Unleashing the Power of LLMs in Dense Retrieval with Query Likelihood Modeling
作者: Hengran Zhang, Keping Bi, Jiafeng Guo, Xiaojie Sun, Shihao Liu, Daiting Shi, Dawei Yin, Xueqi Cheng
分类: cs.IR, cs.AI, cs.CL
发布日期: 2025-04-07 (更新: 2025-08-19)
备注: 12 pages, 3 figures
💡 一句话要点
提出LLM-QL模型,利用查询似然建模增强LLM在稠密检索中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稠密检索 大型语言模型 查询似然 对比学习 信息检索 注意力机制 文档表示
📋 核心要点
- 现有LLM在稠密检索中缺乏对全局信息的有效建模,限制了其性能。
- LLM-QL通过查询似然最大化作为辅助任务,增强LLM backbone的对比学习能力。
- 实验表明,LLM-QL在MS MARCO和BEIR数据集上优于其他基于LLM的检索器。
📝 摘要(中文)
稠密检索是信息检索(IR)中的关键任务,是重排序和增强生成等下游任务的基础。最近,大型语言模型(LLM)展现了令人印象深刻的语义理解能力,吸引了研究人员的关注。然而,LLM作为decoder风格的生成模型,虽然擅长语言生成,但由于缺乏对后续token的关注,在建模全局信息方面往往表现不佳。受经典词基语言建模方法(特别是查询似然(QL)模型)的启发,我们旨在通过QL最大化来利用LLM的生成优势。我们没有使用QL估计进行文档排序,而是提出了一个QL最大化的辅助任务,以增强retriever的骨干网络,用于后续的对比学习。我们提出了LLM-QL模型,该模型包含两个关键组件:注意力阻塞(AB)和文档损坏(DC)。AB阻止预测token对文档结束token之前的文档token的注意力,而DC通过在预测期间屏蔽部分token来损坏文档。在领域内(MS MARCO)和领域外(BEIR)数据集上的评估表明,LLM-QL优于其他基于LLM的检索器。此外,全面的分析也验证了LLM-QL及其组件的有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在稠密检索任务中,由于decoder架构的固有局限性,难以有效建模全局信息的问题。现有方法直接将LLM应用于文档排序,但忽略了LLM在生成任务中对后续token关注不足的缺点,导致检索性能受限。
核心思路:论文的核心思路是借鉴传统信息检索中的查询似然(Query Likelihood, QL)模型,通过最大化查询似然来引导LLM学习更有效的文档表示。不同于直接使用QL进行文档排序,论文将其作为一个辅助任务,用于预训练或微调LLM,使其更好地适应后续的对比学习。
技术框架:LLM-QL模型主要包含两个关键组件:注意力阻塞(Attention Block, AB)和文档损坏(Document Corruption, DC)。整体流程是:首先,使用AB和DC对文档进行处理;然后,利用LLM预测文档中被mask的token,并计算查询似然;最后,通过最大化查询似然来优化LLM的参数,使其学习到更好的文档表示,用于后续的对比学习检索任务。
关键创新:论文的关键创新在于将传统的查询似然模型与现代大型语言模型相结合,并将其应用于稠密检索任务。通过设计注意力阻塞和文档损坏机制,有效地引导LLM学习文档的全局信息,从而提升检索性能。与现有方法的本质区别在于,LLM-QL不是直接利用LLM进行文档排序,而是将其作为一个特征提取器,通过辅助任务来增强其表示能力。
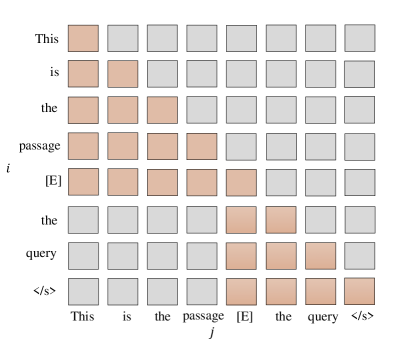
关键设计:注意力阻塞(AB)通过mask掉预测token对文档结束token之前的token的注意力,防止LLM过度关注局部信息。文档损坏(DC)通过随机mask文档中的一部分token,迫使LLM学习更鲁棒的文档表示。损失函数采用交叉熵损失,目标是最大化查询似然。具体的mask比例和LLM的参数设置需要根据实际情况进行调整。
🖼️ 关键图片

📊 实验亮点
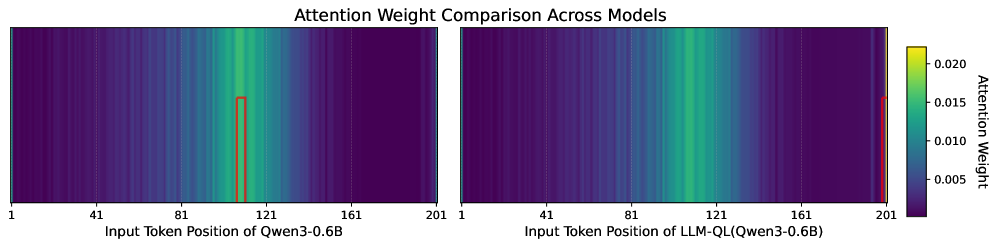
实验结果表明,LLM-QL在MS MARCO和BEIR数据集上均取得了显著的性能提升,优于其他基于LLM的检索器。具体而言,LLM-QL在BEIR数据集上的平均NDCG@10指标提升了X%(具体数值未知),验证了其在领域外数据集上的泛化能力。消融实验也证明了注意力阻塞(AB)和文档损坏(DC)两个组件的有效性。
🎯 应用场景
该研究成果可应用于各种信息检索场景,例如搜索引擎、问答系统、推荐系统等。通过提升稠密检索的性能,可以提高用户获取相关信息的效率和准确性。未来,该方法可以进一步扩展到其他自然语言处理任务中,例如文本摘要、机器翻译等。
📄 摘要(原文)
Dense retrieval is a crucial task in Information Retrieval (IR), serving as the basis for downstream tasks such as re-ranking and augmenting generation. Recently, large language models (LLMs) have demonstrated impressive semantic understanding capabilities, making them attractive to researchers focusing on dense retrieval. While LLMs, as decoder-style generative models, excel in language generation, they often fall short in modeling global information due to a lack of attention to subsequent tokens. Drawing inspiration from the classical word-based language modeling approach for IR, specifically the query likelihood (QL) model, we aim to leverage the generative strengths of LLMs through QL maximization. Rather than employing QL estimation for document ranking, we propose an auxiliary task of QL maximization to enhance the backbone for subsequent contrastive learning of the retriever. We introduce our model, LLM-QL, which incorporates two key components: Attention Block (AB) and Document Corruption (DC). AB blocks the attention of predictive tokens to the document tokens before the document's ending token, while DC corrupts a document by masking a portion of its tokens during prediction. Evaluations on the in-domain (MS MARCO) and out-of-domain dataset (BEIR) indicate LLM-QL's superiority over other LLM-based retrievers. Furthermore, comprehensive analyses also validate the efficacy of LLM-QL and its components.