Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use
作者: Anna Goldie, Azalia Mirhoseini, Hao Zhou, Irene Cai, Christopher D. Manning
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-04-07 (更新: 2025-04-28)
💡 一句话要点
提出Step-Wise RL,通过合成数据和多步强化学习提升语言模型在推理和工具使用上的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 多步推理 工具使用 合成数据 语言模型 子轨迹优化 逐步分解
📋 核心要点
- 现有强化学习方法在处理复杂推理和代理任务时,通常采用单步优化,无法有效处理多步交互。
- SWiRL通过迭代生成多步推理和工具使用数据,并采用逐步分解和子轨迹优化,实现多步强化学习。
- 实验表明,SWiRL在多个任务上显著优于基线方法,并展现出跨任务的泛化能力,提升零样本性能。
📝 摘要(中文)
强化学习已被证明可以提高大型语言模型的性能。然而,传统的RLHF或RLAIF方法将问题视为单步过程。随着焦点转移到更复杂的推理和代理任务上,语言模型必须在生成解决方案之前采取多个步骤的文本生成、推理和环境交互。我们提出了一种针对多步优化场景的合成数据生成和强化学习方法,称为Step-Wise Reinforcement Learning (SWiRL)。该方法迭代地生成多步推理和工具使用数据,然后从中学习。它采用一种简单的逐步分解方法,将每个多步轨迹分解为对应于原始模型每个动作的多个子轨迹。然后,它对这些子轨迹应用合成数据过滤和强化学习优化。我们在多个多步工具使用、问题回答和数学推理任务上评估了SWiRL。实验表明,SWiRL在GSM8K、HotPotQA、CofCA、MuSiQue和BeerQA上的相对准确率分别比基线方法高出21.5%、12.3%、14.8%、11.1%和15.3%。令人兴奋的是,该方法表现出跨任务的泛化能力:例如,仅在HotPotQA(文本问答)上训练就能将GSM8K(数学数据集)的零样本性能提高16.9%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂推理和工具使用任务中,由于需要多步交互而导致的性能瓶颈。现有方法,如RLHF和RLAIF,主要关注单步优化,无法有效处理需要多步推理和决策的任务。这些任务通常需要模型进行多次文本生成、推理和环境交互才能得到最终答案,单步优化难以捕捉这种长程依赖关系。
核心思路:SWiRL的核心思路是将多步任务分解为多个子轨迹,每个子轨迹对应于模型的一个动作。通过对这些子轨迹进行合成数据生成、过滤和强化学习优化,可以更有效地学习多步推理和决策策略。这种逐步分解的方法允许模型在每个步骤都进行优化,从而更好地处理长程依赖关系。
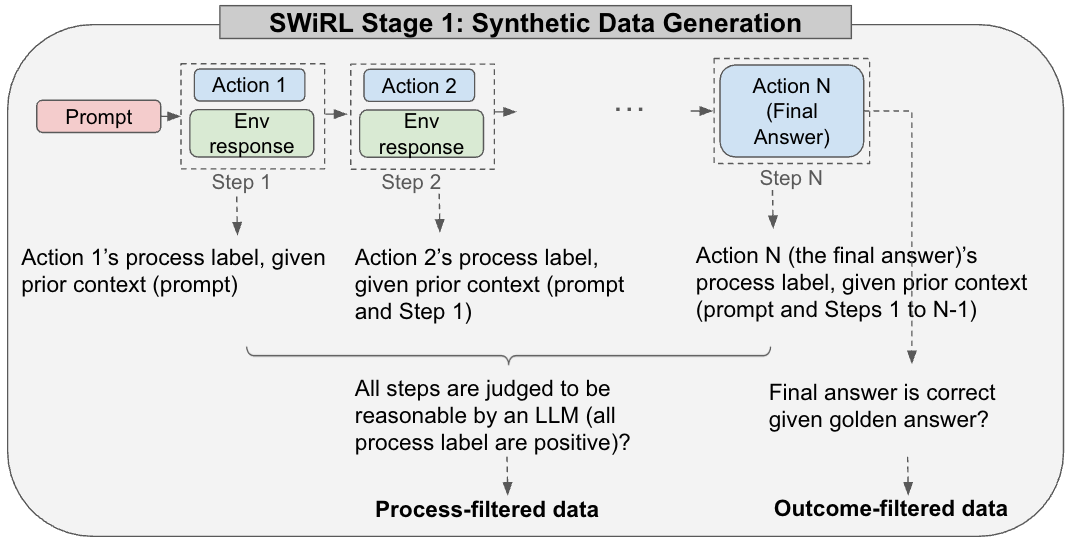
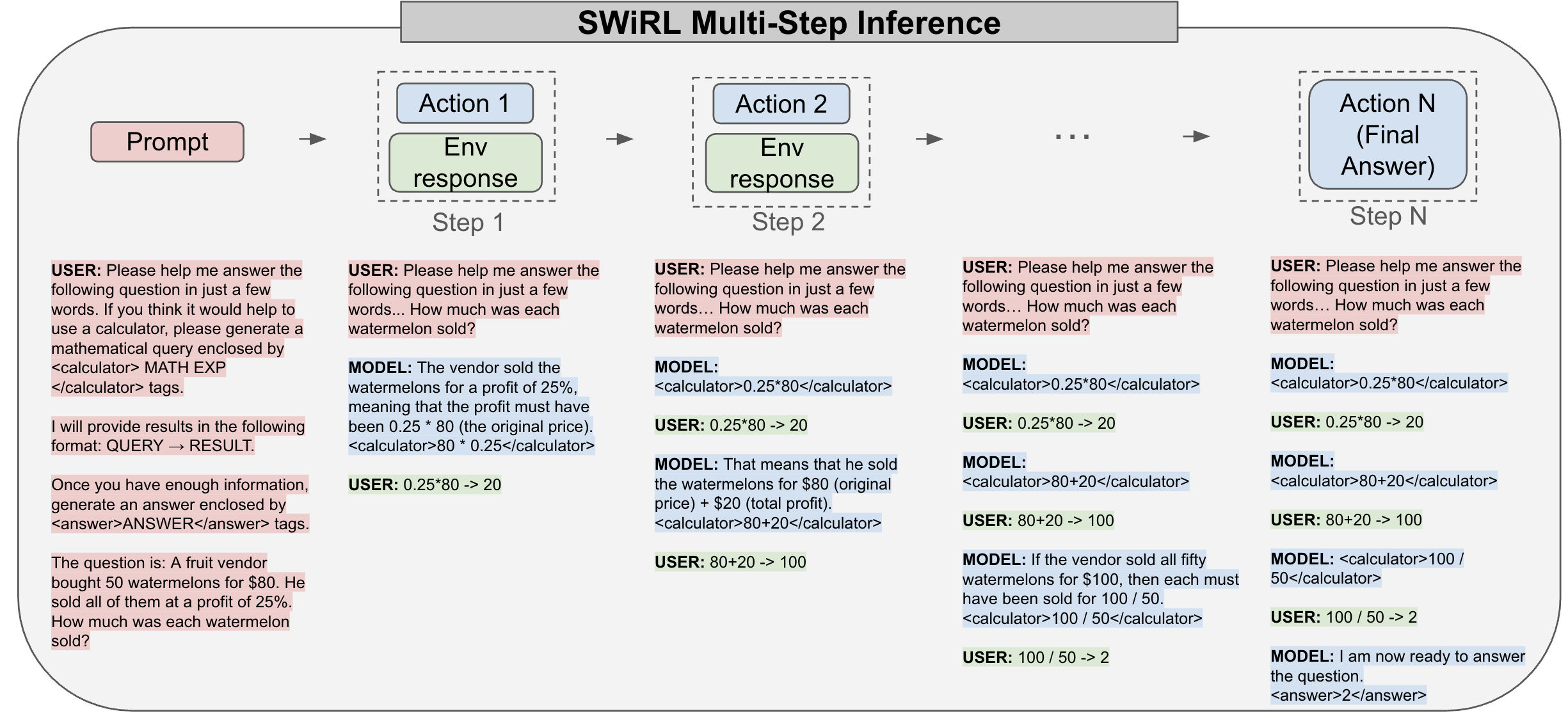
技术框架:SWiRL的整体框架包括以下几个主要阶段:1) 合成数据生成:使用语言模型生成多步推理和工具使用数据。2) 逐步分解:将每个多步轨迹分解为多个子轨迹,每个子轨迹对应于模型的一个动作。3) 合成数据过滤:对生成的合成数据进行过滤,去除质量较差的数据。4) 强化学习优化:使用强化学习算法对子轨迹进行优化,提高模型的性能。
关键创新:SWiRL最重要的技术创新点在于其逐步分解和子轨迹优化的方法。与传统的单步强化学习方法不同,SWiRL能够更有效地处理多步推理和决策任务。此外,SWiRL还采用了合成数据过滤技术,可以提高训练数据的质量,从而进一步提升模型的性能。
关键设计:SWiRL的关键设计包括:1) 子轨迹的定义:每个子轨迹对应于模型的一个动作,包括输入、动作和奖励。2) 奖励函数的设计:奖励函数用于评估每个子轨迹的质量,可以根据任务的不同进行设计。3) 强化学习算法的选择:可以使用各种强化学习算法对子轨迹进行优化,例如PPO。4) 合成数据过滤策略:可以使用各种过滤策略去除质量较差的合成数据,例如基于置信度的过滤。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SWiRL在GSM8K、HotPotQA、CofCA、MuSiQue和BeerQA等多个数据集上显著优于基线方法,相对准确率分别提升了21.5%、12.3%、14.8%、11.1%和15.3%。更重要的是,SWiRL展现出强大的泛化能力,例如,仅在HotPotQA上训练就能将GSM8K的零样本性能提高16.9%。这些结果表明,SWiRL是一种有效且通用的多步强化学习方法。
🎯 应用场景
SWiRL具有广泛的应用前景,可用于提升语言模型在各种需要复杂推理和工具使用的任务中的性能,例如智能助手、自动代码生成、科学研究等。通过学习多步交互策略,模型可以更好地理解用户意图,并生成更准确、更有效的解决方案。该方法还可以应用于机器人控制等领域,使机器人能够执行更复杂的任务。
📄 摘要(原文)
Reinforcement learning has been shown to improve the performance of large language models. However, traditional approaches like RLHF or RLAIF treat the problem as single-step. As focus shifts toward more complex reasoning and agentic tasks, language models must take multiple steps of text generation, reasoning and environment interaction before generating a solution. We propose a synthetic data generation and RL methodology targeting multi-step optimization scenarios. This approach, called Step-Wise Reinforcement Learning (SWiRL), iteratively generates multi-step reasoning and tool use data, and then learns from that data. It employs a simple step-wise decomposition that breaks each multi-step trajectory into multiple sub-trajectories corresponding to each action by the original model. It then applies synthetic data filtering and RL optimization on these sub-trajectories. We evaluated SWiRL on a number of multi-step tool use, question answering, and mathematical reasoning tasks. Our experiments show that SWiRL outperforms baseline approaches by 21.5%, 12.3%, 14.8%, 11.1%, and 15.3% in relative accuracy on GSM8K, HotPotQA, CofCA, MuSiQue, and BeerQA, respectively. Excitingly, the approach exhibits generalization across tasks: for example, training only on HotPotQA (text question-answering) improves zero-shot performance on GSM8K (a math dataset) by a relative 16.9%.