Resource-Efficient Beam Prediction in mmWave Communications with Multimodal Realistic Simulation Framework
作者: Yu Min Park, Yan Kyaw Tun, Eui-Nam Huh, Walid Saad, Choong Seon Hong
分类: cs.NI, cs.AI, cs.LG
发布日期: 2025-04-07 (更新: 2025-12-01)
备注: 13 pages, 9 figures, Submitted to IEEE Transactions on Mobile Computing on Dec. 01, 2025
💡 一句话要点
提出基于跨模态关系知识蒸馏的毫米波通信波束预测方法,提升资源效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 毫米波通信 波束预测 多模态学习 知识蒸馏 跨模态关系 资源效率 自动驾驶
📋 核心要点
- 传统毫米波通信波束预测方法难以适应快速变化的环境,且依赖大量导频信号或波束扫描,效率较低。
- 论文提出一种基于跨模态关系知识蒸馏(CRKD)的波束预测框架,将多模态知识迁移到仅雷达模型,降低计算成本。
- 实验结果表明,CRKD使仅雷达模型达到教师模型94.62%的性能,且参数量仅为教师网络的10%。
📝 摘要(中文)
波束成形是毫米波通信中的关键技术,它通过优化方向性和强度来改善信号传输。然而,传统的信道估计方法,如导频信号或波束扫描,通常无法适应快速变化的通信环境。为了解决这一限制,多模态感知辅助的波束预测受到了广泛关注,它利用来自LiDAR、雷达、GPS和RGB图像等设备的各种感知数据来预测用户位置或网络状况。尽管其潜力巨大,但多模态感知辅助波束预测的采用受到高计算复杂性、高成本和有限数据集的阻碍。因此,本文提出了一种新颖的资源高效学习框架用于波束预测,该框架利用专门为波束预测任务定制的跨模态关系知识蒸馏(CRKD)算法,将知识从多模态网络转移到仅雷达的学生模型,从而以降低的计算成本实现高精度。为了实现具有真实数据的多模态学习,开发了一种新颖的多模态仿真框架,该框架将来自自动驾驶模拟器CARLA生成的传感器数据与基于MATLAB的毫米波信道建模相结合,并反映了真实世界的条件。所提出的CRKD通过提取不同特征空间中的关系信息来实现其目标,从而在不依赖昂贵传感器数据的情况下提高波束预测性能。仿真结果表明,CRKD有效地提取了多模态知识,使仅雷达模型能够达到教师模型94.62%的性能。特别是,这是在仅使用教师网络10%的参数的情况下实现的,从而显著降低了计算复杂性和对多模态传感器数据的依赖。
🔬 方法详解
问题定义:论文旨在解决毫米波通信中波束预测的资源效率问题。现有方法,如基于导频信号或波束扫描的信道估计,无法有效应对快速变化的环境,且计算复杂度高。多模态感知辅助的波束预测虽然有潜力,但依赖多种传感器数据,成本高昂,且计算量大。
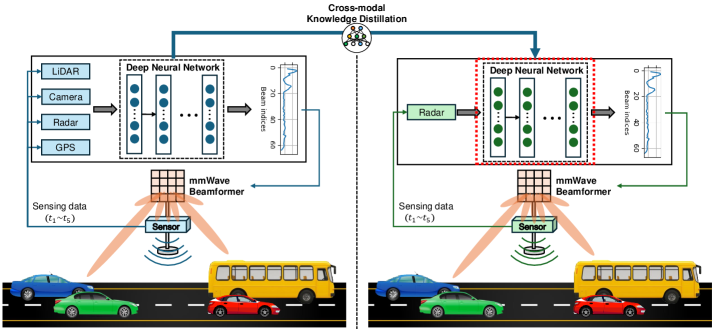
核心思路:论文的核心思路是利用知识蒸馏,将多模态教师网络学习到的知识迁移到仅使用雷达数据的学生网络。通过跨模态关系知识蒸馏(CRKD),学生网络可以学习到不同模态之间的关系,从而在仅使用雷达数据的情况下,也能实现接近多模态模型的性能。这样既降低了对多种传感器的依赖,又减少了计算复杂度。
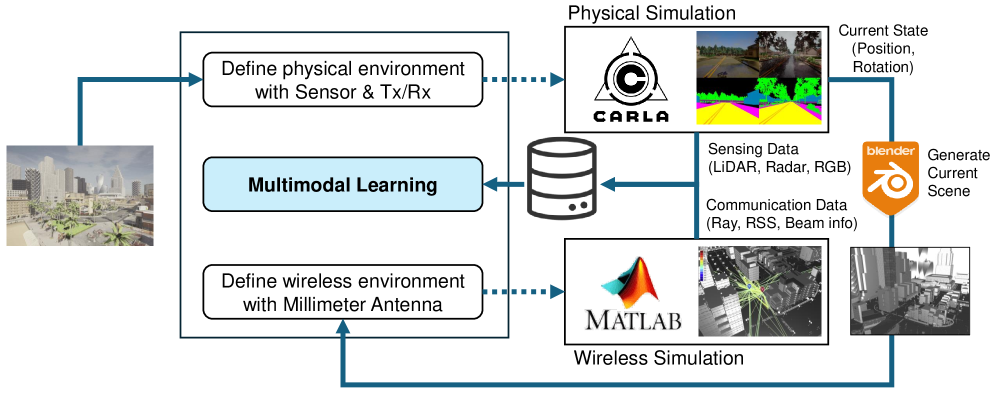
技术框架:整体框架包含两个主要部分:多模态教师网络和仅雷达学生网络。教师网络利用来自CARLA仿真环境的LiDAR、雷达、GPS和RGB图像等多模态数据进行训练。学生网络仅使用雷达数据进行训练,并通过CRKD算法从教师网络学习知识。CRKD算法在特征层面提取不同模态之间的关系,并将这些关系作为知识传递给学生网络。
关键创新:论文的关键创新在于提出的跨模态关系知识蒸馏(CRKD)算法。传统的知识蒸馏方法通常直接传递特征或预测结果,而CRKD关注不同模态特征之间的关系,例如不同传感器数据之间的互补信息。通过学习这些关系,学生网络可以更好地理解雷达数据,并提高波束预测的准确性。
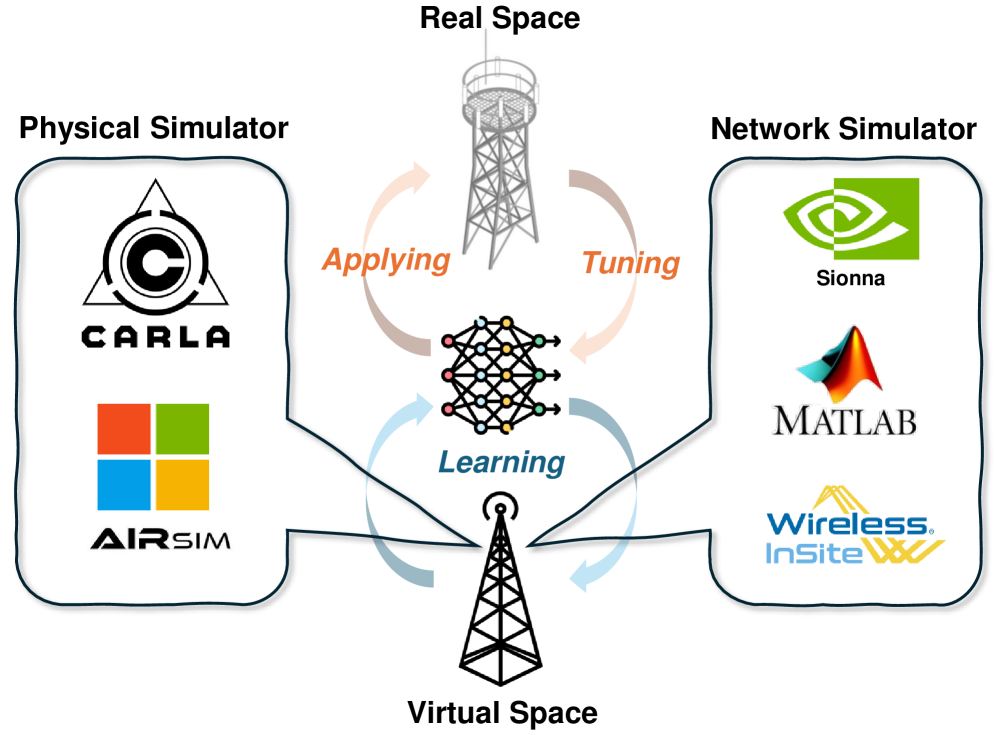
关键设计:CRKD算法的关键设计包括:1) 使用关系损失函数来衡量教师网络和学生网络之间关系表示的差异;2) 设计特定的网络结构,以便提取不同模态特征之间的关系;3) 通过调整蒸馏温度等参数来控制知识迁移的强度。此外,论文还构建了一个多模态仿真环境,将CARLA自动驾驶模拟器与MATLAB毫米波信道建模相结合,生成更真实的数据。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的CRKD算法能够有效地将多模态知识迁移到仅雷达模型,使仅雷达模型达到教师模型94.62%的性能。更重要的是,学生网络的参数量仅为教师网络的10%,显著降低了计算复杂度。这表明CRKD算法在资源效率方面具有显著优势。
🎯 应用场景
该研究成果可应用于自动驾驶、智能交通、无线通信等领域。通过降低对多模态传感器的依赖和计算复杂度,可以实现更高效、更经济的毫米波通信波束预测,提升通信质量和用户体验。未来,该方法有望推广到其他资源受限的场景,例如物联网设备和边缘计算。
📄 摘要(原文)
Beamforming is a key technology in millimeter-wave (mmWave) communications that improves signal transmission by optimizing directionality and intensity. However, conventional channel estimation methods, such as pilot signals or beam sweeping, often fail to adapt to rapidly changing communication environments. To address this limitation, multimodal sensing-aided beam prediction has gained significant attention, using various sensing data from devices such as LiDAR, radar, GPS, and RGB images to predict user locations or network conditions. Despite its promising potential, the adoption of multimodal sensing-aided beam prediction is hindered by high computational complexity, high costs, and limited datasets. Thus, in this paper, a novel resource-efficient learning framework is introduced for beam prediction, which leverages a custom-designed cross-modal relational knowledge distillation (CRKD) algorithm specifically tailored for beam prediction tasks, to transfer knowledge from a multimodal network to a radar-only student model, achieving high accuracy with reduced computational cost. To enable multimodal learning with realistic data, a novel multimodal simulation framework is developed while integrating sensor data generated from the autonomous driving simulator CARLA with MATLAB-based mmWave channel modeling, and reflecting real-world conditions. The proposed CRKD achieves its objective by distilling relational information across different feature spaces, which enhances beam prediction performance without relying on expensive sensor data. Simulation results demonstrate that CRKD efficiently distills multimodal knowledge, allowing a radar-only model to achieve $94.62%$ of the teacher performance. In particular, this is achieved with just $10%$ of the teacher network's parameters, thereby significantly reducing computational complexity and dependence on multimodal sensor data.