Utility-Focused LLM Annotation for Retrieval and Retrieval-Augmented Generation
作者: Hengran Zhang, Minghao Tang, Keping Bi, Jiafeng Guo, Shihao Liu, Daiting Shi, Dawei Yin, Xueqi Cheng
分类: cs.IR, cs.AI, cs.CL
发布日期: 2025-04-07 (更新: 2025-10-09)
备注: Accepted by the EMNLP25 main conference
💡 一句话要点
利用大语言模型标注文档效用,提升检索和RAG系统性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 文档标注 检索增强生成 信息检索 效用评估
📋 核心要点
- 现有检索和RAG系统依赖大量人工标注,成本高昂,且检索相关性与生成效用之间存在差距。
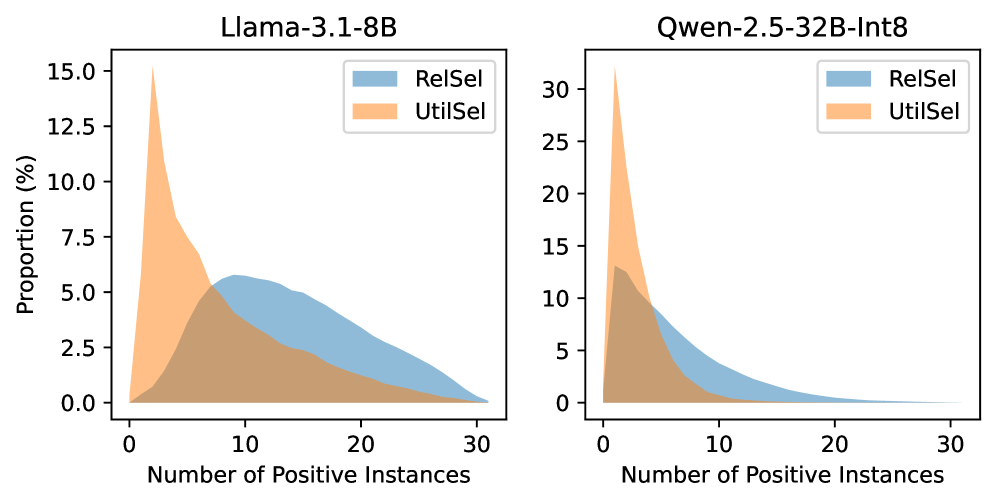
- 利用LLM标注文档效用,弥合检索相关性与生成效用之间的差距,并设计新的损失函数以有效利用多个正样本。
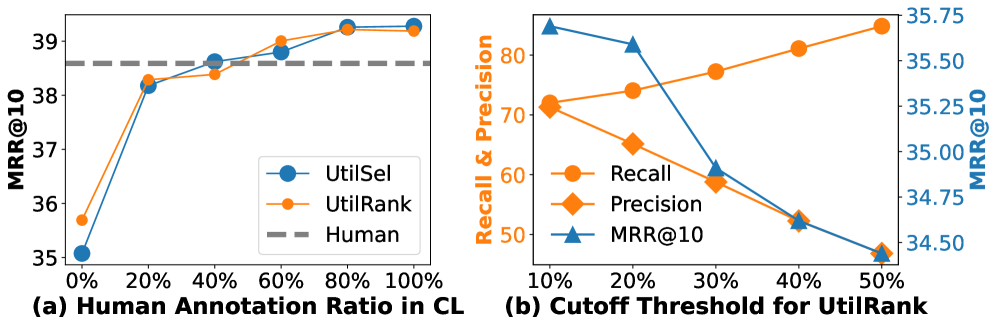
- 实验表明,LLM标注提升了领域外检索性能和RAG效果,结合少量人工标注即可达到媲美全人工标注的性能。
📝 摘要(中文)
本文探索了使用大型语言模型(LLMs)标注文档效用,用于训练检索和检索增强生成(RAG)系统,旨在减少对昂贵的人工标注的依赖。我们通过使用LLMs标注文档效用,解决了检索相关性和生成效用之间的差距。为了有效利用每个查询的多个正样本,我们引入了一种新的损失函数,该函数最大化它们的总边际似然。我们使用Qwen-2.5-32B模型在MS MARCO数据集上标注效用,并在MS MARCO和BEIR上进行检索实验,以及在MS MARCO QA、NQ和HotpotQA上进行RAG实验。结果表明,与仅在人工标注或下游QA指标上训练的模型相比,LLM生成的标注增强了领域外检索性能并改善了RAG结果。此外,将LLM标注与仅20%的人工标签相结合,可以达到与使用完整人工标注相当的性能。我们的研究为利用LLM标注初始化新语料库上的QA系统提供了一种全面的方法。
🔬 方法详解
问题定义:现有检索和RAG系统训练依赖大量人工标注,成本高昂。同时,检索模型通常优化检索相关性,而RAG系统更关注生成答案的效用,两者存在gap。如何降低人工标注成本,并提升RAG系统的生成效用,是本文要解决的问题。
核心思路:利用大语言模型(LLMs)进行文档效用标注,代替或减少人工标注。通过LLM的强大理解和生成能力,标注文档对于生成最终答案的效用,而非仅仅是与查询的相关性。同时,设计新的损失函数,充分利用每个查询对应的多个正样本,提升模型训练效率。
技术框架:整体流程包括:1) 使用LLM对文档进行效用标注;2) 使用标注数据训练检索模型;3) 将训练好的检索模型应用于检索任务和RAG任务。主要模块包括:LLM标注模块、检索模型训练模块、检索和RAG评估模块。
关键创新:1) 利用LLM进行文档效用标注,弥合了检索相关性和生成效用之间的差距。2) 提出了新的损失函数,最大化多个正样本的总边际似然,更有效地利用了标注数据。
关键设计:1) 使用Qwen-2.5-32B模型进行文档效用标注。2) 设计了新的损失函数,具体形式未知,但目标是最大化多个正样本的总边际似然。3) 实验中使用了MS MARCO、BEIR等数据集进行检索任务评估,以及MS MARCO QA、NQ、HotpotQA等数据集进行RAG任务评估。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用LLM生成的标注可以显著提升领域外检索性能和RAG效果。例如,与仅使用人工标注训练的模型相比,使用LLM标注的模型在BEIR数据集上取得了显著提升。更重要的是,结合LLM标注和仅20%的人工标注,即可达到与使用全部人工标注相当的性能,大幅降低了标注成本。
🎯 应用场景
该研究成果可广泛应用于问答系统、信息检索、智能客服等领域。通过利用LLM标注文档效用,可以降低人工标注成本,快速构建高质量的检索和RAG系统,尤其适用于在新语料库上初始化QA系统。未来,该方法有望进一步提升RAG系统的生成质量和用户体验。
📄 摘要(原文)
This paper explores the use of large language models (LLMs) for annotating document utility in training retrieval and retrieval-augmented generation (RAG) systems, aiming to reduce dependence on costly human annotations. We address the gap between retrieval relevance and generative utility by employing LLMs to annotate document utility. To effectively utilize multiple positive samples per query, we introduce a novel loss that maximizes their summed marginal likelihood. Using the Qwen-2.5-32B model, we annotate utility on the MS MARCO dataset and conduct retrieval experiments on MS MARCO and BEIR, as well as RAG experiments on MS MARCO QA, NQ, and HotpotQA. Our results show that LLM-generated annotations enhance out-of-domain retrieval performance and improve RAG outcomes compared to models trained solely on human annotations or downstream QA metrics. Furthermore, combining LLM annotations with just 20% of human labels achieves performance comparable to using full human annotations. Our study offers a comprehensive approach to utilizing LLM annotations for initializing QA systems on new corpora.