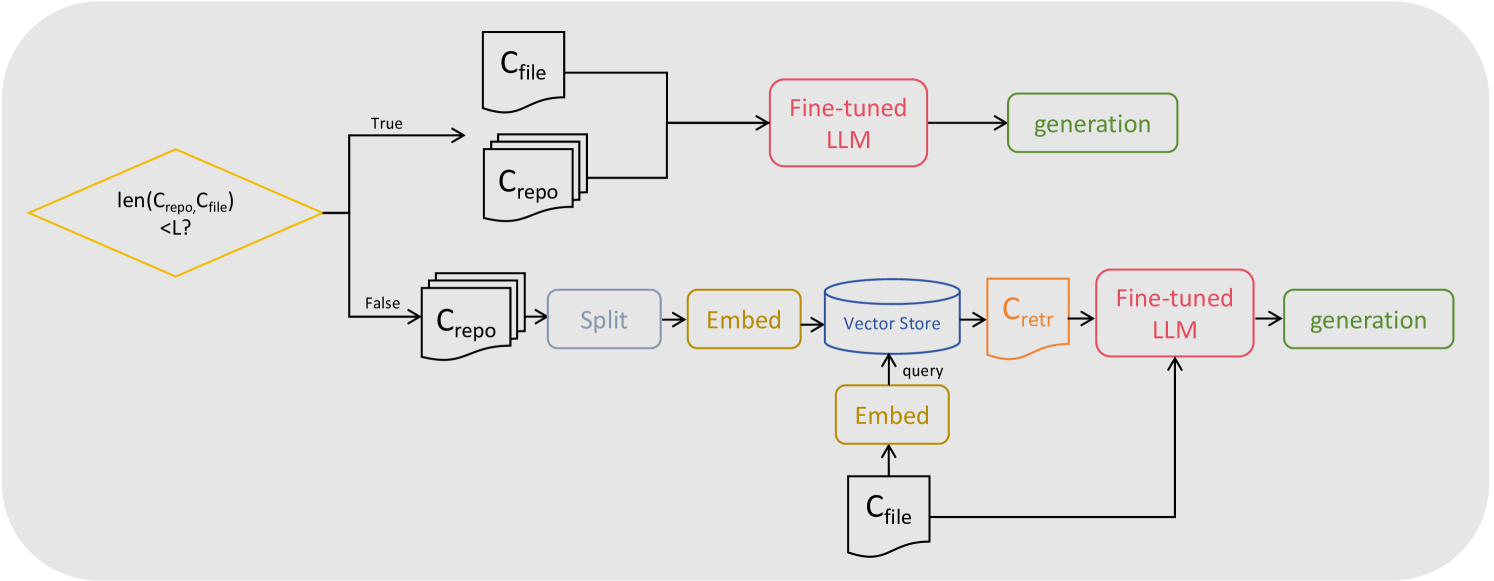
技术框架:RTLRepoCoder的整体框架包括以下几个主要阶段:1) 使用开源Verilog仓库进行领域特定微调,扩展LLM的上下文处理能力。2) 构建优化的RAG系统,包括嵌入模型选择、跨文件上下文分割策略和块大小优化。3) 利用微调后的LLM和RAG系统进行代码补全。
关键创新:RTLRepoCoder的关键创新在于将RAG应用于仓库级别的RTL代码生成,并针对RTL代码的特点进行了定制优化。这包括针对RTL代码的嵌入模型选择、跨文件上下文分割策略和块大小优化,从而提高了RAG系统的检索效率和准确性。
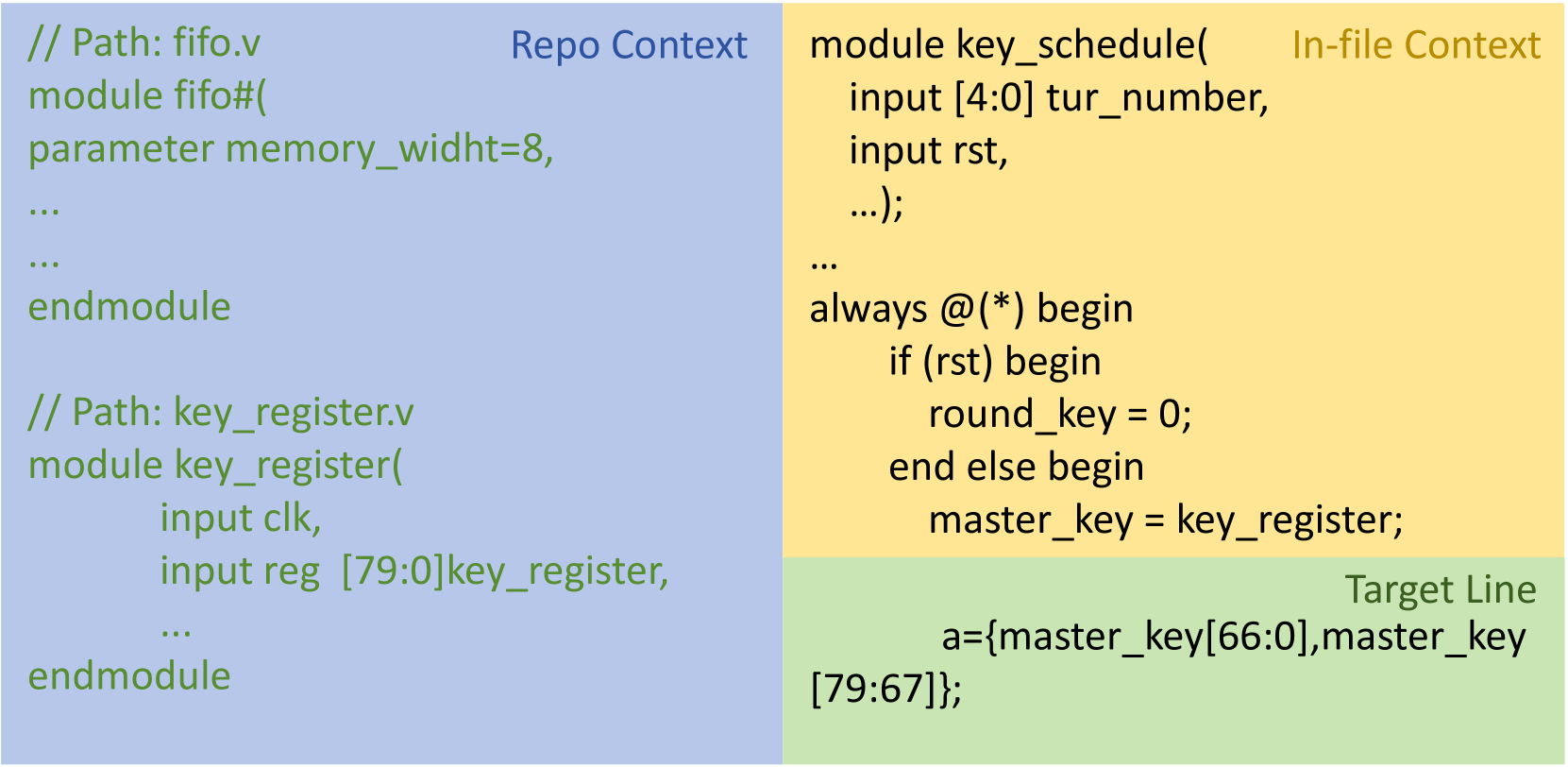
关键设计:RTLRepoCoder的关键设计包括:1) 使用真实世界的开源Verilog仓库进行微调,保证模型的实用性。2) 针对RTL代码的特点,优化RAG系统的各个环节,例如,设计合适的跨文件上下文分割策略,以保证检索到的代码片段包含必要的依赖关系。3) 通过实验选择合适的嵌入模型和块大小,以提高检索效率和准确性。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
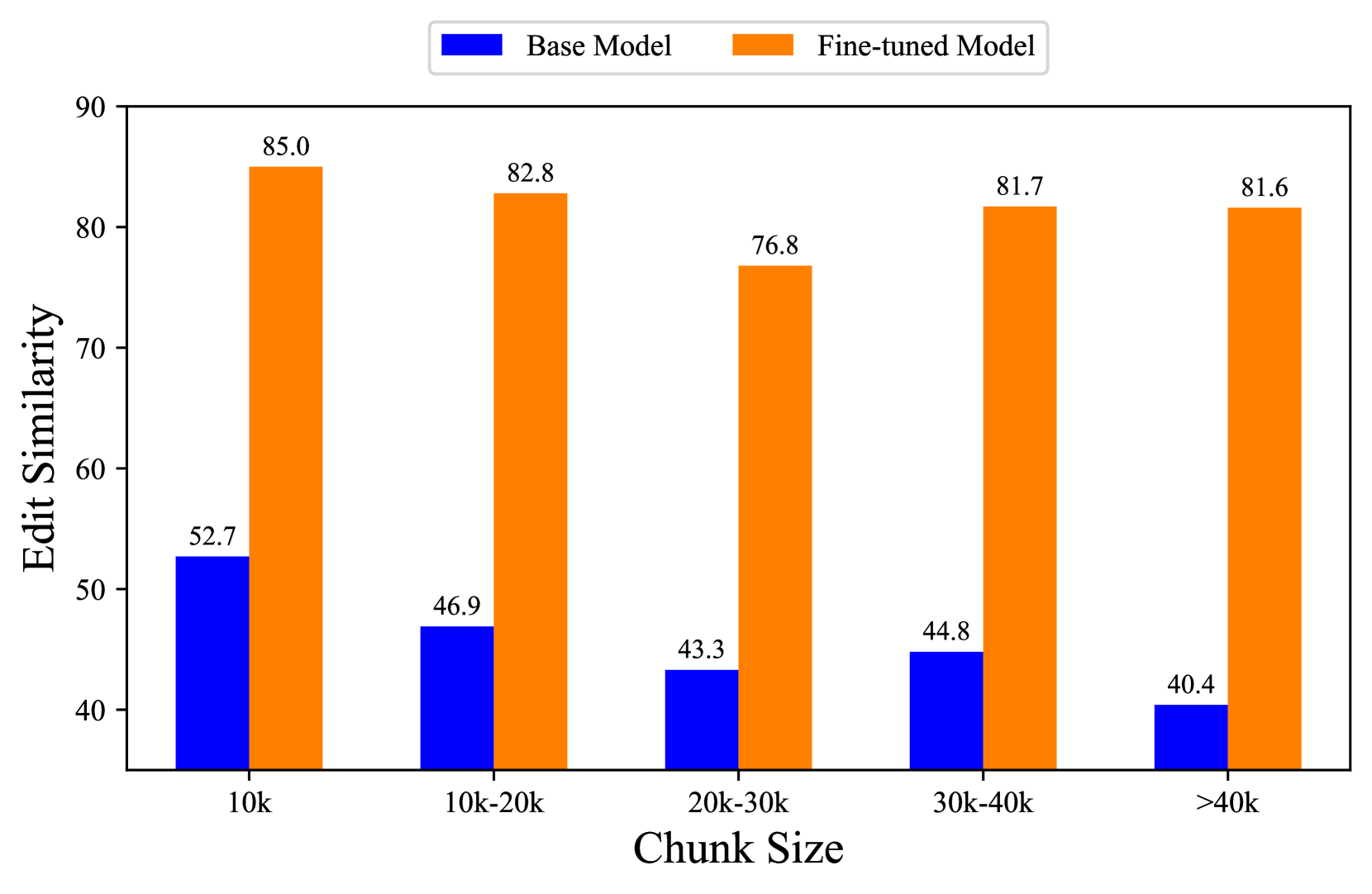
RTLRepoCoder在公共基准测试上取得了最先进的性能,显著超越了GPT-4和先进的领域特定LLM。具体而言,在编辑相似度和精确匹配率方面均取得了显著提升,表明该方法在仓库级RTL代码补全任务上的有效性。具体的性能数据和提升幅度在摘要中有所提及,但在论文信息中未给出具体数值。
🎯 应用场景
RTLRepoCoder可应用于硬件设计自动化领域,加速Verilog代码的编写过程,提高硬件开发效率。该研究成果有助于降低硬件设计的门槛,促进更复杂、更高效的硬件系统的开发。未来,该方法可以扩展到其他硬件描述语言和更复杂的硬件设计任务。
📄 摘要(原文)
As an essential part of modern hardware design, manually writing Register Transfer Level (RTL) code such as Verilog is often labor-intensive. Following the tremendous success of large language models (LLMs), researchers have begun to explore utilizing LLMs for generating RTL code. However, current studies primarily focus on generating simple single modules, which can not meet the demands in real world. In fact, due to challenges in managing long-context RTL code and complex cross-file dependencies, existing solutions cannot handle large-scale Verilog repositories in practical hardware development. As the first endeavor to exclusively adapt LLMs for large-scale RTL development, we propose RTLRepoCoder, a groundbreaking solution that incorporates specific fine-tuning and Retrieval-Augmented Generation (RAG) for repository-level Verilog code completion. Open-source Verilog repositories from the real world, along with an extended context size, are used for domain-specific fine-tuning. The optimized RAG system improves the information density of the input context by retrieving relevant code snippets. Tailored optimizations for RAG are carried out, including the embedding model, the cross-file context splitting strategy, and the chunk size. Our solution achieves state-of-the-art performance on public benchmark, significantly surpassing GPT-4 and advanced domain-specific LLMs on Edit Similarity and Exact Match rate. Comprehensive experiments demonstrate the remarkable effectiveness of our approach and offer insights for future work.