Algorithm Discovery With LLMs: Evolutionary Search Meets Reinforcement Learning
作者: Anja Surina, Amin Mansouri, Lars Quaedvlieg, Amal Seddas, Maryna Viazovska, Emmanuel Abbe, Caglar Gulcehre
分类: cs.AI, cs.LG, cs.NE
发布日期: 2025-04-07 (更新: 2025-08-04)
备注: 34 pages
💡 一句话要点
提出基于强化学习微调的LLM进化搜索算法,加速组合优化算法发现
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 算法发现 大型语言模型 进化搜索 强化学习 组合优化
📋 核心要点
- 传统算法发现依赖大量人工经验,现有基于LLM的进化搜索方法未能充分利用进化过程中的反馈信号。
- 论文提出利用强化学习持续优化LLM搜索算子,将进化搜索作为探索策略,RL作为优化手段,提升算法发现效率。
- 实验表明,该方法在组合优化任务中能够加速发现更优算法,验证了RL增强进化策略在算法设计中的有效性。
📝 摘要(中文)
本文提出了一种新颖的算法发现方法,该方法通过强化学习(RL)微调来增强基于大型语言模型(LLM)的进化搜索。现有方法通常将LLM视为静态生成器,忽略了从进化探索中获得的信号来更新模型。本文利用进化搜索作为探索策略来发现改进的算法,同时使用RL根据这些发现优化LLM策略。在组合优化任务上的实验表明,将RL与进化搜索相结合可以加速发现更优的算法,展示了RL增强的进化策略在算法设计中的潜力。
🔬 方法详解
问题定义:论文旨在解决复杂问题的算法自动发现问题,尤其关注组合优化领域。现有基于LLM的算法发现方法通常将LLM视为静态的算法生成器,忽略了在进化搜索过程中产生的反馈信息,导致搜索效率较低,难以发现更优的算法。
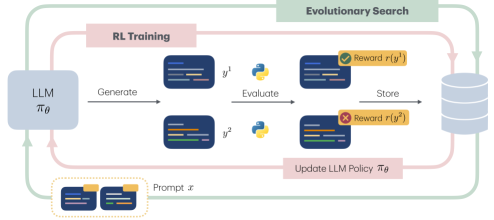
核心思路:论文的核心思路是利用强化学习(RL)来动态优化LLM,使其能够更好地利用进化搜索过程中产生的反馈信号。通过将进化搜索作为探索策略,RL负责根据进化结果调整LLM的策略,从而实现LLM的持续学习和优化。
技术框架:整体框架包含两个主要部分:进化搜索和强化学习微调。首先,使用LLM生成初始算法种群,并通过进化搜索(例如遗传算法)进行迭代优化。在每次迭代中,评估种群中算法的性能,并根据性能选择优秀的算法。然后,使用这些优秀算法作为RL的奖励信号,对LLM进行微调,使其能够生成更优秀的算法。这个过程不断循环,直到找到满足要求的算法。
关键创新:最重要的创新点在于将强化学习与进化搜索相结合,动态优化LLM。与传统的静态LLM方法相比,该方法能够充分利用进化过程中的反馈信息,使LLM能够不断学习和改进,从而加速算法发现过程。
关键设计:论文中关键的设计包括:1) 如何定义RL的奖励函数,使其能够准确反映算法的性能;2) 如何选择合适的RL算法,例如Policy Gradient或Actor-Critic方法;3) 如何设计LLM的网络结构,使其能够有效地生成和优化算法代码;4) 如何平衡进化搜索的探索和RL的利用,避免过早收敛到局部最优解。具体的参数设置、损失函数和网络结构等技术细节在论文中可能有所描述,但此处未知。
🖼️ 关键图片
📊 实验亮点
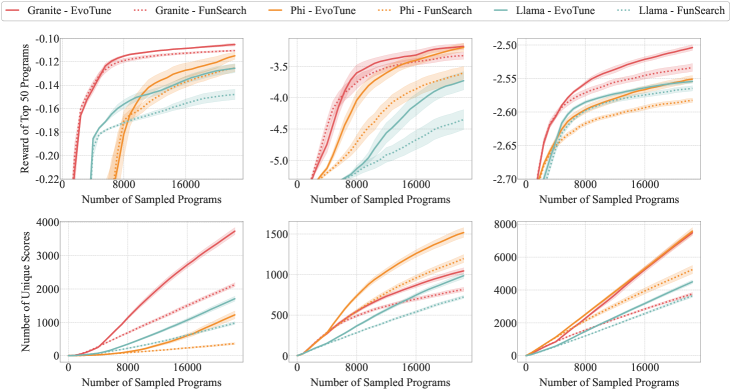
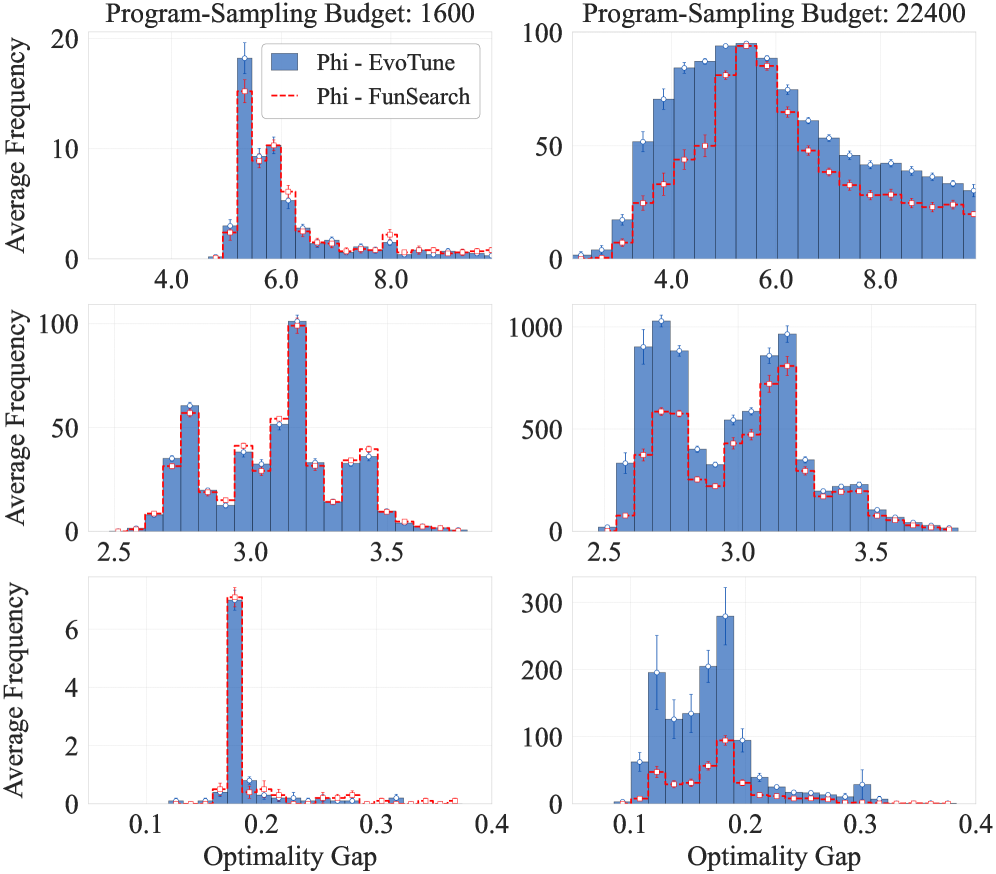
论文在组合优化任务上进行了实验,结果表明,与传统的进化搜索方法相比,该方法能够更快地发现更优的算法。具体的性能数据和提升幅度在论文中有所描述,但此处未知。实验结果验证了RL增强的进化策略在算法设计中的有效性。
🎯 应用场景
该研究成果可应用于各种需要算法设计的领域,例如组合优化、机器学习、运筹学等。通过自动发现高效算法,可以降低人工设计成本,提高问题解决效率,并可能发现人类难以设计的创新算法。未来,该方法有望应用于更广泛的科学和工程领域,推动相关领域的发展。
📄 摘要(原文)
Discovering efficient algorithms for solving complex problems has been an outstanding challenge in mathematics and computer science, requiring substantial human expertise over the years. Recent advancements in evolutionary search with large language models (LLMs) have shown promise in accelerating the discovery of algorithms across various domains, particularly in mathematics and optimization. However, existing approaches treat the LLM as a static generator, missing the opportunity to update the model with the signal obtained from evolutionary exploration. In this work, we propose to augment LLM-based evolutionary search by continuously refining the search operator - the LLM - through reinforcement learning (RL) fine-tuning. Our method leverages evolutionary search as an exploration strategy to discover improved algorithms, while RL optimizes the LLM policy based on these discoveries. Our experiments on combinatorial optimization tasks demonstrate that integrating RL with evolutionary search accelerates the discovery of superior algorithms, showcasing the potential of RL-enhanced evolutionary strategies for algorithm design.