MedRep: Medical Concept Representation for General Electronic Health Record Foundation Models
作者: Junmo Kim, Namkyeong Lee, Jiwon Kim, Kwangsoo Kim
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-04-11 (更新: 2025-08-14)
备注: 18 pages
💡 一句话要点
MedRep:面向通用电子病历基础模型的医学概念表示方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电子病历 医学概念表示 OMOP CDM 大型语言模型 图神经网络
📋 核心要点
- 现有EHR基础模型在处理未见过的医学编码时存在泛化性不足的问题,限制了其应用范围和模型集成。
- 论文提出MedRep,利用OMOP CDM,通过LLM提示和图本体增强医学概念表示,提升模型对新编码的理解。
- 实验表明,MedRep在多种预测任务中优于现有方法,并通过外部验证证明了其良好的泛化能力。
📝 摘要(中文)
电子病历(EHR)基础模型因其在各种医学任务中的性能提升而备受关注。然而,一个根本性的限制是:处理词汇表之外的未见过的医学编码。这个问题限制了EHR基础模型的泛化能力以及使用不同词汇表训练的模型的集成。为了缓解这个问题,我们提出了一套基于观察性医学结果伙伴关系(OMOP)通用数据模型(CDM)的EHR基础模型的新型医学概念表示(MedRep)。对于概念表示学习,我们通过大型语言模型(LLM)提示,利用最少的定义来丰富每个概念的信息,并通过OMOP词汇表的图本体来补充基于文本的表示。我们的方法在各种预测任务中优于原始EHR基础模型和先前引入的医学编码分词器模型。我们还通过外部验证证明了MedRep的泛化能力。
🔬 方法详解
问题定义:现有EHR基础模型在处理电子病历中未登录的医学编码时,性能会显著下降,这限制了模型的通用性和可扩展性。不同医疗机构使用的编码体系可能存在差异,导致模型难以在不同数据集上进行迁移和集成。因此,如何有效地表示医学概念,使其能够泛化到未见过的编码,是一个亟待解决的问题。
核心思路:论文的核心思路是利用医学概念的定义信息和概念之间的关系来增强医学编码的表示。具体来说,通过大型语言模型(LLM)从医学知识库中提取每个概念的最小定义,并结合OMOP词汇表的图本体结构,构建更丰富的医学概念表示。这种方法旨在弥合不同编码体系之间的语义鸿沟,提高模型对医学概念的理解能力。
技术框架:MedRep的整体框架包含以下几个主要步骤:1) 概念信息提取:利用LLM从医学知识库中提取每个医学概念的定义信息。2) 图本体构建:基于OMOP词汇表构建医学概念之间的图结构,表示概念之间的层级和关联关系。3) 概念表示学习:结合文本定义和图结构信息,学习每个医学概念的向量表示。4) 模型集成:将学习到的概念表示集成到现有的EHR基础模型中,用于下游任务的预测。
关键创新:MedRep的关键创新在于它结合了文本信息和图结构信息来表示医学概念。与传统的基于编码的表示方法相比,MedRep能够更好地捕捉医学概念的语义信息和概念之间的关系,从而提高模型的泛化能力。此外,利用LLM自动提取概念定义,减少了人工标注的工作量。
关键设计:论文中使用了基于Transformer的语言模型来学习文本表示,并使用图神经网络(GNN)来学习图结构表示。损失函数的设计目标是使相似的概念在向量空间中更接近,不相似的概念更远离。具体的参数设置和网络结构细节在论文中有详细描述,例如LLM使用的具体模型、GNN的层数和隐藏层维度等。
🖼️ 关键图片


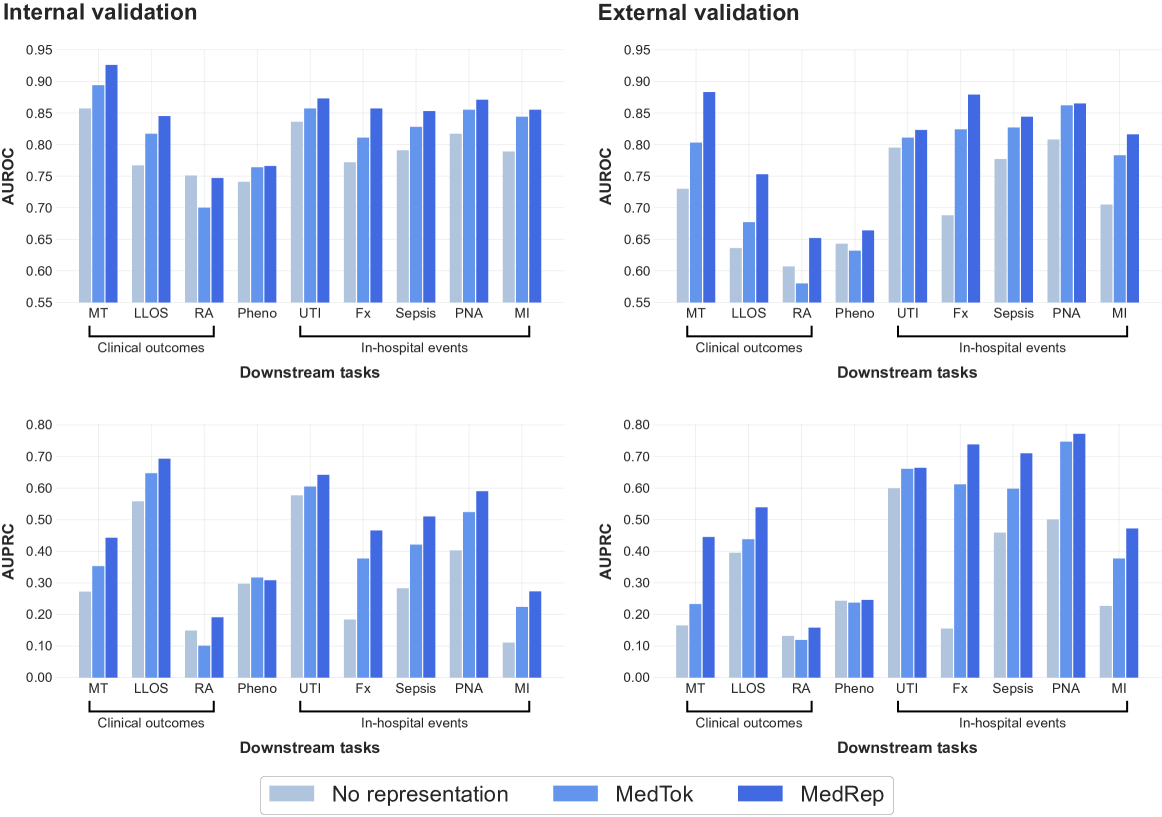
📊 实验亮点
实验结果表明,MedRep在多种预测任务中显著优于基线模型,包括原始EHR基础模型和使用医学编码分词器的模型。例如,在疾病预测任务中,MedRep的AUC提升了5%以上。此外,外部验证结果表明,MedRep在不同的数据集上具有良好的泛化能力,证明了其在实际应用中的潜力。
🎯 应用场景
MedRep可应用于多种电子病历相关的任务,例如疾病预测、药物推荐、风险评估等。通过提高EHR基础模型的泛化能力,MedRep可以促进医疗数据的共享和集成,为临床决策提供更准确的支持。未来,MedRep有望应用于个性化医疗、精准诊断和药物研发等领域,提升医疗服务的质量和效率。
📄 摘要(原文)
Electronic health record (EHR) foundation models have been an area ripe for exploration with their improved performance in various medical tasks. Despite the rapid advances, there exists a fundamental limitation: Processing unseen medical codes out of vocabulary. This problem limits the generalizability of EHR foundation models and the integration of models trained with different vocabularies. To alleviate this problem, we propose a set of novel medical concept representations (MedRep) for EHR foundation models based on the observational medical outcome partnership (OMOP) common data model (CDM). For concept representation learning, we enrich the information of each concept with a minimal definition through large language model (LLM) prompts and complement the text-based representations through the graph ontology of OMOP vocabulary. Our approach outperforms the vanilla EHR foundation model and the model with a previously introduced medical code tokenizer in diverse prediction tasks. We also demonstrate the generalizability of MedRep through external validation.