DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
作者: Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, Pengfei Liu
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-04-04 (更新: 2025-04-17)
🔗 代码/项目: GITHUB
💡 一句话要点
DeepResearcher:通过强化学习在真实环境中扩展深度研究能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度研究 强化学习 大型语言模型 网络搜索 多代理系统
📋 核心要点
- 现有基于提示工程的方法性能脆弱,而基于RAG的方法无法捕捉真实世界交互的复杂性,限制了LLM在深度研究任务中的应用。
- DeepResearcher通过在真实网络环境中进行端到端强化学习,训练LLM代理自主导航、搜索和提取信息,解决了现有方法的局限性。
- 实验表明,DeepResearcher在开放域研究任务上显著优于基于提示工程和基于RAG的基线方法,提升高达28.9和7.2个点。
📝 摘要(中文)
配备网络搜索能力的大型语言模型(LLMs)在深度研究任务中展现出令人印象深刻的潜力。然而,目前的方法主要依赖于人工设计的提示(基于提示工程),性能脆弱,或者在受控的检索增强生成(RAG)环境中进行强化学习(基于RAG),无法捕捉真实世界交互的复杂性。本文介绍了DeepResearcher,这是第一个全面的框架,通过在具有真实网络搜索交互的真实世界环境中扩展强化学习(RL),对基于LLM的深度研究代理进行端到端训练。与基于RAG的方法假设所有必要信息都存在于固定语料库中不同,我们的方法训练代理以驾驭开放网络的嘈杂、非结构化和动态特性。我们实现了一个专门的多代理架构,其中浏览代理从各种网页结构中提取相关信息,并克服了重大的技术挑战。在开放域研究任务上的大量实验表明,DeepResearcher比基于提示工程的基线方法有了高达28.9个点的显著改进,比基于RAG的RL代理有了高达7.2个点的改进。我们的定性分析揭示了端到端RL训练中涌现的认知行为,包括制定计划、交叉验证来自多个来源的信息、进行自我反思以重定向研究,以及在无法找到明确答案时保持诚实的能力。我们的结果表明,在真实世界网络环境中的端到端训练不仅仅是一个实现细节,而是开发与真实世界应用相一致的强大研究能力的基本要求。我们在https://github.com/GAIR-NLP/DeepResearcher发布了DeepResearcher。
🔬 方法详解
问题定义:现有方法,如基于prompt engineering的方法依赖人工设计的prompt,泛化性差,容易出错。而基于RAG的方法依赖于预先构建的知识库,无法应对真实世界中动态变化的网络环境,信息获取能力受限。因此,需要一种方法能够让LLM自主地在真实网络环境中进行深度研究。
核心思路:DeepResearcher的核心思路是通过强化学习,让LLM代理在真实的网络环境中进行探索和学习,从而获得自主研究的能力。通过与真实世界的交互,代理可以学习如何有效地搜索、提取和验证信息,从而完成复杂的深度研究任务。
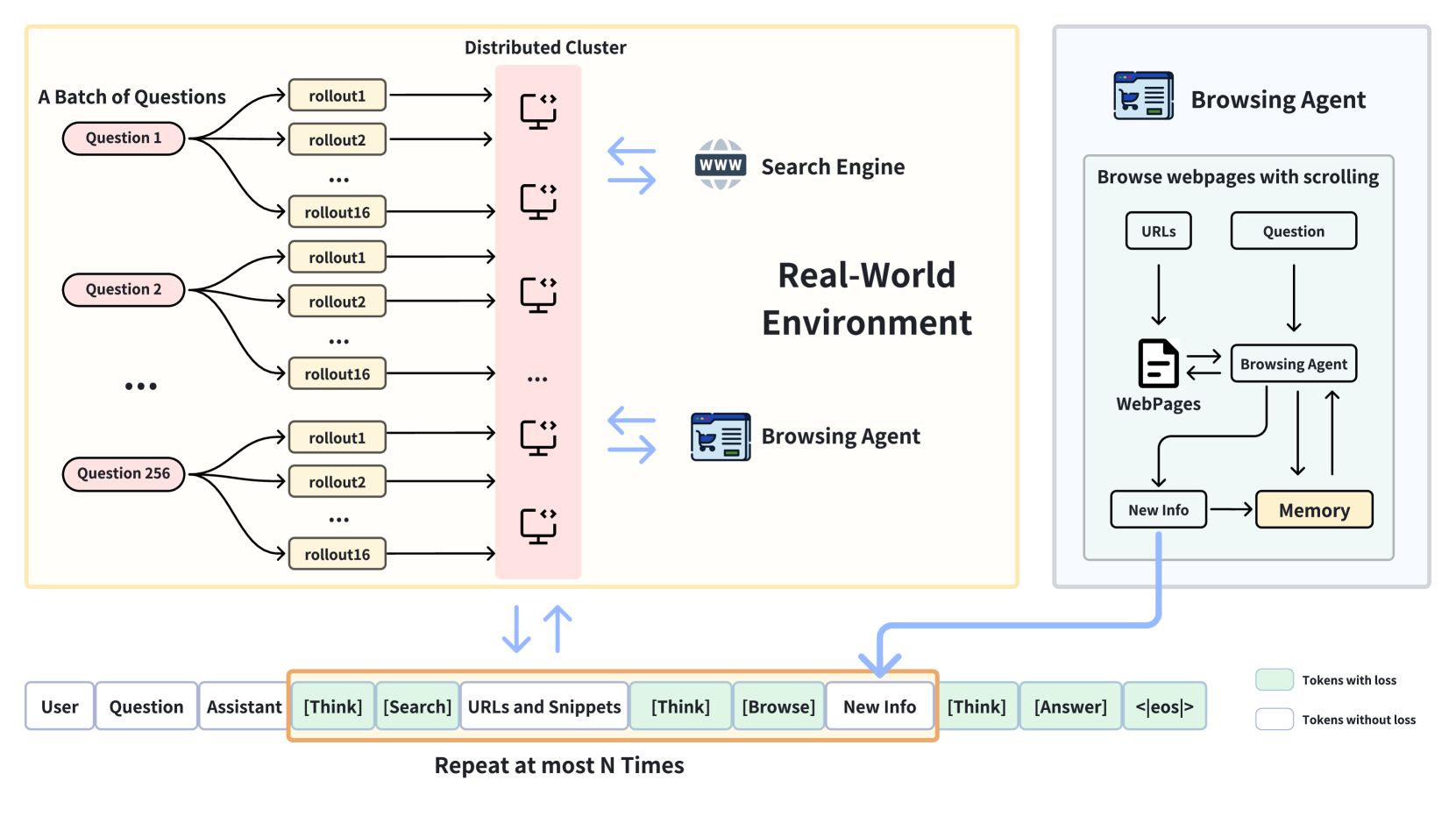
技术框架:DeepResearcher采用多代理架构,主要包含以下模块:1) 研究代理(Research Agent):负责制定研究计划、提出搜索查询、评估信息来源的可靠性等。2) 浏览代理(Browsing Agent):负责解析网页结构、提取相关信息。3) 环境(Environment):模拟真实的网络环境,提供搜索API和网页内容。研究代理和浏览代理通过强化学习进行训练,目标是最大化研究任务的完成度。
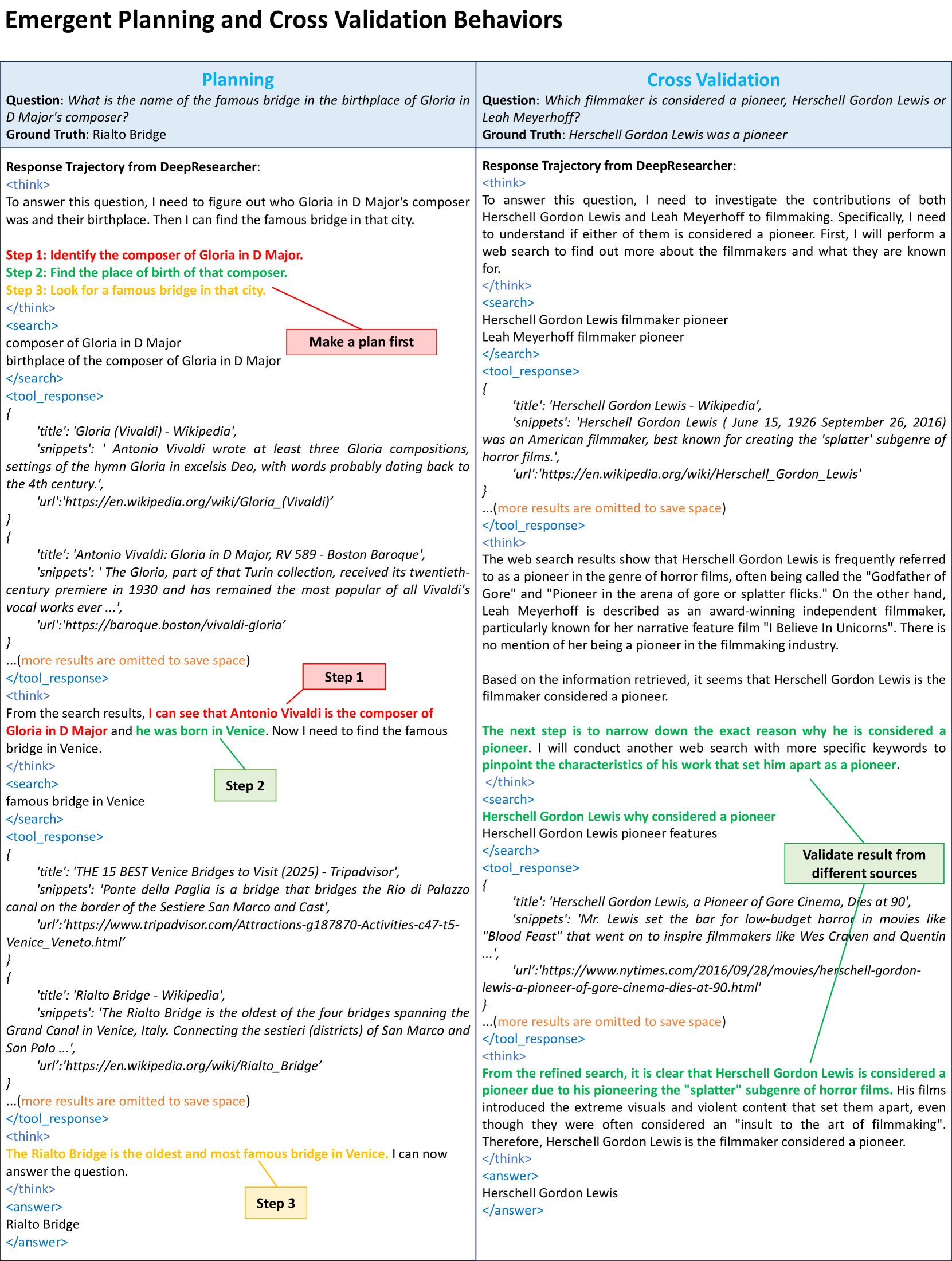
关键创新:DeepResearcher的关键创新在于:1) 端到端强化学习:直接在真实网络环境中训练LLM代理,避免了对人工设计的prompt或预构建知识库的依赖。2) 多代理架构:将研究任务分解为研究代理和浏览代理,提高了信息提取的效率和准确性。3) 涌现认知行为:通过强化学习,代理能够涌现出制定计划、交叉验证信息、自我反思等认知行为。
关键设计:DeepResearcher使用Proximal Policy Optimization (PPO)算法进行强化学习训练。奖励函数的设计至关重要,包括:1) 完成奖励:当代理成功完成研究任务时,给予正向奖励。2) 信息奖励:当代理提取到有用的信息时,给予正向奖励。3) 惩罚奖励:当代理进行无效搜索或访问不可靠的网站时,给予负向奖励。此外,还采用了attention机制来提高代理对关键信息的关注度。
🖼️ 关键图片

📊 实验亮点
DeepResearcher在开放域研究任务上取得了显著的性能提升。与基于提示工程的基线方法相比,DeepResearcher的性能提升高达28.9个点。与基于RAG的RL代理相比,DeepResearcher的性能提升高达7.2个点。此外,定性分析表明,DeepResearcher能够涌现出制定计划、交叉验证信息、自我反思等认知行为,表明其具有更强的自主研究能力。
🎯 应用场景
DeepResearcher可应用于多个领域,例如:科学研究、市场调研、新闻报道、法律咨询等。它可以帮助研究人员快速获取和分析大量信息,提高研究效率和质量。此外,DeepResearcher还可以作为智能助手,为用户提供个性化的信息服务和决策支持。未来,该技术有望推动知识发现和创新。
📄 摘要(原文)
Large Language Models (LLMs) equipped with web search capabilities have demonstrated impressive potential for deep research tasks. However, current approaches predominantly rely on either manually engineered prompts (prompt engineering-based) with brittle performance or reinforcement learning within controlled Retrieval-Augmented Generation (RAG) environments (RAG-based) that fail to capture the complexities of real-world interaction. In this paper, we introduce DeepResearcher, the first comprehensive framework for end-to-end training of LLM-based deep research agents through scaling reinforcement learning (RL) in real-world environments with authentic web search interactions. Unlike RAG-based approaches that assume all necessary information exists within a fixed corpus, our method trains agents to navigate the noisy, unstructured, and dynamic nature of the open web. We implement a specialized multi-agent architecture where browsing agents extract relevant information from various webpage structures and overcoming significant technical challenges. Extensive experiments on open-domain research tasks demonstrate that DeepResearcher achieves substantial improvements of up to 28.9 points over prompt engineering-based baselines and up to 7.2 points over RAG-based RL agents. Our qualitative analysis reveals emergent cognitive behaviors from end-to-end RL training, including the ability to formulate plans, cross-validate information from multiple sources, engage in self-reflection to redirect research, and maintain honesty when unable to find definitive answers. Our results highlight that end-to-end training in real-world web environments is not merely an implementation detail but a fundamental requirement for developing robust research capabilities aligned with real-world applications. We release DeepResearcher at https://github.com/GAIR-NLP/DeepResearcher.