An Illusion of Progress? Assessing the Current State of Web Agents
作者: Tianci Xue, Weijian Qi, Tianneng Shi, Chan Hee Song, Boyu Gou, Dawn Song, Huan Sun, Yu Su
分类: cs.AI, cs.CL
发布日期: 2025-04-02 (更新: 2025-10-08)
备注: 22 pages, 17 figures, 7 tables
期刊: COLM 2025
💡 一句话要点
提出Online-Mind2Web在线评测基准,揭示Web Agent现有能力与预期差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Web Agent 大型语言模型 在线评估 自动化评估 基准测试 LLM-as-a-Judge 人机交互 任务自动化
📋 核心要点
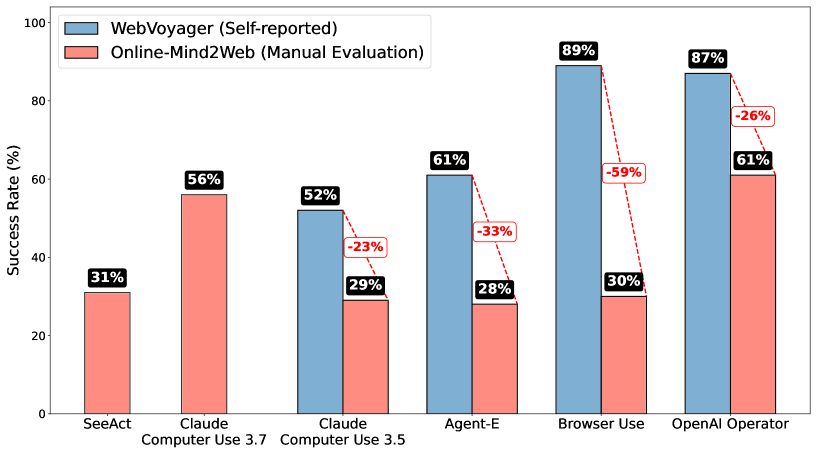
- 现有Web Agent评测基准存在不足,导致对Agent能力的评估过于乐观,未能反映真实用户场景。
- 提出Online-Mind2Web在线评测基准,包含更真实、多样化的Task,模拟真实用户使用Agent的方式。
- 开发LLM-as-a-Judge自动评估方法,与人工判断的一致性达到85%,提升了评估效率和可扩展性。
📝 摘要(中文)
随着数字化和云技术的演进,Web在现代社会中变得日益重要。基于大型语言模型(LLM)的自主Web Agent在工作自动化方面具有巨大潜力。因此,准确衡量和监控它们的能力进展至关重要。本文对当前Web Agent的状态进行了全面而严格的评估。结果表明,当前Agent的能力与先前报告的结果存在很大差距,表明先前结果过于乐观。这种差距可归因于现有基准的不足。我们引入了Online-Mind2Web,这是一个在线评估基准,包含136个网站上的300个多样化且真实的Task。它使我们能够在近似真实用户使用这些Agent的设置下评估Web Agent。为了促进更可扩展的评估和开发,我们还开发了一种新颖的LLM-as-a-Judge自动评估方法,并表明它可以达到约85%的人工判断一致性,远高于现有方法。最后,我们对当前的Web Agent进行了首次全面的比较分析,突出了它们的优势和局限性,以激发未来的研究。
🔬 方法详解
问题定义:现有Web Agent的评估基准存在局限性,无法准确反映Agent在真实Web环境中的能力。之前的研究结果可能过于乐观,未能充分考虑真实用户场景的多样性和复杂性。因此,需要一个更具代表性和挑战性的评估基准,以更准确地衡量Web Agent的性能。
核心思路:论文的核心思路是构建一个更贴近真实用户使用场景的在线评估基准,并开发一种高效的自动评估方法。通过引入多样化的Task和网站,以及模拟真实用户的交互方式,可以更全面地评估Web Agent的能力。同时,利用LLM作为裁判,可以降低人工评估的成本,提高评估效率。
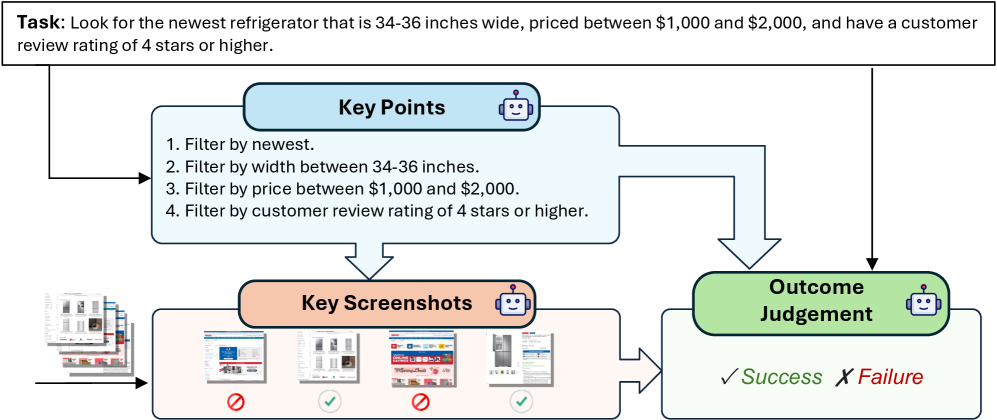
技术框架:该研究的技术框架主要包含两个部分:Online-Mind2Web在线评估基准和LLM-as-a-Judge自动评估方法。Online-Mind2Web基准包含300个Task,涵盖136个网站,模拟真实用户的Web浏览和操作行为。LLM-as-a-Judge方法利用大型语言模型对Agent的输出进行评估,并与人工判断进行对比,以验证其有效性。
关键创新:该研究的关键创新点在于提出了Online-Mind2Web在线评估基准和LLM-as-a-Judge自动评估方法。Online-Mind2Web基准更贴近真实用户场景,能够更准确地评估Web Agent的能力。LLM-as-a-Judge方法利用LLM进行自动评估,大大提高了评估效率和可扩展性,降低了人工成本。
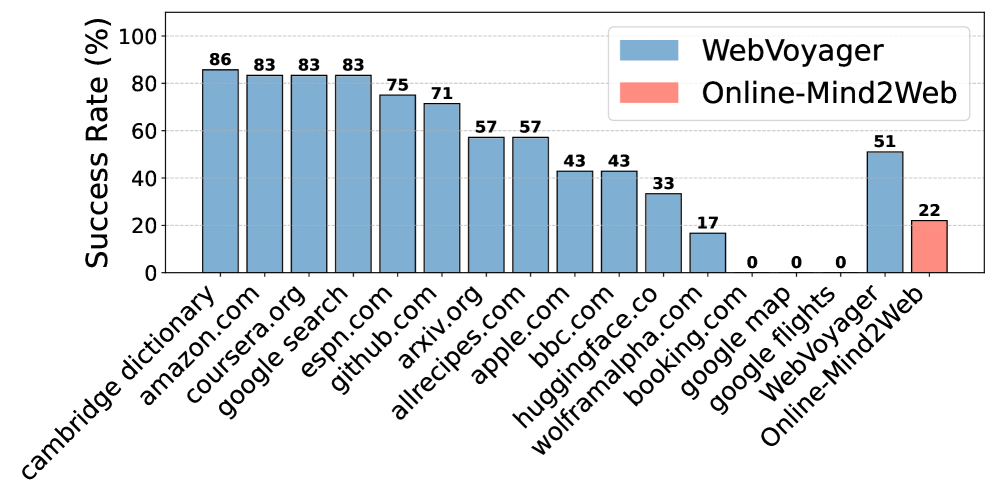
关键设计:Online-Mind2Web基准的关键设计在于Task的多样性和真实性,涵盖了各种常见的Web操作,如搜索、浏览、填写表单等。LLM-as-a-Judge方法的关键设计在于Prompt的设计,需要设计合适的Prompt,使得LLM能够准确地评估Agent的输出,并与人工判断保持一致。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有Web Agent在Online-Mind2Web基准上的表现远低于预期,揭示了现有评估方法的局限性。同时,LLM-as-a-Judge方法与人工判断的一致性达到85%,显著高于现有自动评估方法,验证了其有效性。该研究还对现有Web Agent进行了全面的比较分析,指出了它们的优势和不足。
🎯 应用场景
该研究成果可应用于Web Agent的开发和评估,帮助研究人员和开发者更准确地了解Agent的能力,并有针对性地进行改进。同时,Online-Mind2Web基准和LLM-as-a-Judge方法可以促进Web Agent的标准化评估,推动该领域的发展。未来,该研究可以扩展到更复杂的Web任务和Agent类型,为实现更智能、更自主的Web Agent奠定基础。
📄 摘要(原文)
As digitalization and cloud technologies evolve, the web is becoming increasingly important in the modern society. Autonomous web agents based on large language models (LLMs) hold a great potential in work automation. It is therefore important to accurately measure and monitor the progression of their capabilities. In this work, we conduct a comprehensive and rigorous assessment of the current state of web agents. Our results depict a very different picture of the competency of current agents, suggesting over-optimism in previously reported results. This gap can be attributed to shortcomings in existing benchmarks. We introduce Online-Mind2Web, an online evaluation benchmark consisting of 300 diverse and realistic tasks spanning 136 websites. It enables us to evaluate web agents under a setting that approximates how real users use these agents. To facilitate more scalable evaluation and development, we also develop a novel LLM-as-a-Judge automatic evaluation method and show that it can achieve around 85% agreement with human judgment, substantially higher than existing methods. Finally, we present the first comprehensive comparative analysis of current web agents, highlighting both their strengths and limitations to inspire future research.