On the Effectiveness and Generalization of Race Representations for Debiasing High-Stakes Decisions
作者: Dang Nguyen, Chenhao Tan
分类: cs.CY, cs.AI, cs.CL, cs.LG
发布日期: 2025-04-07 (更新: 2025-10-03)
备注: 21 pages, 15 figures, 14 tables. Accepted as a conference paper at COLM 2025. Camera-ready
💡 一句话要点
利用种族表征进行偏差校正,但通用性仍具挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 种族偏见 公平性 偏差校正 表征学习
📋 核心要点
- 大型语言模型在高风险决策中存在种族偏见,传统提示工程方法难以有效缓解。
- 论文提出通过识别和干预模型激活中的“种族子空间”来消除偏差,核心思想是平均不同种族的表征。
- 实验表明,该方法能有效降低Gemma模型的种族偏见,但种族表征的通用性仍有待提高。
📝 摘要(中文)
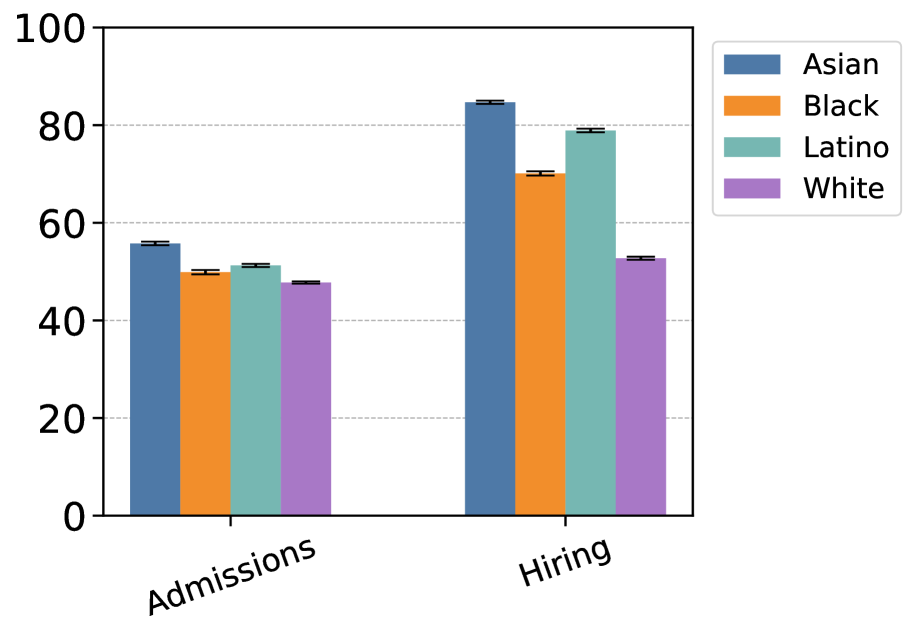
在大语言模型(LLM)应用于高风险决策时,理解和缓解偏差至关重要。本文引入了“招生”和“招聘”任务,这些任务使用假设的申请人资料,其中一个人的种族可以从他们的名字推断出来,作为种族偏见的简化测试平台。研究表明,Gemma 2B Instruct 和 LLaMA 3.2 3B Instruct 表现出强烈的偏见。Gemma 录取白人申请者的比例比黑人高 26%,而 LLaMA 雇佣亚裔申请者的比例比白人高 60%。研究表明,这些偏见难以通过提示工程来消除:多种提示策略都未能促进公平性。相反,使用分布式对齐搜索,可以在模型激活中识别“种族子空间”,并干预这些子空间以消除模型决策中的偏差。在子空间内对所有种族的表征进行平均,可将 Gemma 的偏差降低 37-57%。最后,研究检验了 Gemma 种族子空间的一般性,发现泛化证据有限,改变提示格式会影响种族表征。这项工作表明,机械方法可能为提高 LLM 的公平性提供有希望的途径,但通用的种族表征仍然难以实现。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在高风险决策场景中存在的种族偏见问题。现有方法,如提示工程,在消除这些偏见方面效果不佳,无法保证公平性。这些偏见可能导致对不同种族群体的不公平待遇。
核心思路:论文的核心思路是通过识别模型内部的“种族子空间”,并对这些子空间进行干预来消除偏差。具体来说,通过平均不同种族在这些子空间中的表征,从而减少模型对种族信息的依赖,实现更公平的决策。这种方法旨在从模型内部机制上消除偏见,而不是依赖外部的提示调整。
技术框架:论文的技术框架主要包括以下几个步骤:1)构建包含种族信息的申请人数据集(招生和招聘场景);2)使用LLM(Gemma和LLaMA)进行决策模拟;3)通过分布式对齐搜索识别模型激活中的“种族子空间”;4)对种族子空间进行干预,即平均不同种族的表征;5)评估干预后的模型在公平性指标上的表现。
关键创新:论文的关键创新在于提出了通过识别和干预模型内部的“种族子空间”来消除偏差的方法。与传统的提示工程方法相比,该方法更深入地挖掘了模型内部的偏见来源,并试图从机制上消除这些偏见。此外,使用分布式对齐搜索来寻找种族子空间也是一个创新点。
关键设计:论文的关键设计包括:1)使用分布式对齐搜索算法来识别种族子空间,该算法能够有效地找到模型激活中与种族信息相关的部分;2)通过平均不同种族的表征来干预种族子空间,这种方法简单有效,能够减少模型对种族信息的依赖;3)构建了招生和招聘两个高风险决策场景,并设计了相应的评估指标来衡量模型的公平性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,通过干预种族子空间,可以将Gemma模型的种族偏见降低37-57%。然而,研究也发现,种族子空间的泛化能力有限,改变提示格式会影响种族表征。这表明,虽然该方法在特定场景下有效,但要实现通用的种族偏差消除仍然面临挑战。
🎯 应用场景
该研究成果可应用于各种高风险决策场景,例如贷款审批、刑事判决、教育录取等,以减少算法偏见,提高决策的公平性和公正性。未来的研究可以探索更通用的种族表征方法,并将其应用于更广泛的模型和数据集。
📄 摘要(原文)
Understanding and mitigating biases is critical for the adoption of large language models (LLMs) in high-stakes decision-making. We introduce Admissions and Hiring, decision tasks with hypothetical applicant profiles where a person's race can be inferred from their name, as simplified test beds for racial bias. We show that Gemma 2B Instruct and LLaMA 3.2 3B Instruct exhibit strong biases. Gemma grants admission to 26% more White than Black applicants, and LLaMA hires 60% more Asian than White applicants. We demonstrate that these biases are resistant to prompt engineering: multiple prompting strategies all fail to promote fairness. In contrast, using distributed alignment search, we can identify "race subspaces" within model activations and intervene on them to debias model decisions. Averaging the representation across all races within the subspaces reduces Gemma's bias by 37-57%. Finally, we examine the generalizability of Gemma's race subspaces, and find limited evidence for generalization, where changing the prompt format can affect the race representation. Our work suggests mechanistic approaches may provide a promising venue for improving the fairness of LLMs, but a universal race representation remains elusive.