SmolVLM: Redefining small and efficient multimodal models
作者: Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaibhav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tunstall, Leandro von Werra, Thomas Wolf
分类: cs.AI, cs.CV
发布日期: 2025-04-07
💡 一句话要点
提出SmolVLM以解决小型多模态模型的资源效率问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型多模态模型 资源效率 视觉语言模型 图像理解 视频理解 模型优化 数据整理 推理效率
📋 核心要点
- 现有大型视觉语言模型对计算资源的需求高,限制了其在移动设备上的应用。
- SmolVLM通过优化架构配置和标记策略,设计出资源高效的小型多模态模型。
- SmolVLM-256M在推理时使用不到1GB GPU内存,性能超越了300倍于其规模的模型。
📝 摘要(中文)
大型视觉语言模型(VLMs)虽然性能卓越,但其对计算资源的高需求限制了在移动和边缘设备上的应用。小型VLMs通常模仿大型模型的设计选择,导致GPU内存使用效率低下。本文提出SmolVLM系列紧凑型多模态模型,专门针对资源高效推理进行设计。通过系统探索架构配置、标记策略和数据整理,识别出关键设计选择,显著提升图像和视频任务的性能,同时保持较小的内存占用。SmolVLM-256M模型在推理时使用不到1GB的GPU内存,超越了300倍于其规模的Idefics-80B模型。我们的研究强调了战略性架构优化、有效的标记策略和精心整理的训练数据在多模态性能提升中的重要性。
🔬 方法详解
问题定义:本论文旨在解决大型视觉语言模型在移动和边缘设备上应用受限的问题,现有小型模型往往在设计上模仿大型模型,导致资源使用效率低下。
核心思路:提出SmolVLM系列模型,通过系统探索架构、标记策略和数据整理,优化资源使用,提升多模态任务性能。
技术框架:SmolVLM的整体架构包括多个模块,主要包括图像和视频输入的处理模块、特征提取模块、以及多模态融合模块,旨在实现高效的推理过程。
关键创新:SmolVLM的核心创新在于其紧凑的模型设计和高效的标记策略,使得模型在保持较小内存占用的同时,仍能在多模态任务中表现出色。
关键设计:在模型设计中,采用了精简的网络结构和优化的损失函数,确保在低计算开销下实现高性能,同时在数据整理上进行了精细化处理,以提升训练效果。
🖼️ 关键图片


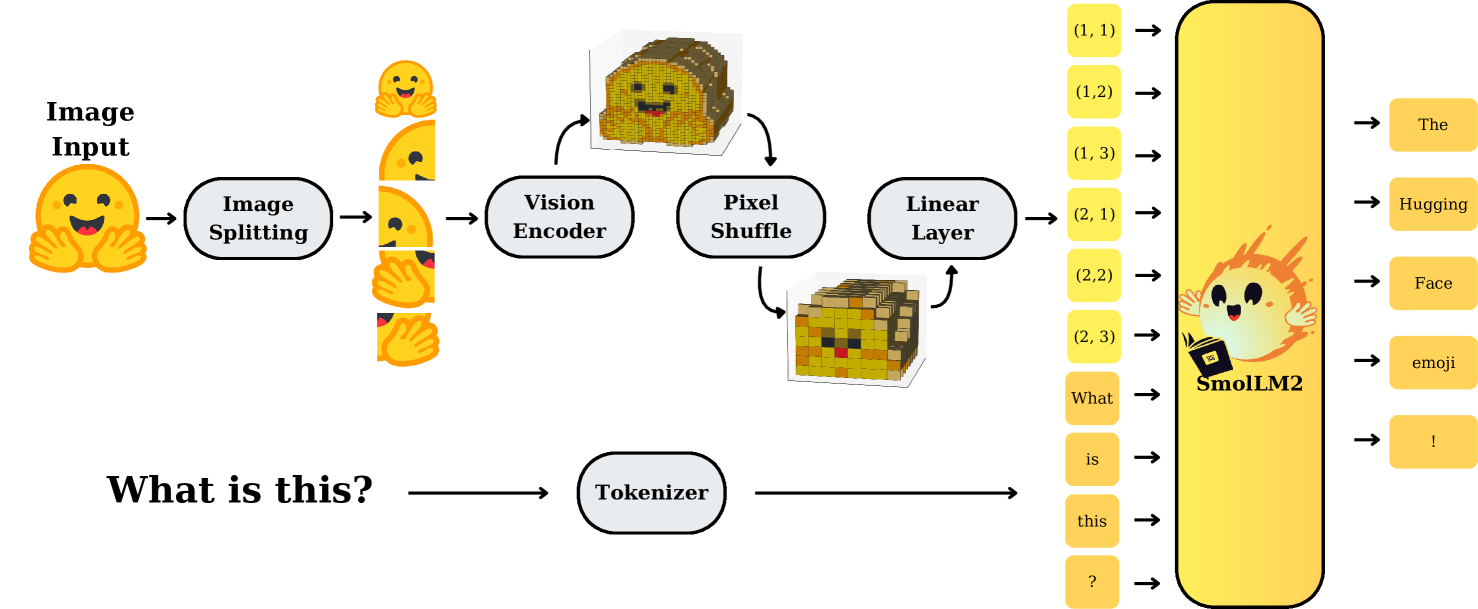
📊 实验亮点
SmolVLM-256M模型在推理时仅使用不到1GB的GPU内存,性能超越了300倍于其规模的Idefics-80B模型。此外,SmolVLM的最大模型在2.2B参数下,性能与现有最先进的VLMs相当,但GPU内存消耗仅为其一半,显示出显著的资源效率提升。
🎯 应用场景
SmolVLM的研究成果具有广泛的应用潜力,特别是在移动设备和边缘计算环境中,能够实现高效的图像和视频理解。这将推动智能手机、无人机、智能监控等领域的多模态应用发展,提升用户体验和系统性能。
📄 摘要(原文)
Large Vision-Language Models (VLMs) deliver exceptional performance but require significant computational resources, limiting their deployment on mobile and edge devices. Smaller VLMs typically mirror design choices of larger models, such as extensive image tokenization, leading to inefficient GPU memory usage and constrained practicality for on-device applications. We introduce SmolVLM, a series of compact multimodal models specifically engineered for resource-efficient inference. We systematically explore architectural configurations, tokenization strategies, and data curation optimized for low computational overhead. Through this, we identify key design choices that yield substantial performance gains on image and video tasks with minimal memory footprints. Our smallest model, SmolVLM-256M, uses less than 1GB GPU memory during inference and outperforms the 300-times larger Idefics-80B model, despite an 18-month development gap. Our largest model, at 2.2B parameters, rivals state-of-the-art VLMs consuming twice the GPU memory. SmolVLM models extend beyond static images, demonstrating robust video comprehension capabilities. Our results emphasize that strategic architectural optimizations, aggressive yet efficient tokenization, and carefully curated training data significantly enhance multimodal performance, facilitating practical, energy-efficient deployments at significantly smaller scales.