How Accurately Do Large Language Models Understand Code?
作者: Sabaat Haroon, Ahmad Faraz Khan, Ahmad Humayun, Waris Gill, Abdul Haddi Amjad, Ali R. Butt, Mohammad Taha Khan, Muhammad Ali Gulzar
分类: cs.SE, cs.AI, cs.LG
发布日期: 2025-04-06 (更新: 2025-04-09)
备注: This paper is currently Under Review. It consists of 11 pages, 12 Figures, and 5 Tables
💡 一句话要点
通过缺陷定位评估,揭示大语言模型对代码理解的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 代码理解 故障定位 变异测试 语义保留代码突变
📋 核心要点
- 现有LLM在代码修复和测试等任务中应用广泛,但缺乏对其代码理解能力的有效评估方法,现有基准测试侧重于代码生成而非理解。
- 该论文提出了一种基于变异测试的评估方法,通过注入故障并观察LLM的故障定位能力,来衡量其对代码的理解深度。
- 实验结果表明,LLM在面对语义保留的代码突变时,故障定位能力显著下降,表明其代码理解依赖于浅层的词法和句法特征。
📝 摘要(中文)
大型语言模型(LLM)越来越多地应用于代码修复和测试等后开发任务。这些任务成功的关键因素是模型对代码的深刻理解。然而,LLM对代码的真正理解程度在很大程度上仍未得到评估。量化代码理解具有挑战性,因为它本质上是抽象的,并且缺乏标准化的指标。以前,这是通过开发者调查来评估的,但这对于评估LLM是不可行的。现有的LLM基准主要侧重于代码生成,这与代码理解根本不同。此外,固定的基准会很快过时,因为它们会成为训练数据的一部分。本文首次对LLM理解代码的能力进行了大规模的实证研究。受变异测试的启发,我们使用LLM的故障查找能力作为其深刻代码理解的代理。这种方法基于这样的洞察力:能够识别细微功能差异的模型必须很好地理解代码。我们在真实世界的程序中注入故障,并要求LLM定位它们,确保规范足以进行故障定位。接下来,我们对有缺陷的程序应用语义保留代码突变(SPM),并测试LLM是否仍然可以定位故障,从而验证它们对代码理解的信心。我们评估了来自670个Java和637个Python程序的600,010个调试任务中的九个流行的LLM。我们发现,当应用SPM时,LLM在78%的有缺陷的程序中失去了调试相同错误的能力,这表明对代码的理解很浅,并且依赖于与语义无关的特征。我们还发现,LLM对程序早期代码的理解优于后期代码。这表明,由于为自然语言设计的标记化忽略了代码语义,LLM的代码理解仍然与词汇和句法特征相关。
🔬 方法详解
问题定义:现有的大语言模型在代码理解方面存在不足,尤其是在面对语义不变但表达形式不同的代码时,其性能会显著下降。现有的评估方法主要集中在代码生成任务上,无法有效衡量模型对代码语义的真正理解程度。因此,如何准确评估LLM对代码的理解能力,并揭示其局限性,是本文要解决的核心问题。
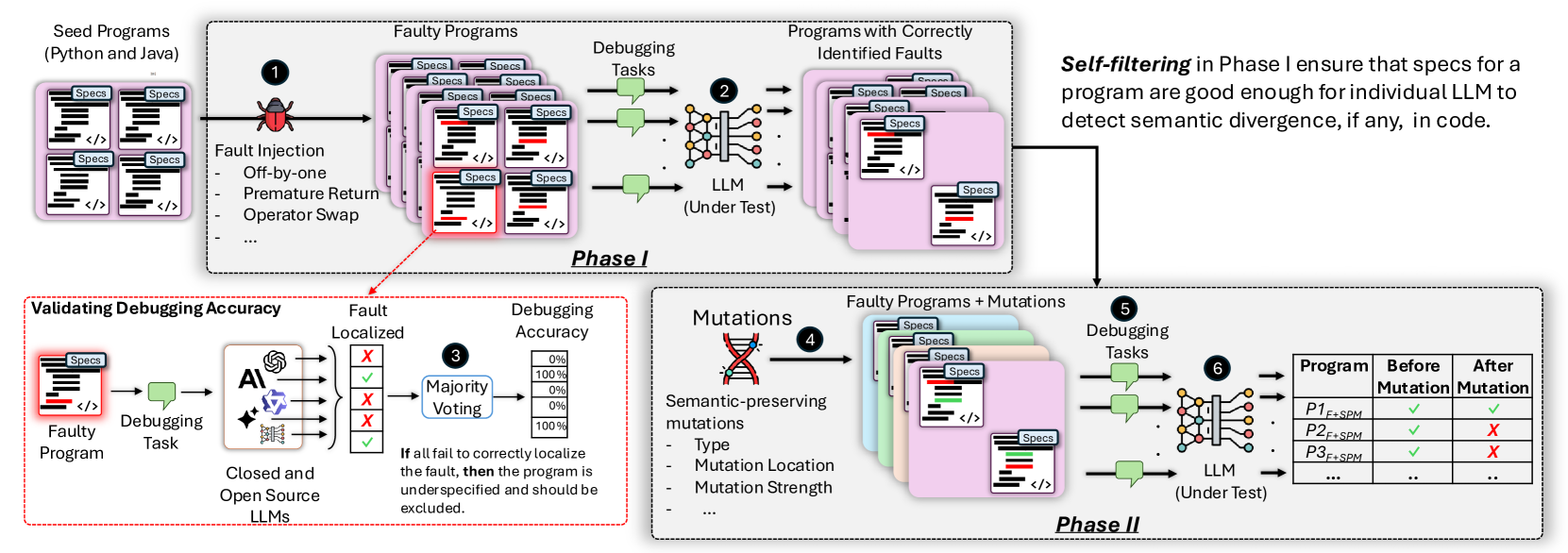
核心思路:本文的核心思路是将LLM的故障定位能力作为其代码理解能力的代理指标。如果一个LLM能够准确地定位代码中的细微错误,那么它必然对代码的语义有较深的理解。通过在代码中注入错误,并观察LLM在不同代码变体下的故障定位表现,可以推断其代码理解的深度和广度。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 从真实世界的Java和Python程序中选取代码片段;2) 在这些代码片段中注入错误,生成有缺陷的程序;3) 对有缺陷的程序应用语义保留的代码突变(SPM),生成不同的代码变体;4) 使用LLM尝试定位原始错误和变体中的错误;5) 分析LLM在不同情况下的故障定位成功率,评估其代码理解能力。
关键创新:该研究的关键创新在于使用故障定位作为评估LLM代码理解能力的代理指标。与传统的代码生成评估方法不同,这种方法更直接地考察了LLM对代码语义的理解程度。此外,通过引入语义保留的代码突变,可以进一步验证LLM是否真正理解了代码的语义,还是仅仅依赖于表面的词法和句法特征。
关键设计:在实验设计方面,该研究选择了大量的Java和Python程序,并使用了多种语义保留的代码突变技术,以确保评估结果的可靠性和泛化性。同时,研究人员还仔细控制了实验环境,确保LLM能够获得足够的上下文信息来进行故障定位。此外,研究还分析了LLM在程序不同位置的代码理解能力,发现LLM对程序早期代码的理解优于后期代码,这为进一步改进LLM的代码理解能力提供了重要的线索。
🖼️ 关键图片


📊 实验亮点
实验结果表明,当应用语义保留的代码突变(SPM)时,LLM在78%的有缺陷的程序中失去了调试相同错误的能力,这表明LLM对代码的理解很浅,并且依赖于与语义无关的特征。此外,研究还发现LLM对程序早期代码的理解优于后期代码,这为改进LLM的代码理解能力提供了重要的线索。
🎯 应用场景
该研究成果可应用于改进LLM的代码理解能力,提升其在代码修复、代码测试和代码优化等任务中的性能。此外,该评估方法也可用于比较不同LLM的代码理解能力,为选择合适的LLM用于特定代码相关任务提供参考。未来的研究可以探索如何利用该评估方法来指导LLM的训练,使其更好地理解代码的语义。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used in post-development tasks such as code repair and testing. A key factor in these tasks' success is the model's deep understanding of code. However, the extent to which LLMs truly understand code remains largely unevaluated. Quantifying code comprehension is challenging due to its abstract nature and the lack of a standardized metric. Previously, this was assessed through developer surveys, which are not feasible for evaluating LLMs. Existing LLM benchmarks focus primarily on code generation, fundamentally different from code comprehension. Additionally, fixed benchmarks quickly become obsolete as they become part of the training data. This paper presents the first large-scale empirical investigation into LLMs' ability to understand code. Inspired by mutation testing, we use an LLM's fault-finding ability as a proxy for its deep code understanding. This approach is based on the insight that a model capable of identifying subtle functional discrepancies must understand the code well. We inject faults in real-world programs and ask the LLM to localize them, ensuring the specifications suffice for fault localization. Next, we apply semantic-preserving code mutations (SPMs) to the faulty programs and test whether the LLMs still locate the faults, verifying their confidence in code understanding. We evaluate nine popular LLMs on 600,010 debugging tasks from 670 Java and 637 Python programs. We find that LLMs lose the ability to debug the same bug in 78% of faulty programs when SPMs are applied, indicating a shallow understanding of code and reliance on features irrelevant to semantics. We also find that LLMs understand code earlier in the program better than later. This suggests that LLMs' code comprehension remains tied to lexical and syntactic features due to tokenization designed for natural languages, which overlooks code semantics.