Towards a Multimodal Document-grounded Conversational AI System for Education
作者: Karan Taneja, Anjali Singh, Ashok K. Goel
分类: cs.HC, cs.AI, cs.CV
发布日期: 2025-04-04
备注: 15 pages, 4 figures, AIED 2025
💡 一句话要点
提出MuDoC:一个面向教育的多模态文档对话AI系统,提升学习者参与度和信任度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 对话AI 教育应用 GPT-4o 文档溯源 学习参与度 信任度
📋 核心要点
- 现有教育对话AI系统主要依赖文本交互,忽略了多媒体学习中图文结合的优势。
- MuDoC系统利用GPT-4o,结合文档文本和图像生成多模态回复,并支持溯源验证。
- 实验表明,多模态信息和可验证性提升了学习者参与度和信任度,但对问题解决能力影响不显著。
📝 摘要(中文)
本文提出了一种基于GPT-4o的多模态文档对话AI系统MuDoC,用于教育领域。该系统利用文档中的文本和图像生成包含文本和图像的回复,并提供溯源功能以验证AI生成内容的可靠性。通过与纯文本系统的对比实验,研究发现多模态信息和内容可验证性能够增强学习者的参与度和对AI系统的信任感,但在问题解决能力方面未观察到显著影响。研究结果基于认知和学习科学理论进行了解释,并为未来多模态对话AI系统在教育中的发展方向提供了建议。
🔬 方法详解
问题定义:现有教育领域的对话AI系统主要依赖于文本交互,未能充分利用多媒体学习中图文结合的优势。这限制了学习体验,并且缺乏对AI生成内容的可信度验证机制,可能导致学习者对系统产生不信任感。
核心思路:MuDoC的核心思路是构建一个能够理解和生成多模态内容(文本和图像)的对话AI系统,并提供溯源功能,让学习者能够验证AI生成内容的来源,从而增强学习体验和信任感。
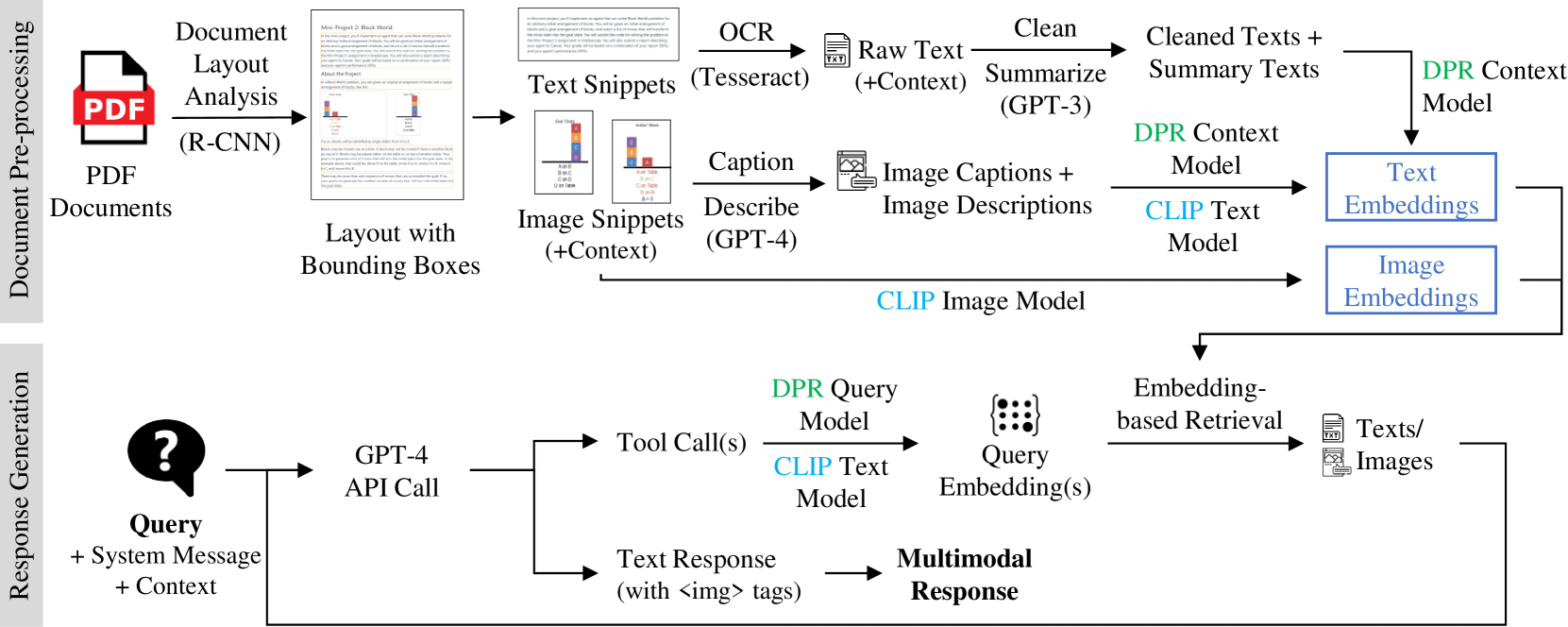
技术框架:MuDoC系统基于GPT-4o构建,其整体架构包含以下几个主要模块:1) 文档解析模块:负责解析输入文档,提取文本和图像信息。2) 多模态理解模块:利用GPT-4o理解用户问题和文档内容,融合文本和图像信息。3) 多模态生成模块:生成包含文本和图像的回复。4) 溯源模块:提供指向原始文档的链接,方便用户验证AI生成内容的来源。
关键创新:MuDoC的关键创新在于将多模态信息(文本和图像)融入到对话AI系统中,并提供溯源功能,增强了学习者的参与度和对系统的信任感。与传统的纯文本对话AI系统相比,MuDoC能够提供更丰富的学习体验和更高的可信度。
关键设计:MuDoC系统利用GPT-4o的多模态能力,无需额外的图像编码器或复杂的融合机制。溯源功能通过在生成回复时记录相关文档片段,并生成指向这些片段的链接来实现。具体的参数设置和损失函数等技术细节在论文中未详细描述,属于GPT-4o的内部实现。
🖼️ 关键图片


📊 实验亮点
对比实验表明,与纯文本系统相比,MuDoC显著提升了学习者的参与度和对AI系统的信任感。具体而言,学习者在使用MuDoC时,更愿意与系统互动,并且认为系统生成的内容更可靠。然而,在问题解决能力方面,两种系统之间没有观察到显著差异,这可能表明多模态信息和可验证性主要影响学习者的学习动机和信任度,而非直接提升认知能力。
🎯 应用场景
MuDoC可应用于在线教育平台、智能辅导系统、企业培训等领域,为学习者提供更具吸引力和可信度的学习体验。通过结合文本和图像,并提供溯源功能,MuDoC能够帮助学习者更好地理解知识,并建立对AI系统的信任感,从而提高学习效率和效果。未来,该系统有望成为个性化学习的重要工具。
📄 摘要(原文)
Multimedia learning using text and images has been shown to improve learning outcomes compared to text-only instruction. But conversational AI systems in education predominantly rely on text-based interactions while multimodal conversations for multimedia learning remain unexplored. Moreover, deploying conversational AI in learning contexts requires grounding in reliable sources and verifiability to create trust. We present MuDoC, a Multimodal Document-grounded Conversational AI system based on GPT-4o, that leverages both text and visuals from documents to generate responses interleaved with text and images. Its interface allows verification of AI generated content through seamless navigation to the source. We compare MuDoC to a text-only system to explore differences in learner engagement, trust in AI system, and their performance on problem-solving tasks. Our findings indicate that both visuals and verifiability of content enhance learner engagement and foster trust; however, no significant impact in performance was observed. We draw upon theories from cognitive and learning sciences to interpret the findings and derive implications, and outline future directions for the development of multimodal conversational AI systems in education.