Solving Sokoban using Hierarchical Reinforcement Learning with Landmarks
作者: Sergey Pastukhov
分类: cs.AI
发布日期: 2025-04-06
备注: 13 pages, 6 figures
💡 一句话要点
提出基于地标分层强化学习方法,解决Sokoban游戏难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 强化学习 Sokoban 递归规划 子目标学习
📋 核心要点
- 现有强化学习方法在解决Sokoban等复杂组合游戏中,难以进行有效的长期规划和探索。
- 论文提出一种多层分层强化学习框架,通过递归分解目标为子目标,实现自上而下的规划。
- 实验表明,该方法无需任何领域知识,即可在Sokoban游戏中生成长动作序列,展现出良好的可扩展性。
📝 摘要(中文)
本文提出了一种新颖的分层强化学习(HRL)框架,该框架通过学习到的子目标执行自上而下的递归规划,并成功应用于复杂的组合谜题游戏Sokoban。我们的方法构建了一个六层策略层次结构,其中每个更高层级的策略都为其下层生成子目标。所有子目标和策略都是从头端到端学习的,没有任何领域知识。我们的结果表明,智能体可以通过一次高层调用生成长的动作序列。虽然先前的工作已经探索了2-3层层次结构和基于子目标的规划启发式方法,但我们证明了深度递归目标分解可以纯粹从学习中涌现出来,并且这种层次结构可以有效地扩展到困难的谜题领域。
🔬 方法详解
问题定义:论文旨在解决Sokoban游戏中智能体长期规划的问题。Sokoban是一个组合难题游戏,需要智能体推动箱子到指定位置。现有强化学习方法难以处理其巨大的状态空间和稀疏奖励,导致难以进行有效的探索和规划。
核心思路:论文的核心思路是利用分层强化学习(HRL),将复杂任务分解为多个层级的子任务,并通过学习子目标来实现长期规划。高层策略负责生成子目标,低层策略负责实现这些子目标,从而实现自上而下的递归规划。
技术框架:该框架构建了一个六层策略层次结构。最高层策略负责生成最抽象的子目标,例如“将箱子推到房间的角落”。每一层策略都为其下一层生成更具体的子目标,直到最底层策略直接执行动作。整个框架采用端到端的方式进行训练,无需任何人工设计的启发式规则。
关键创新:最重要的技术创新点在于深度递归目标分解。与以往的HRL方法不同,该方法能够学习到多达六层的策略层次结构,从而实现更深层次的抽象和更有效的长期规划。这种深度递归目标分解完全是从数据中学习得到的,无需任何领域知识。
关键设计:每一层策略都使用深度神经网络进行建模。损失函数的设计旨在鼓励高层策略生成有用的子目标,并鼓励低层策略有效地实现这些子目标。具体而言,使用了目标条件强化学习,其中每个策略都以当前状态和目标状态作为输入。此外,还使用了经验回放和目标重标记等技术来提高学习效率。
🖼️ 关键图片

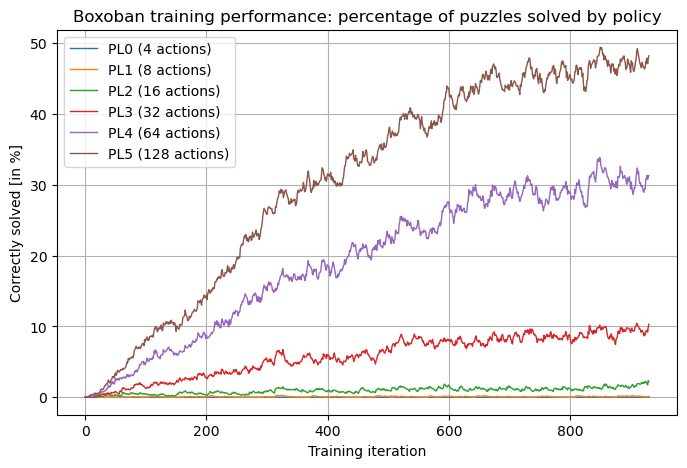
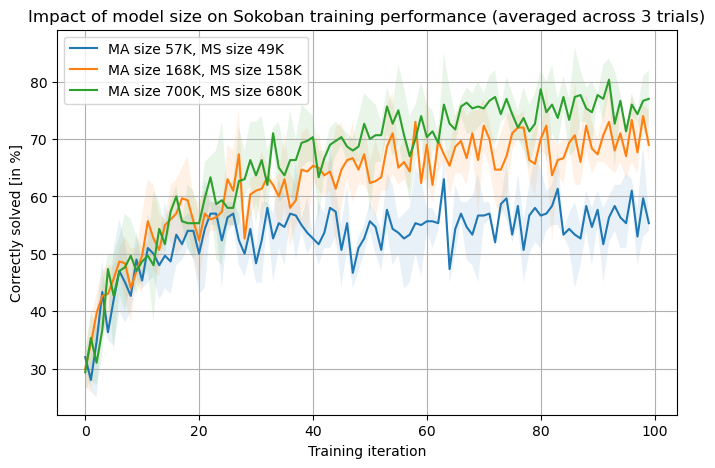
📊 实验亮点
实验结果表明,该方法在Sokoban游戏中取得了显著的成果。智能体能够从头开始学习,并在没有人工干预的情况下解决复杂的Sokoban关卡。与传统的强化学习方法相比,该方法能够生成更长的动作序列,并取得更高的成功率。这表明深度递归目标分解可以有效地提高强化学习的性能。
🎯 应用场景
该研究提出的分层强化学习框架具有广泛的应用前景,可以应用于机器人导航、任务规划、游戏AI等领域。通过学习多层抽象的子目标,智能体可以更好地理解复杂环境,并进行有效的长期规划。该方法在自动化、智能制造等领域具有潜在的应用价值。
📄 摘要(原文)
We introduce a novel hierarchical reinforcement learning (HRL) framework that performs top-down recursive planning via learned subgoals, successfully applied to the complex combinatorial puzzle game Sokoban. Our approach constructs a six-level policy hierarchy, where each higher-level policy generates subgoals for the level below. All subgoals and policies are learned end-to-end from scratch, without any domain knowledge. Our results show that the agent can generate long action sequences from a single high-level call. While prior work has explored 2-3 level hierarchies and subgoal-based planning heuristics, we demonstrate that deep recursive goal decomposition can emerge purely from learning, and that such hierarchies can scale effectively to hard puzzle domains.