Robust Reinforcement Learning from Human Feedback for Large Language Models Fine-Tuning
作者: Kai Ye, Hongyi Zhou, Jin Zhu, Francesco Quinzan, Chengchun Shi
分类: stat.ML, cs.AI, cs.LG
发布日期: 2025-04-03 (更新: 2025-11-17)
💡 一句话要点
提出一种鲁棒的基于人类反馈的强化学习方法,用于提升大语言模型微调效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 人类反馈 大型语言模型 微调 鲁棒性
📋 核心要点
- 现有RLHF算法依赖于对人类偏好的简化假设,导致奖励模型与真实人类判断存在偏差。
- 该论文提出一种鲁棒算法,通过降低奖励和策略估计器的方差,来提升模型在奖励模型错误指定下的性能。
- 实验结果表明,该算法在LLM基准测试中优于现有方法,并在Anthropic数据集上取得了显著提升。
📝 摘要(中文)
基于人类反馈的强化学习(RLHF)已成为将大型语言模型(LLM)的输出与人类偏好对齐的关键技术。为了学习奖励函数,大多数现有的RLHF算法使用Bradley-Terry模型,该模型依赖于对人类偏好的假设,而这些假设可能无法反映真实世界判断的复杂性和可变性。在本文中,我们提出了一种鲁棒的算法,以增强现有方法在此类奖励模型错误指定下的性能。理论上,我们的算法降低了奖励和策略估计器的方差,从而改善了遗憾界。在LLM基准数据集上的经验评估表明,所提出的算法始终优于现有方法,在Anthropic Helpful and Harmless数据集上,有77-81%的响应优于基线。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)方法,特别是使用Bradley-Terry模型的算法,在学习奖励函数时,依赖于对人类偏好的简化假设。这些假设可能无法准确捕捉真实世界人类判断的复杂性和可变性,导致奖励模型与实际人类偏好之间存在偏差,进而影响最终语言模型的性能。因此,如何提升RLHF算法在奖励模型存在偏差情况下的鲁棒性是一个关键问题。
核心思路:该论文的核心思路是通过降低奖励和策略估计器的方差来提高算法的鲁棒性。具体来说,该算法旨在减少由于奖励模型的不准确性而导致的策略学习过程中的不确定性,从而使模型能够更稳定地学习到符合人类偏好的策略。通过减少方差,算法能够更好地应对奖励模型中的噪声和偏差,从而提高整体性能。
技术框架:该论文提出的算法框架建立在现有的RLHF流程之上,主要包括以下几个阶段:1) 数据收集:收集人类对不同模型输出的偏好数据。2) 奖励模型训练:使用收集到的数据训练奖励模型,该模型用于预测人类对不同输出的偏好。3) 策略优化:使用强化学习算法,如PPO,根据奖励模型的反馈来优化语言模型的策略。论文提出的鲁棒算法主要改进了策略优化阶段,通过引入方差降低机制来提高策略学习的稳定性。
关键创新:该论文的关键创新在于提出了一种鲁棒的策略优化算法,该算法能够有效降低奖励和策略估计器的方差。与现有方法相比,该算法对奖励模型的错误指定具有更强的鲁棒性,能够在奖励模型存在偏差的情况下,更稳定地学习到符合人类偏好的策略。这种鲁棒性是通过在策略优化过程中引入额外的正则化项或修改损失函数来实现的,从而减少策略更新的幅度,避免过度拟合奖励模型中的噪声。
关键设计:具体的算法设计细节(例如,正则化项的具体形式、损失函数的修改方式)在论文中没有详细说明,属于未知信息。但是,可以推断,关键设计可能包括:1) 设计合适的正则化项,以惩罚策略更新过程中的大幅度变化。2) 修改损失函数,使其对奖励模型中的噪声更加不敏感。3) 调整强化学习算法中的超参数,以平衡探索和利用,避免过度依赖不准确的奖励信号。
🖼️ 关键图片


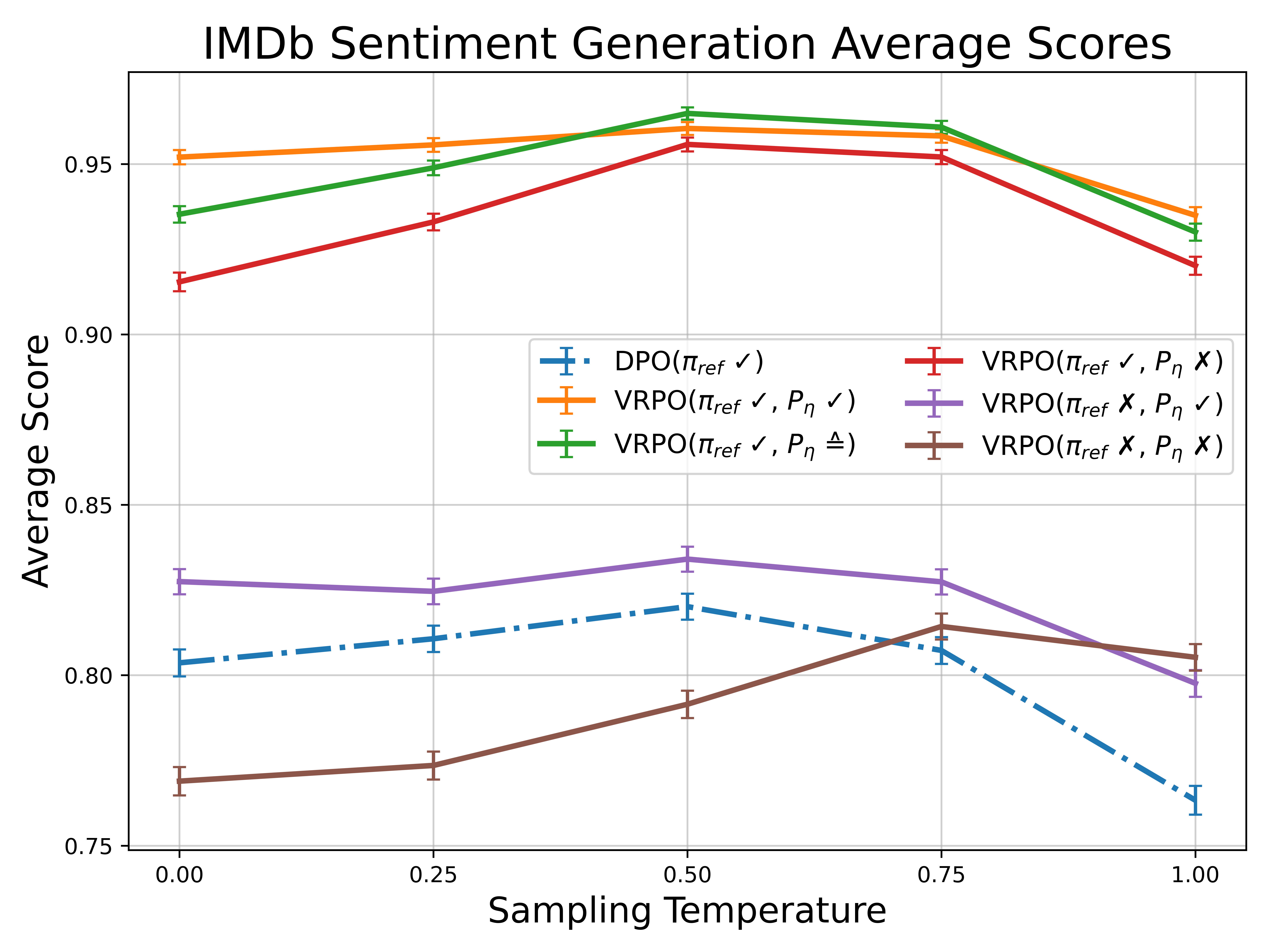
📊 实验亮点
实验结果表明,该算法在LLM基准数据集上始终优于现有方法。在Anthropic Helpful and Harmless数据集上,有77-81%的响应被认为优于基线方法。这些结果表明,该算法能够有效提高语言模型与人类偏好的一致性,并提升模型的整体性能。
🎯 应用场景
该研究成果可广泛应用于各种需要通过人类反馈来对齐大型语言模型的场景,例如对话系统、文本生成、代码生成等。通过提高RLHF算法的鲁棒性,可以减少对高质量人工标注数据的依赖,降低模型训练成本,并提升模型在实际应用中的性能和可靠性。该方法还有潜力应用于其他机器学习领域,例如机器人控制和推荐系统。
📄 摘要(原文)
Reinforcement learning from human feedback (RLHF) has emerged as a key technique for aligning the output of large language models (LLMs) with human preferences. To learn the reward function, most existing RLHF algorithms use the Bradley-Terry model, which relies on assumptions about human preferences that may not reflect the complexity and variability of real-world judgments. In this paper, we propose a robust algorithm to enhance the performance of existing approaches under such reward model misspecifications. Theoretically, our algorithm reduces the variance of reward and policy estimators, leading to improved regret bounds. Empirical evaluations on LLM benchmark datasets demonstrate that the proposed algorithm consistently outperforms existing methods, with 77-81% of responses being favored over baselines on the Anthropic Helpful and Harmless dataset. The code is available at https:// github.com/ VRPO/ VRPO.