BOOST: Bootstrapping Strategy-Driven Reasoning Programs for Program-Guided Fact-Checking
作者: Qisheng Hu, Quanyu Long, Wenya Wang
分类: cs.AI
发布日期: 2025-04-03 (更新: 2025-08-01)
备注: Work in Progress
💡 一句话要点
BOOST:提出一种自举策略驱动的推理程序,用于程序引导的事实核查。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 程序引导推理 自举学习 元规则学习 少量样本学习
📋 核心要点
- 现有事实核查方法依赖人工标注的少量样本演示,成本高昂且缺乏对推理程序生成原理的深入理解。
- BOOST通过自举方式自动生成少量样本推理程序,迭代优化数据驱动的元规则,无需人工干预。
- 实验表明,BOOST在零样本和少量样本设置下,均优于现有少量样本基线,提升了复杂声明验证的性能。
📝 摘要(中文)
大型语言模型流水线改进了复杂声明的自动事实核查,但许多方法依赖于少量样本的上下文学习,而这些演示需要大量的人工努力和领域专业知识。其中,程序引导的推理通过将声明分解为函数调用并执行推理程序,显示出特别的希望,但仍然受到手动制作演示需求的限制。有效推理程序生成的基本原则仍未得到充分探索。本文介绍了一种用于自动少量样本推理程序生成的自举方法BOOST。BOOST迭代地细化显式的、数据驱动的指导原则,作为指导演示创建的元规则,使用消除人工干预的评论-改进循环。这使得从零样本到少量样本程序引导学习的无缝过渡,增强了解释性和有效性。实验结果表明,在复杂声明验证的零样本和少量样本设置中,BOOST优于先前的少量样本基线。
🔬 方法详解
问题定义:论文旨在解决复杂声明的事实核查问题。现有方法,特别是程序引导的推理方法,依赖于人工构建的少量样本演示,这需要大量的人工工作和领域专业知识,并且缺乏对有效推理程序生成原则的深入理解。因此,如何自动生成高质量的推理程序演示,降低人工成本,是本文要解决的核心问题。
核心思路:BOOST的核心思路是利用自举(bootstrapping)方法,迭代地改进用于指导推理程序演示生成的元规则。通过一个评论-改进循环,系统自动评估生成的演示质量,并根据评估结果调整元规则,从而逐步提高演示的质量,最终实现无需人工干预的少量样本推理程序生成。
技术框架:BOOST包含以下主要模块:1) 元规则生成器:负责生成初始的元规则,用于指导推理程序的生成。2) 推理程序生成器:根据当前的元规则,生成推理程序演示。3) 评估器:评估生成的推理程序演示的质量。4) 元规则改进器:根据评估结果,改进元规则,使其能够生成更高质量的推理程序演示。整个流程是一个迭代的过程,通过不断地评估和改进,最终得到一组能够有效指导推理程序生成的元规则。
关键创新:BOOST的关键创新在于其自举式的元规则学习方法。与传统方法依赖人工构建演示不同,BOOST通过自动化的方式学习如何生成高质量的演示,从而大大降低了人工成本。此外,BOOST还通过显式的元规则,增强了模型的可解释性。
关键设计:BOOST的具体实现细节未知,论文摘要中没有明确说明关键的参数设置、损失函数或网络结构等技术细节。但是,可以推断,评估器可能使用某种形式的奖励函数来衡量生成的推理程序演示的质量,而元规则改进器可能使用某种优化算法来调整元规则。
🖼️ 关键图片

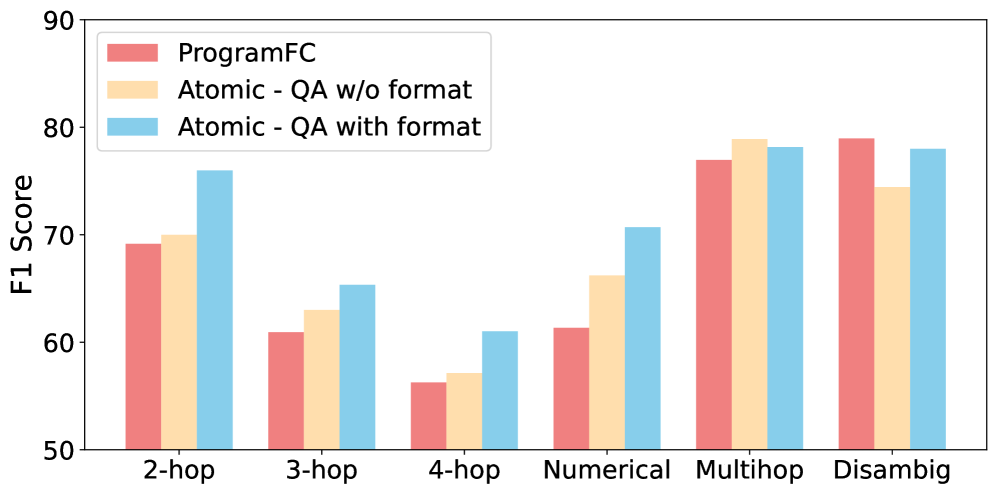
📊 实验亮点
实验结果表明,BOOST在复杂声明验证的零样本和少量样本设置中,均优于先前的少量样本基线。这表明BOOST能够有效地自动生成高质量的推理程序演示,从而提高事实核查的准确性和效率。具体的性能数据和提升幅度在摘要中没有给出,需要查阅论文全文。
🎯 应用场景
BOOST可应用于各种需要事实核查的场景,例如新闻验证、科学研究验证、金融报告验证等。通过降低人工标注成本,BOOST可以促进自动事实核查技术在更广泛领域的应用,提高信息的可信度和可靠性,并减少虚假信息的传播。
📄 摘要(原文)
Large language model pipelines have improved automated fact-checking for complex claims, yet many approaches rely on few-shot in-context learning with demonstrations that require substantial human effort and domain expertise. Among these, program-guided reasoning, by decomposing claims into function calls and executing reasoning programs, which has shown particular promise, but remains limited by the need for manually crafted demonstrations. Fundamentally, the underlying principles of effective reasoning program generation still remain underexplored. In this work, we introduce BOOST, a bootstrapping approach for automated few-shot reasoning program generation. BOOST iteratively refines explicit, data-driven guidelines as meta-rules for guiding demonstration creation, using a critique-refine loop that eliminates the need for human intervention. This enables a seamless transition from zero-shot to few-shot program-guided learning, enhancing interpretability and effectiveness. Experimental results show that BOOST outperforms prior few-shot baselines in both zero-shot and few-shot settings for complex claim verification.