LLM Social Simulations Are a Promising Research Method
作者: Jacy Reese Anthis, Ryan Liu, Sean M. Richardson, Austin C. Kozlowski, Bernard Koch, James Evans, Erik Brynjolfsson, Michael Bernstein
分类: cs.HC, cs.AI, cs.CL, cs.CY
发布日期: 2025-04-03 (更新: 2025-06-05)
备注: Published at ICML 2025
💡 一句话要点
利用LLM进行社会模拟是一种有前景的研究方法,但面临可控的挑战。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会模拟 行为建模 提示工程 微调 社会科学 人工智能 实验研究
📋 核心要点
- 现有方法在利用LLM进行社会模拟时,数据质量和可信度不足,阻碍了其广泛应用。
- 论文提出通过富含上下文的提示工程和社会科学数据集微调等方法,提升LLM社会模拟的准确性和可靠性。
- 研究表明,LLM社会模拟已可用于初步研究,并有望随着技术进步实现更广泛的应用。
📝 摘要(中文)
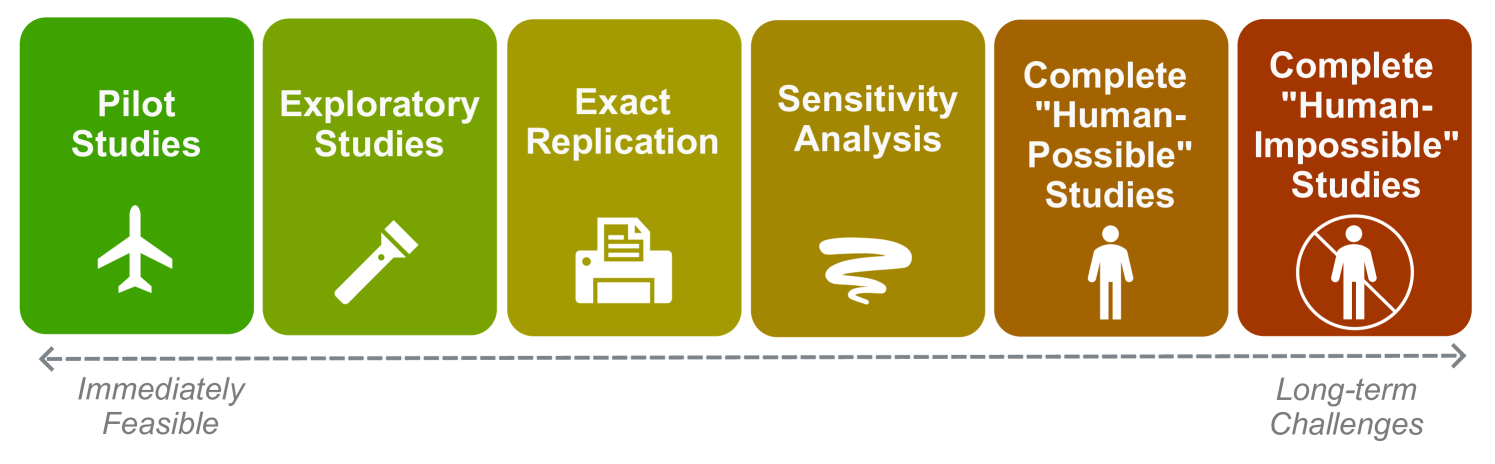
对人类研究对象进行准确且可验证的大型语言模型(LLM)模拟,有望成为理解人类行为和训练新AI系统的一种易于获取的数据来源。然而,迄今为止的结果有限,且很少有社会科学家采用这种方法。在这篇立场文件中,我们认为,通过应对五个可控的挑战,可以实现LLM社会模拟的承诺。我们的论点基于对LLM与人类研究对象之间的实证比较、相关评论和相关工作的回顾。我们确定了有希望的方向,包括富含上下文的提示和使用社会科学数据集进行微调。我们认为,LLM社会模拟已经可以用于试点和探索性研究,并且随着LLM能力的快速发展,更广泛的应用可能很快成为可能。研究人员应优先开发概念模型和迭代评估,以充分利用新的AI系统。
🔬 方法详解
问题定义:论文旨在解决社会科学研究中获取人类行为数据困难的问题。传统方法如问卷调查、实验等成本高昂且耗时,而现有LLM社会模拟的准确性和可信度不足,无法有效替代传统方法。痛点在于如何提升LLM模拟人类行为的真实性和可靠性,使其能够为社会科学研究提供有价值的数据支撑。
核心思路:论文的核心思路是,通过改进LLM的提示方式和训练数据,使其更好地理解人类行为的复杂性和多样性。具体而言,通过提供更丰富的上下文信息,引导LLM生成更符合实际情况的回复;同时,利用社会科学领域的数据集对LLM进行微调,使其更好地学习人类行为的模式和规律。
技术框架:论文并未提出一个具体的、全新的技术框架,而更多的是一种方法论上的建议。其核心在于利用现有的LLM技术,结合社会科学的研究需求,通过以下步骤进行社会模拟:1. 设计实验或调查场景;2. 构建包含丰富上下文信息的提示;3. 使用社会科学数据集对LLM进行微调;4. 对LLM的输出结果进行评估和验证;5. 迭代优化提示和微调策略。
关键创新:论文的创新之处在于强调了LLM社会模拟在社会科学研究中的潜力,并指出了实现这一潜力的关键挑战和可行方向。它并非提出了全新的技术,而是强调了如何更好地利用现有技术来解决社会科学研究中的实际问题。关键在于将LLM的强大能力与社会科学的理论和方法相结合,从而产生新的研究思路和方法。
关键设计:论文并未提供具体的参数设置、损失函数或网络结构等技术细节。其重点在于强调以下关键设计原则:1. 上下文丰富性:在提示中提供尽可能多的相关信息,例如人物背景、社会环境、历史事件等;2. 数据针对性:使用与研究问题相关的社会科学数据集进行微调,例如人口统计数据、行为调查数据、社交网络数据等;3. 评估迭代性:采用合适的评估指标(例如与真实人类行为的相似度、预测准确率等)对LLM的输出结果进行评估,并根据评估结果迭代优化提示和微调策略。
🖼️ 关键图片
📊 实验亮点
论文强调LLM社会模拟目前已可用于试点和探索性研究,并指出通过改进提示工程和使用社会科学数据集进行微调,可以显著提升LLM模拟的准确性和可靠性。虽然论文没有提供具体的性能数据,但强调了迭代评估的重要性,并认为随着LLM技术的快速发展,更广泛的应用指日可待。
🎯 应用场景
该研究的潜在应用领域包括社会心理学、经济学、政治学等。通过LLM社会模拟,研究人员可以更高效地进行实验和调查,探索人类行为的复杂机制,预测社会趋势,并为政策制定提供参考。此外,该方法还可以用于训练AI系统,使其更好地理解人类行为和社会规范,从而更好地与人类协作。
📄 摘要(原文)
Accurate and verifiable large language model (LLM) simulations of human research subjects promise an accessible data source for understanding human behavior and training new AI systems. However, results to date have been limited, and few social scientists have adopted this method. In this position paper, we argue that the promise of LLM social simulations can be achieved by addressing five tractable challenges. We ground our argument in a review of empirical comparisons between LLMs and human research subjects, commentaries on the topic, and related work. We identify promising directions, including context-rich prompting and fine-tuning with social science datasets. We believe that LLM social simulations can already be used for pilot and exploratory studies, and more widespread use may soon be possible with rapidly advancing LLM capabilities. Researchers should prioritize developing conceptual models and iterative evaluations to make the best use of new AI systems.