USM-VC: Mitigating Timbre Leakage with Universal Semantic Mapping Residual Block for Voice Conversion
作者: Na Li, Chuke Wang, Yu Gu, Zhifeng Li
分类: eess.AS, cs.AI, cs.SD
发布日期: 2025-04-11 (更新: 2025-06-27)
💡 一句话要点
提出USM-VC,通过通用语义映射残差块缓解语音转换中的音色泄露问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 语音转换 音色泄露 内容表示 通用语义字典 残差块
📋 核心要点
- 语音转换中,源说话人音色信息嵌入内容表示,导致音色泄露,降低转换后语音与目标说话人的相似度。
- 提出USM-VC,利用通用语义匹配残差块,通过内容特征重表达模块提取无音色的内容表示,并结合跳跃连接保留细粒度信息。
- 实验结果表明,该方法能有效缓解音色泄露,显著提升转换后语音与目标说话人的相似度。
📝 摘要(中文)
语音转换(VC)旨在保留内容的同时将源语音转换为目标语音。然而,源说话人的音色信息固有地嵌入在内容表示中,导致显著的音色泄露,降低了与目标说话人的相似度。为了解决这个问题,我们向内容提取器引入了一个通用语义匹配(USM)残差块。该残差块由两个加权分支组成:1) 基于通用语义字典的内容特征重表达(CFR)模块,提供无音色的内容表示;2) 到原始内容层的跳跃连接,提供互补的细粒度信息。在CFR模块中,通用语义字典中的每个字典条目代表一个音素类,通过使用来自多个说话人的语音进行统计计算,从而创建一个稳定的、与说话人无关的语义集。我们引入了一种CFR方法,通过使用相应的音素后验概率作为权重,将每个内容帧表示为字典条目的加权线性组合,从而获得无音色的内容表示。跨各种VC框架的广泛实验表明,我们的方法有效地缓解了音色泄露,并显著提高了与目标说话人的相似度。
🔬 方法详解
问题定义:语音转换(VC)旨在将源说话人的语音转换为目标说话人的语音,同时保留语音的内容信息。然而,现有方法的一个主要痛点是音色泄露,即转换后的语音仍然带有源说话人的音色特征,导致与目标说话人的相似度降低。这是因为内容表示中不可避免地包含了源说话人的音色信息。
核心思路:本文的核心思路是设计一个能够提取与说话人无关的、纯粹内容表示的模块。通过构建一个通用的、与说话人无关的语义字典,并将内容特征映射到这个语义空间,从而去除音色信息。同时,为了保留细粒度的内容信息,引入了跳跃连接,将原始内容特征与去除了音色信息的内容特征进行融合。
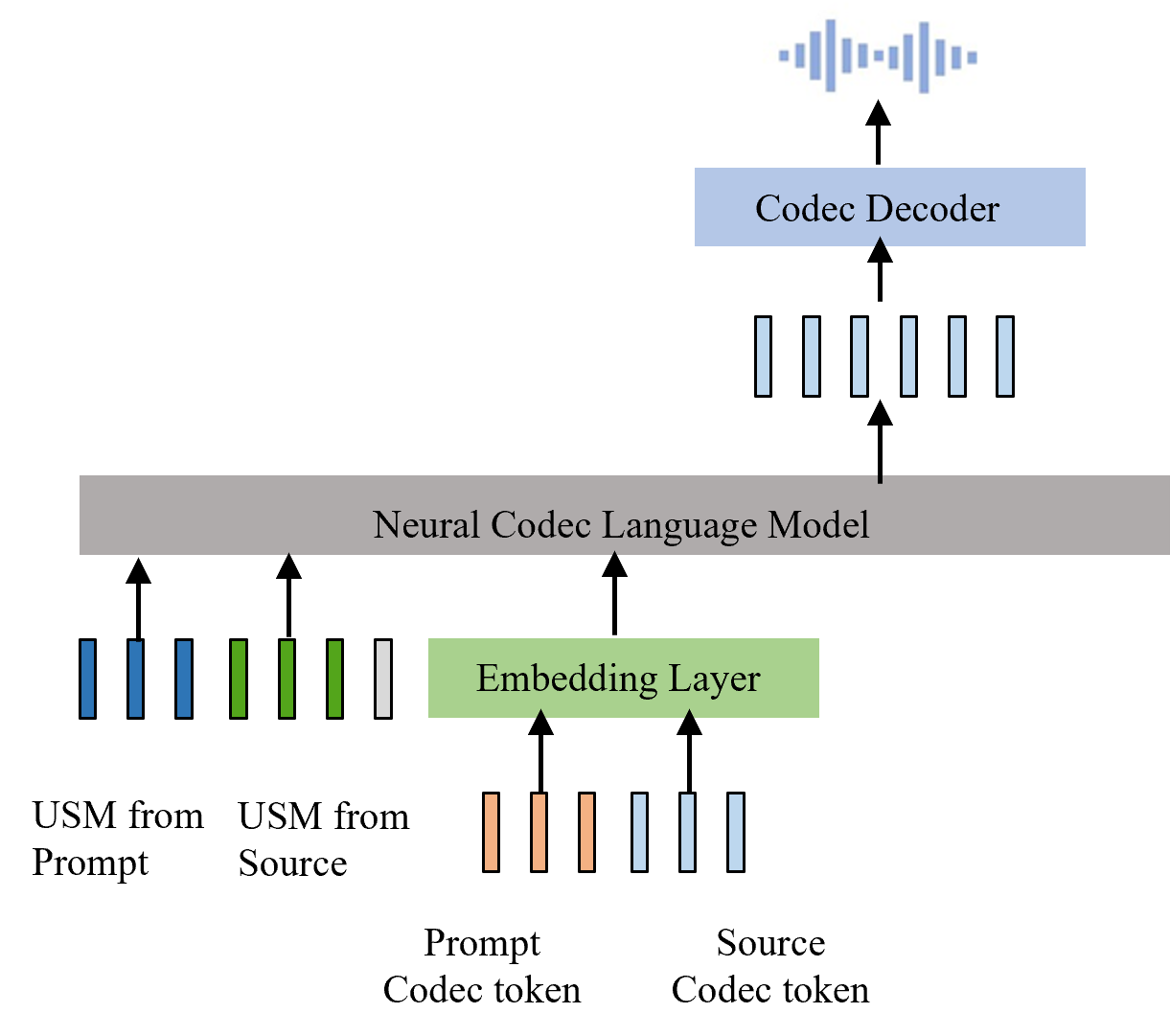
技术框架:USM-VC方法的核心在于在内容提取器中引入一个USM残差块。该残差块包含两个分支:一个是基于通用语义字典的CFR模块,用于提取无音色的内容表示;另一个是跳跃连接,用于保留原始内容特征中的细粒度信息。CFR模块首先将输入的内容特征映射到通用语义字典中的各个条目,然后使用音素后验概率作为权重,将这些条目进行加权组合,得到最终的无音色内容表示。最后,将CFR模块的输出与跳跃连接的输出进行加权融合,得到最终的内容表示。
关键创新:该方法最重要的创新点在于提出了通用语义字典和CFR模块。通用语义字典通过统计多个说话人的语音数据构建,每个条目代表一个音素类,从而保证了其与说话人无关性。CFR模块利用音素后验概率作为权重,将内容特征映射到通用语义字典,从而有效地去除了音色信息。与现有方法相比,该方法能够更有效地提取纯粹的内容表示,从而缓解音色泄露问题。
关键设计:通用语义字典的构建是关键。论文中使用来自多个说话人的语音数据,对每个音素类进行统计建模,得到该音素类的代表性特征向量。CFR模块中,音素后验概率的计算也至关重要,它决定了内容特征在通用语义字典中的映射权重。此外,USM残差块中两个分支的权重也是一个重要的超参数,需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,USM-VC方法在各种语音转换框架下均能有效缓解音色泄露,显著提高转换后语音与目标说话人的相似度。具体而言,与基线方法相比,USM-VC在说话人相似度指标上取得了显著提升,证明了其有效性。
🎯 应用场景
USM-VC技术可应用于语音合成、语音编辑、个性化语音助手等领域。通过消除音色泄露,可以生成更自然、更接近目标说话人音色的语音,提升用户体验。该技术还有助于实现更灵活的语音内容创作和编辑,例如将一个人的语音内容转换为另一个人的音色。
📄 摘要(原文)
Voice conversion (VC) transforms source speech into a target voice by preserving the content. However, timbre information from the source speaker is inherently embedded in the content representations, causing significant timbre leakage and reducing similarity to the target speaker. To address this, we introduce a Universal Semantic Matching (USM) residual block to a content extractor. The residual block consists of two weighted branches: 1) universal semantic dictionary based Content Feature Re-expression (CFR) module, supplying timbre-free content representation. 2) skip connection to the original content layer, providing complementary fine-grained information. In the CFR module, each dictionary entry in the universal semantic dictionary represents a phoneme class, computed statistically using speech from multiple speakers, creating a stable, speaker-independent semantic set. We introduce a CFR method to obtain timbre-free content representations by expressing each content frame as a weighted linear combination of dictionary entries using corresponding phoneme posteriors as weights. Extensive experiments across various VC frameworks demonstrate that our approach effectively mitigates timbre leakage and significantly improves similarity to the target speaker.